序列数据及能做的事
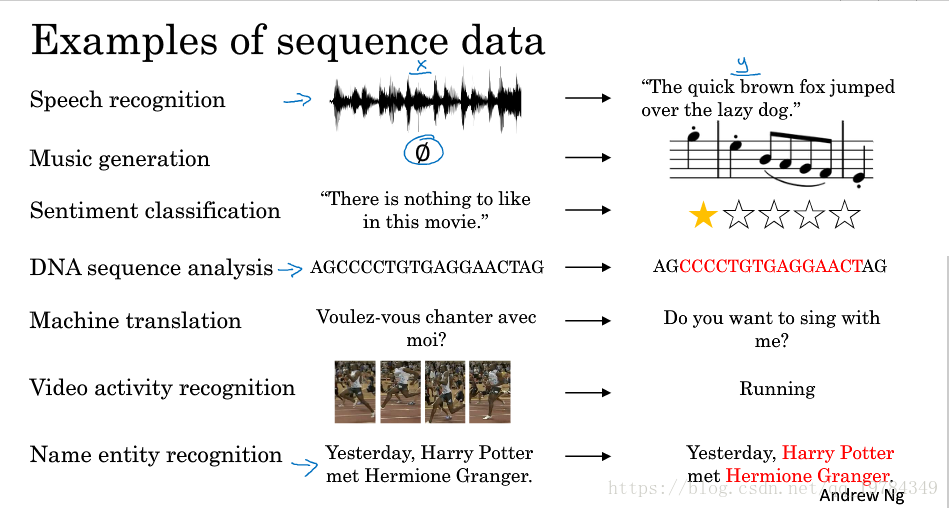
- 语音识别:一维时间序列 文本序列
- 音乐生成器:输入为空 音乐
- 情感分类器:文本序列 星级评分(0~5)/正负类(0/1)
- DNA序列分析:字符序列 字符序列
- 翻译系统:文本序列 文本序列
- 视频标识(视频活动识别):视频 类别
- (名字)身份识别:文本序列 文本序列
如果输入是文本序列,则处理数据的方式是对单词建立词典并向量化每个单词(one-hot编码)。若单词在词库中不存在,则可用表示。
为什么不用传统网络处理序列数据?
- 输入输出长度不固定(及时可用填充成一样的,那也表现的不是很好)【参数共享可用解决】
- 第一层参数过大(输入为字典向量,假设词库有1W个单词,那也有成百上千万个参数)
梯度爆炸和梯度消失
梯度爆炸可通过梯度修剪解决,就是如果数值过大,则缩小,实验表明该操作具有一定鲁棒性;而梯度消失相对难解决的多,所以很多策略都是用于解决梯度消失的。
RNN
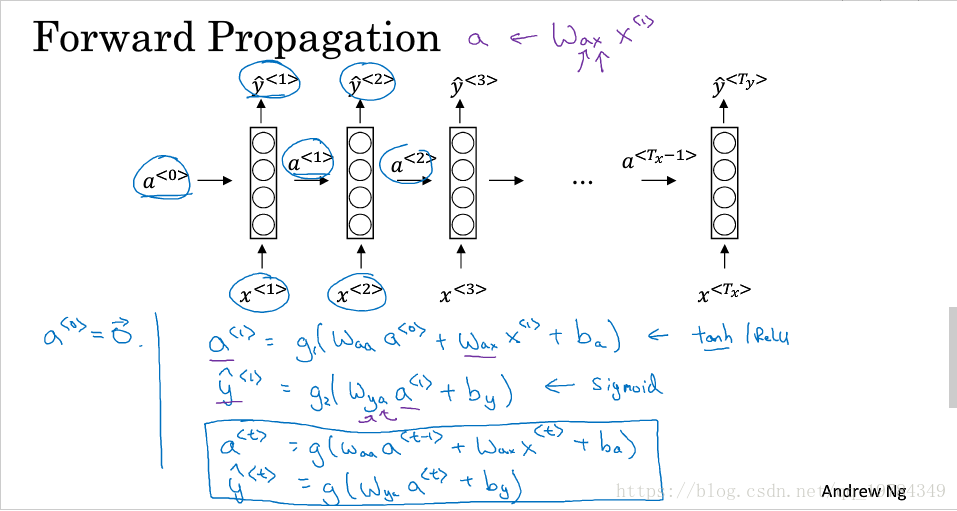
更新公式:
为了书写方便,有以下定义:
RNN结构类型
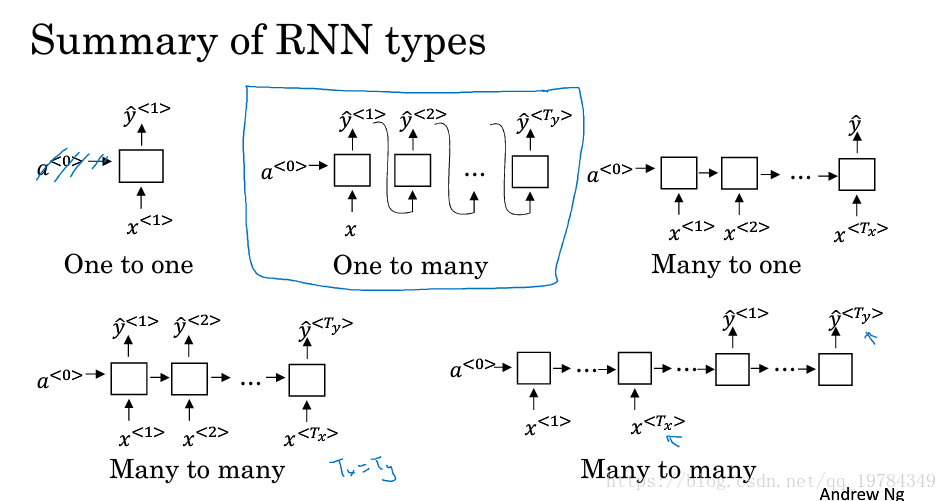
单向RNN的一个缺点:
网络只使用了序列之前的信息,没综合后面的信息(如只使用单向网络,不能确定一个单词是人名的一部分还是地名的一部分)
双向RNN(BRNN)
双向RNN可以获取双向的信息,即过去和未来的信息。
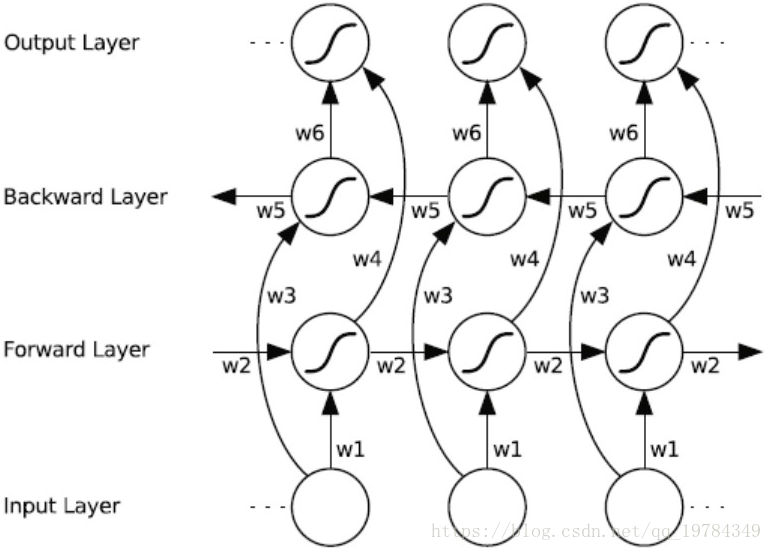
就是输出的时候,综合了前向传播网络的输出和后向传播网络的输出。
BRNN的缺点是需要完整的数据的序列,才能预测任意位置(相较之前只需要前面信息)。例如,语音系统需要你说完话才能工作。
GRU(Gate Recurrent Unit)
GRU(门循环单元)改变了RNN的隐藏单元,使其可以更好地捕捉深层连接,并改善了梯度消失问题(通过改变更新的力度,相当于可以更好地丢掉无用的)。以下展示了门的作用:控制细胞状态更新与否,更新力度。
变量
代表细胞,即记忆细胞,
。记忆细胞的作用是提供了记忆的功能(比如猫是单数还是双数)。细胞想要更新的值(候选值)为【需要理解的是,这个单元的
】:
LSTM(long-short time memory,长短时记忆)
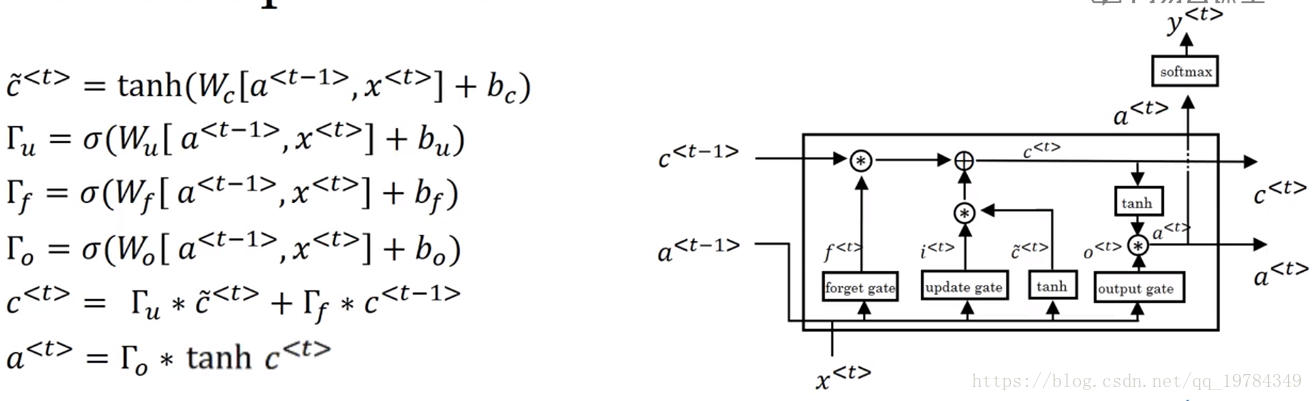
其中, 是控制更新的门, 是控制忘记的门, 是控制遗忘的门, 是细胞状态更新的候选值, 是细胞状态, 是前后信息的激活值。大概 用于保存前后记忆( 短时记忆),便于“联想”, 用于保存历史记忆的重要信息( 长时记忆)