一、信息量
信息奠基人香农(Shannon)认为“信息是用来消除随机不确定性的东西”。也就是说衡量信息量大小就看这个信息消除不确定性的程度。
“太阳从东方升起了”这条信息没有减少不确定性。因为太阳肯定从东面升起。这是句废话,信息量为0。
原则:
1、某事件发生的概率小,则该事件的信息量大;
2、如果两个事件X和Y独立,即,假定X和Y的信息量分别为
和
,则二者同时发生的信息量应该为:
定义随机变量X的概率分布为,从而定义X的信息量为:
二、熵
信息量度量的是一个具体事件发生所带来的信息,而熵则是在结果出来之前对可能产生的信息量的期望——考虑该随机变量的所有可能取值,即所有可能发生事件所带来的信息量的期望。
对于随机事件的信息量的期望,得到熵的定义:
注:典型熵的定义的底数为2,但本文为分析方便使用底数e。
两点分布的熵:
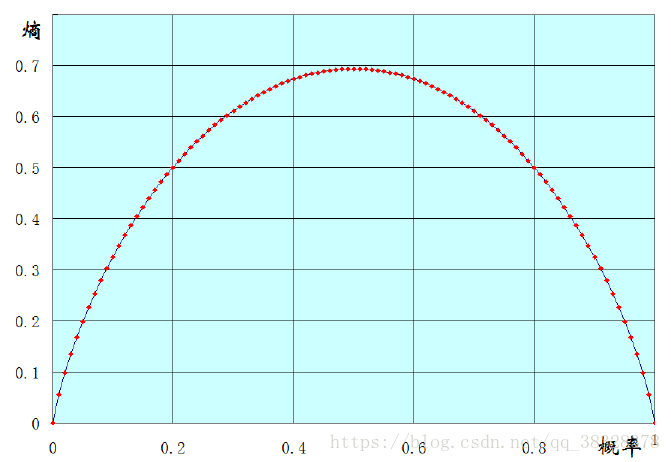
三点分布的熵:

公式推导:
因为可以知道
所以,代入上式得:

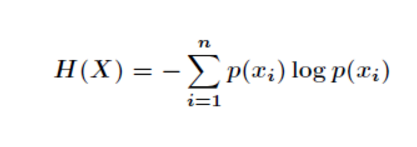 信息熵公式的特性
信息熵公式的特性
单调性,即发生概率越高的事件,其所携带的信息熵越低。极端案例就是“太阳从东方升起”,因为为确定事件,所以不携带任何信息量。从信息论的角度,认为这句话没有消除任何不确定性。非负性,即信息熵不能为负。这个很好理解,因为负的信息,即你得知了某个信息后,却增加了不确定性是不合逻辑的。累加性,即多随机事件同时发生存在的总不确定性的量度是可以表示为各事件不确定性的量度的和。
信息熵是用来衡量事物不确定性的。信息熵越大,事物越具不确定性,事物越复杂。
三、均匀分布信息熵
以离散分布为例:假定某离散分布可取N个值,概率都是,计算该概率分布的熵:
概率分布律:
计算熵:
四、最大熵的理解
无条件的最大熵分布
熵是随机变量不确定性的度量,不确定性越大,熵值越大;
1、若随机变量退化成定值,熵值最小,为零;
2、若随机变量为均匀分布,熵值最大,为;
有条件的最大熵分布
1、根据函数形式判断概率分布
正态分布的概率密度函数:
对数正态分布:
得出该分布的对数是关于随机变量的二次函数;
2、给定方差的最大熵分布
建立目标函数
使用方差公式化简约束条件
显然,此类问题为带约束的极值问题;
五、联合熵和条件熵
联合熵
两个随机变量X,Y的联合分布,可以形成联合熵Joint Entropy,用表示。
条件熵
(X,Y)发生所包含的熵,减去Y单独发生包含的熵:在Y发生的前提下,X发生“新”带来的熵。
条件熵的公式:
推导条件熵的定义式:
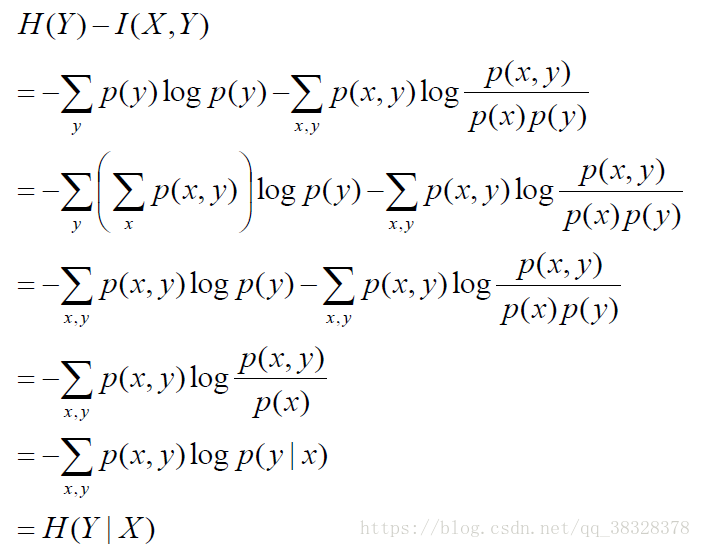
根据条件熵的定义式,得到:
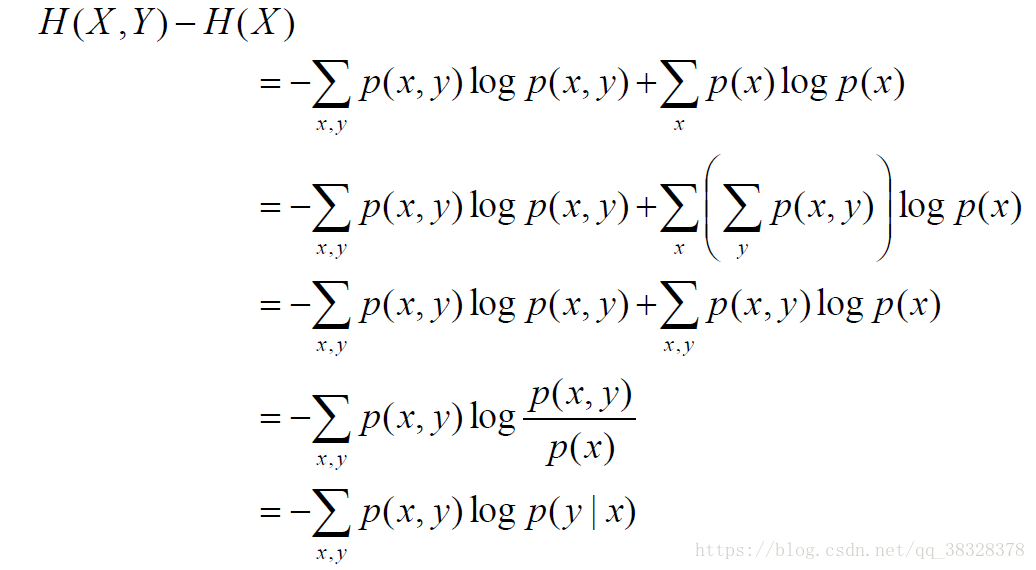
六、相对熵
相对熵,又称为互熵、交叉熵、鉴别信息、Kullback熵、Kullback-Leible散度等等;
设和
是
取值的两个概率分布,则
对
的相对熵为:
相对熵的性质:
1、相对熵可以度量两个随机变量的“距离”;
2、它不具有对称性,即 ,;
3、相对熵的值为非负值,即、
:凸函数中的Jensen不等式;
七、互信息(信息增益)
互信息的定义
两个随机变量X,Y的互信息,定义为X,Y的联合分布和独立分布乘积的相对熵:
条件熵与互信息的关系:
根据互信息定义展开得到:

八、总结
根据下面的Venn图,我们可以清楚的看到:
熵:对于随机事件X的信息量的期望;
熵:对于随机事件Y的信息量的期望;
联合熵:两个随机变量X,Y的联合分布;
条件熵:在Y发生的情况下,X的信息量;
条件熵:在X发生的情况下,Y的信息量;
互信息:两个随机变量X,Y的互信息;
