计算机视觉可以解决的问题:
- 图片分类
- 物体检测
- 图片风格迁移
padding操作的作用:
- 保证输出大小:不用padding时,feature map会越来越小
- 防止边缘信息被逐步遗忘,因为边缘网格信息只经历少数卷积,而中间网格信息可多次通过卷积进行保存。
卷积时输入输出的尺寸计算:
卷积网络对比全连接神经网络的优势:
参数共享和稀疏连接。稀疏连接大概意思就是一个feature map的网格值与输入的一个区域有关,在区域外的输入相当于权重为0,这和局部连接差不多概念。
各经典网络回顾
LeNet-5
当时没有使用padding操作,使用的激活函数为sigmoid和tanh,使用的池化为平均池化。网络结构细节如下:
- 输入 的灰度图片;
- 使用大小为 ,步幅为 的卷积核,此时feature map大小为 ;使用大小为 ,步幅为 的平均池化,此时feature map大小为 ;
- 使用大小为 ,步幅为 的卷积核,此时feature map大小为 ;使用大小为 ,步幅为 的平均池化,此时feature map大小为 ;
- 将feature map铺平,则变为400*1的向量;以下全连接层大小依次为120、84、10;
AlexNet
AlexNet在模型结构上,与LeNet-5不同的地方在于:1) 使用了Relu激活函数;2) 使用了same padding(卷积后输入尺寸和输出尺寸相同的padding);3) 使用最大池化;
AlexNet在模型训练上,增强的地方在于:1) 使用dropout=0.5的操作; 2) 使用了数据增强操作(平移,偏转,区域取块)
网络结构细节如下:
- 输入为 ;
- 使用96个大小为 ,步幅为 的卷积核,此时feature map大小为 ;使用大小为 ,步幅为 的最大池化,此时feature map大小为 ;
- 使用256个大小为 ,填充方式为same padding的卷积核,此时feature map大小为 ;使用大小为 ,步幅为 的最大池化,此时feature map大小为 ;
- 1)使用384个大小为 ,填充方式为same padding的卷积核,此时feature map大小为 ;2)使用384个大小为 ,填充方式为same padding的卷积核,此时feature map大小为 ;3)使用256个大小为 ,填充方式为same padding的卷积核,此时feature map大小为 ;使用大小为 ,步幅为 的最大池化,此时feature map大小为 ;
- 将 的feature map平展为9216*1的向量,以下全连接层大小依次为4096、4096、1000。
VGGNet
该网络和之前网络最大的不同在于,VGGNet没有那么多的超参数(卷积核,步幅等),是专注于构建卷积层的简单网络,其将卷积核大小固定为 ,卷积步幅固定为 ,填充形式为same padding。池化层的大小固定为 ,步长固定为 。该网络的关键是每一层卷积核的数量。该网络的提出,简化了神经网络结构。
ResNet
在引入残差块之前,理论上网络越深其训练误差会越来越低,但由于梯度消失和梯度爆炸的存在,在网络达到一定深度后,优化算法对网络参数更新的
效果不明显,导致其训练误差反而上升。残差块的核心思想是引入一个“身份捷径连接”(identity shortcut connection),跳过一层或多层,使得梯度和特征信息更好传播。
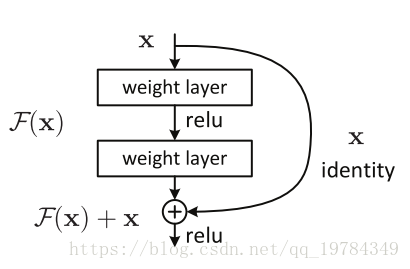
其参数大致是如此传递的 ,下一层是接收跳跃信息的: ,就是在 Relu 操作前添加了上上层传递来的信息。
ResNet 为什么有效?
假设一个网络模型有100层,在某训练集上其70层就能达到效果,那么后面30层就是在学习一个恒等函数。ResNet网络在学习恒等函数时拥有很大的优势,即最后几层的 和 都等于零,则 。而传统卷机网络学习
1*1卷积的作用
- 压缩信道量(channels),减少计算
- 给网络添加非线性元素
Inception网络
Inception网络的基本思想是不需要人为考虑使用哪个过滤器(尺寸),或是否使用池化等,只需要让网络自己确定。Inception将不同尺寸的过滤器的结果组合起来,让网络自由选择使用哪些过滤器,其代价是增加了计算量(使用1*1的卷积,可以减少计算量,比如原先过滤器是32个5*5*192,通过1*1的卷积,过滤器前的输入可以变成28*28*16,则过滤器变成32个5*5*16),但释放了内存。
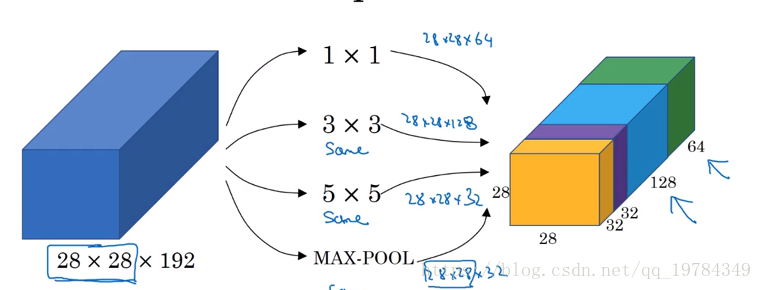
这些过滤器都使用same的卷积方式,保证其输出是相等长、宽的(包括最大池也使用了填充,其步幅为1)。