【火炉炼AI】机器学习005-多项式回归器的创建和测试
【本文所使用的Python库和版本号】: Python 3.5, Numpy 1.14, scikit-learn 0.19
前面讲到了简单线性回归器和岭回归器,这两类回归器都是将数据集拟合成直线,但现实生活中,有很多情况,数据集的分布并不是简单的线性关系,还有可能是曲线关系,聚类关系,随机分布关系等,对于这些不同的数据集分布关系,需要使用不同的回归器来拟合。
1. 分析数据集
由于缺少数据集,我自己用代码生成了一些数据,数据的生成过程和(【火炉炼AI】机器学习003-简单线性回归器的创建,测试,模型保存和加载)类似,如下代码所示。
# 构建服从多项式回归特性的数据集
np.random.seed(37) # 使得每次运行得到的随机数都一样
x=np.arange(2,102)
x_shift=np.random.normal(size=x.shape)
x=x+x_shift # 构建的x含有100个数,通过在整数点引入偏差得到
error=np.random.normal(size=x.shape)*800 # 构建噪音,*800是扩大噪音的影响
y=1.19*x*x+0.82*x+5.95+error
plt.scatter(x,y) # 可以查看生成的数据集的分布情况
dataset=[(i,j) for i,j in zip(x,y)]
from sklearn.model_selection import train_test_split
train_set,test_set=train_test_split(dataset,test_size=0.2,random_state=37)
X_train=np.array([i for (i,j) in train_set]).reshape(-1,1) # 后面的fit需要先reshape
y_train=np.array([j for (i,j) in train_set]).reshape(-1,1)
X_test= np.array([i for (i,j) in test_set]).reshape(-1,1)
y_test= np.array([j for (i,j) in test_set]).reshape(-1,1) 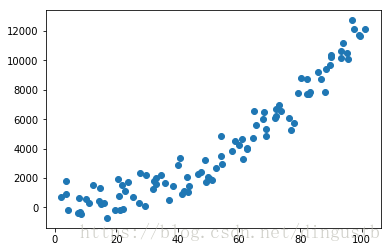
小结:
1,数据集的构建可以采用在标准数据中引入误差的方式。
2,在回归或分类模型中,经常要将数据集映射到二维平面上,通过散点图的方式来查看数据集的空间分布,有了直观的初步印象后,才能选择更合适的回归或分类模型。
2. 简单线性回归器模型拟合数据集
图中显示的数据集好像服从线性关系,也好像服从多项式关系,对于这样的情况,可以先用简单线性回归器拟合得到回归模型,然后用测试集看看该模型的优劣。如下代码:
# 如果采用简单线性回归器进行拟合得到简单的拟合直线
from sklearn import linear_model
linear_regressor=linear_model.LinearRegression() # 创建线性回归器对象
linear_regressor.fit(X_train,y_train) # 使用训练数据集训练该回归器对象
# 查看拟合结果
y_predict=linear_regressor.predict(X_train) # 使用训练后的回归器对象来拟合训练数据
plt.figure()
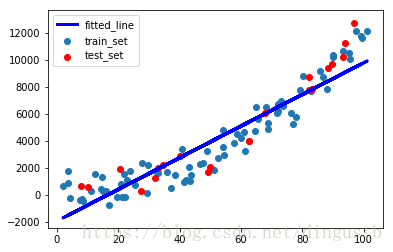
plt.scatter(X_train,y_train,label='train_set')
plt.scatter(X_test,y_test,color='r',label='test_set')
plt.plot(X_train,y_predict,'-b',linewidth=3,label='fitted_line')
plt.legend()
# 用测试集看看该线性回归器模型的测试结果
y_predict_test=linear_regressor.predict(X_test)
import sklearn.metrics as metrics
print('简单线性回归器模型的评测结果----->>>')
print('均方误差MSE:{}'.format(
round(metrics.mean_squared_error(y_predict_test,y_test),2)))
print('解释方差分:{}'.format(
round(metrics.explained_variance_score(y_predict_test,y_test),2)))
print('简单线性回归器得到的直线方程为:y={:.3f}x+{:.3f}'
.format(linear_regressor. coef_[0][0],linear_regressor. intercept_[0])) 简单线性回归器模型的评测结果----->>>
均方误差MSE:1906916.26
解释方差分:0.85
简单线性回归器得到的直线方程为:y=117.061x+-1924.904
小结:
1,使用简单线性回归器得到的模型在测试集上的MSE非常大,看来还有非常大的优化空间。
3. 采用多项式回归器
由于简单线性回归器模型在该数据集上的表现非常差,故而我们需要改进模型,所以尝试使用多项式回归器。
# 使用多项式回归器来对数据集进行拟合,得到多项式方程
from sklearn.preprocessing import PolynomialFeatures
polynomial=PolynomialFeatures(degree=2) # 构建多项式回归器对象
# degree是多项式的次数,此处初步的设置为2
X_train_transformed=polynomial.fit_transform(X_train)
# print(X_train_transformed) #transformed之后的数据是degree+1维
from sklearn import linear_model
poly_regressor=linear_model.LinearRegression() # 也是构建线性回归器
poly_regressor.fit(X_train_transformed,y_train) # 对多项式回归器进行训练
# 查看拟合结果
y_predict_polynomial=poly_regressor.predict(X_train_transformed)
plt.figure()
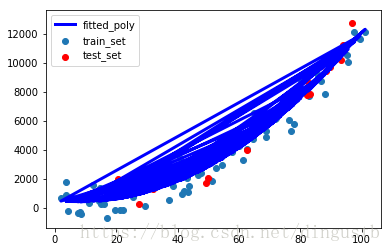
plt.scatter(X_train,y_train,label='train_set')
plt.scatter(X_test,y_test,color='r',label='test_set')
# print(y_predict_polynomial.shape) #(80, 1)
plt.plot(X_train,y_predict_polynomial,'-b',linewidth=3,label='fitted_poly')
# 上面的plot会产生很多条线。。。。。
plt.legend()
# 用测试集看看该线性回归器模型的测试结果
X_test_transformed=polynomial.fit_transform(X_test)
y_predict_test=poly_regressor.predict(X_test_transformed)
import sklearn.metrics as metrics
print('多项式回归器模型的评测结果----->>>')
print('均方误差MSE:{}'.format(
round(metrics.mean_squared_error(y_predict_test,y_test),2)))
print('解释方差分:{}'.format(
round(metrics.explained_variance_score(y_predict_test,y_test),2)))
print('得到的多项式方程为:y={:.3f}x^2+({:.3f}x)+{:.3f}'
.format(poly_regressor.coef_[0][-1],
poly_regressor.coef_[0][-2],
poly_regressor.intercept_[0]))
多项式回归器模型的评测结果----->>>
均方误差MSE:525885.05
解释方差分:0.97
得到的多项式方程为:y=1.374x^2+(-22.187x)+487.664
小结:
1,采用多项式回归器,首先需要将X特征向量经过fit_transform()函数转变到对应的维度,然后才能使用LinearRegression()对象的fit()进行训练。
2,虽然使用了多项式回归器进行拟合,但是得到的MSE仍然比较大,只是比线性回归器得到的MSE小一些而已。所以MSE这个指标是不是不靠谱?
3,从解释方差分上来看,多项式回归器对test set有了更大改进,数值为0.97.
4,图中线条比较多,是因为19行plt.plot(X_train,y_predict_polynomial)绘制了多次所导致,我暂时没有明白为什么会plot多个线条。。。。。
4. 对新数据进行预测
对于训练好的模型,不管是简单线性回归器还是稍复杂的多项式回归器,都要用来进行新数据的预测,下面我分别用这两个回归器预测一个新数据。
# 使用多项式回归器预测新的数据值
data_X=[[66]] # 需要计算的数据点 X值
print('用直线回归器得到的数值:{}'.format(linear_regressor.predict(data_X)))
print('用拟合直线计算的数值:{}'.format(
linear_regressor.coef_[0][0]*data_X[0][0]+linear_regressor.intercept_[0]))
data_X_transormed=polynomial.fit_transform(data_X)
data_X_predict=poly_regressor.predict(data_X_transormed)
# print(poly_regressor.coef_, '\n',poly_regressor.intercept_)
print('用多项式回归器得到的数值:{}'.format(data_X_predict))
print('用多项式曲线计算的数值:{}'.format(
poly_regressor.coef_[0][-1]*np.power(data_X[0][0],2)+
poly_regressor.coef_[0][-2]*data_X[0][0]+
poly_regressor.intercept_[0]))
# 两者数据相等,代表predict的确是按照这个曲线方程来计算的。 用直线回归器得到的数值:[[5801.09012059]]
用拟合直线计算的数值:5801.090120592645
用多项式回归器得到的数值:[[5010.58753529]]
用多项式曲线计算的数值:5010.587535291616
小结:
1,由于模型不同,对新数据进行预测,得到的结果也不同,但是由于多项式回归器模型对于test set的解释方差分要大一些,故而我们认为本例中多项式回归器模型更好一些,故而对新数据预测的结果更可靠一些。
2,如果某些数据集并不是服从简单的二项式,可以增加PolynomialFeatures(degree=2) 中degree的数值大小来提高x的最高次,得到的模型可能会更准确一些,但是要防止模型对train set的过拟合。
注:本部分代码已经全部上传到(我的github)上,欢迎下载。
参考:Python机器学习经典实例,Prateek Joshi著,陶俊杰,陈小莉译