基于Tensorflow平台的2D FCN图像分割学习
1.基础知识准备
1.1网络构建相关的函数准备
tf.nn.conv2d(input, filter, strides, padding, use_cudnn_on_gpu=None, name=None)
参数
input:指需要做卷积的输入图像,它要求是一个Tensor,具有[batch, in_height, in_width, in_channels]这样的shape,注意这是一个4维的Tensor,要求类型为float32和float64其中之一
filter:相当于CNN中的卷积核,它要求是一个Tensor,具有[filter_height, filter_width, in_channels, out_channels]这样的shape,
求类型与参数input相同,有一个地方需要注意,第三维in_channels,就是参数input的第四维
strides:卷积时在图像每一维的步长,这是一个一维的向量,[1, stride, stride, 1]长度4
padding:string类型的量,只能是"SAME","VALID"其中之一,这个值决定了不同的卷积方式
use_cudnn_on_gpu:bool类型,是否使用cudnn加速,默认为true
结果返回一个Tensor,这个输出,就是我们常说的feature map, 在padding 为"SAME"的情况下[batch, in_height, in_width, out_channels]
tf.conv2d_transpose(value, filter, output_shape, strides, padding="SAME", data_format="NHWC", name=None)
参数
value:指需要做反卷积的输入图像,它要求是一个Tensor
filter:卷积核,它要求是一个Tensor,具有[filter_height, filter_width, out_channels, in_channels]这样的shape,
具体含义是[卷积核的高度,卷积核的宽度,卷积核个数,图像通道数]
output_shape:反卷积操作输出的shape,细心的同学会发现卷积操作是没有这个参数的.
strides:反卷积时在图像每一维的步长,这是一个一维的向量,长度4
padding:string类型的量,只能是"SAME","VALID"其中之一,这个值决定了不同的卷积方式
data_format:string类型的量,'NHWC'和'NCHW'其中之一,这是tensorflow新版本中新加的参数,它说明了value参数的数据格式。
'NHWC'指tensorflow标准的数据格式[batch, height, width, in_channels],
'NCHW'指Theano的数据格式,[batch, in_channels,height, width],当然默认值是'NHWC'
tf.add(x, y, name=None)
功能:是使x,和y两个参数的元素相加,返回的tensor数据类型和x的数据类型相同(参数想x, y的类型必须相同, Must be one of the following types:
`half`, `float32`, `float64`, `uint8`, `int8`, `int16`, `int32`, `int64`, `complex64`, `complex128`, `string`.)
tf.argmax(input, axis=None, name=None, dimension=None):
功能:返回的是vector中的最大值的索引号,如果vector是一个向量,那就返回一个值。如果是一个矩阵,那就返回一个向量,
这个向量的每一个维度都是相对应矩阵行的最大值元素的索引号。
tf.Variable.init(initial_value, trainable=True, collections=None, validate_shape=True, name=None)
参数:initial_value:变量的初始值,【必须的】如果为False,则不进行类型和维度检查
trainable: 如果为True,会把它加入到GraphKeys.TRAINABLE_VARIABLES,才能对它使用Optimizer
collection:指定该图变量的类型、默认为[GraphKeys.GLOBAL_VARIABLES]
validate_shape:
name:变量的名称,如果没有指定则系统会自动分配一个唯一的值
tf.get_variable跟tf.Variable都可以用来定义图变量,但是前者的必需参数(即第一个参数)并不是图变量的初始值,而是图变量的名称。
tf.Variable的用法要更丰富一点,当指定名称的图变量已经存在时表示获取它,当指定名称的图变量不存在时表示定义它。
scope如何划分命名空间
tf.variable_scope:当使用tf.get_variable定义变量时,如果出现同名的情况将会引起报错,而对于tf.Variable来说,却可以定义“同名”变量
tf.name_scope:当tf.get_variable遇上tf.name_scope,它定义的变量的最终完整名称将不受这个tf.name_scope的影响


In [1]: import tensorflow as tf In [2]: with tf.variable_scope('v_scope'): ...: with tf.name_scope('n_scope'): ...: x = tf.Variable([1], name='x') ...: y = tf.get_variable('x', shape=[1], dtype=tf.int32) ...: z = x + y ...: In [3]: x.name, y.name, z.name Out[3]: ('v_scope/n_scope/x:0', 'v_scope/x:0', 'v_scope/n_scope/add:0')
图表的复用(常在RNN中用到)
1.2 模型优化相关的函数
1.2.1 损失函数
(1)交叉熵(crossentropy)
给定两个概率分布p和q,交叉熵刻画的是两个概率分布之间的距离:
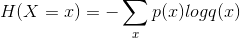
tf.nn.softmax_cross_entropy_with_logits(labels=y_, logits=y)
是TensorFlow提供的集成交叉熵函数。该操作应该施加在未经过Softmax处理的logits上,否则会产生错误结果;labels为期望输出,且必须采用labels=y_, logits=y3的形式将参数传入。
(1)这个操作的输入logits是未经缩放的,该操作内部会对logits使用softmax操作;
(2) 参数labels,logits必须有相同的形状 [batch_size, num_classes] 和相同的类型(float16, float32,float64)中的一种。
该函数具体的执行过程分两步:首先对logits做一个Softmax,

第二步就是将第一步的输出与样本的实际标签labels做一个交叉熵。

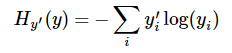
这个函数的返回值并不是一个数,而是一个向量,如果要求交叉熵,我们要再做一步tf.reduce_sum操作,就是对向量里面所有元素求和,最后才得到交叉熵,
如果求loss,则要做一步tf.reduce_mean操作,对向量求均值!
tf.nn.sparse_softmax_cross_entropy_with_logits(_sentinel=None, labels=None, logits=None, name=None)
功能:计算logits 和 labels 之间的稀疏softmax 交叉熵
参数:
1.2.2 优化器
https://blog.csdn.net/xierhacker/article/details/53174558
(1) class tf.train.GradientDescentOptimizer
__init__(learning_rate, use_locking=False,name=’GradientDescent’)
作用:创建一个梯度下降优化器对象
参数:
learning_rate: A Tensor or a floating point value. 要使用的学习率
use_locking: 要是True的话,就对于更新操作(update operations.)使用锁
name: 名字,可选,默认是”GradientDescent”.
compute_gradients(loss,var_list=None,gate_gradients=GATE_OP,aggregation_method=None,colocate_gradients_with_ops=False,grad_loss=None)
作用:对于在变量列表(var_list)中的变量计算对于损失函数的梯度,这个函数返回一个(梯度,变量)对的列表,其中梯度就是相对应变量的梯度了。这是minimize()函数的第一个部分,
参数:
loss: 待减小的值
var_list: 默认是在GraphKey.TRAINABLE_VARIABLES.
gate_gradients: How to gate the computation of gradients. Can be GATE_NONE, GATE_OP, or GATE_GRAPH.
aggregation_method: Specifies the method used to combine gradient terms. Valid values are defined in the class AggregationMethod.
colocate_gradients_with_ops: If True, try colocating gradients with the corresponding op.
grad_loss: Optional. A Tensor holding the gradient computed for loss.
apply_gradients(grads_and_vars,global_step=None,name=None)
作用:把梯度“应用”(Apply)到变量上面去。其实就是按照梯度下降的方式加到上面去。这是minimize()函数的第二个步骤。 返回一个应用的操作。
参数:
grads_and_vars: compute_gradients()函数返回的(gradient, variable)对的列表
global_step: Optional Variable to increment by one after the variables have been updated.
name: 可选,名字
minimize(loss,global_step=None,var_list=None, gate_gradients=GATE_OP, aggregation_method=None, colocate_gradients_with_ops=False, name=None, grad_loss=None)
作用:非常常用的一个函数 通过更新var_list来减小loss,这个函数就是前面compute_gradients() 和apply_gradients().的结合
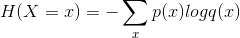
validate_shape