神经网络:Θ代表偏置,w代表权值。加权和f=∑OiWij; ① 输出层净输入等于输入的加权和加上偏置I3=O1W13+O2W23+Θ3 ②;输出层3的输出O3=1/1+e-I3;③;输出层误差用于测量样本的实际输出,神经网络根据预测输出和实际输出的误差来调节参数。Err3=O3(1-O3)(T3-O3)④;(T3代表实际输出,O3代表预测输出)对于隐藏层误差,从输出层开始,反向逐层传递输出层的误差,间接算出隐藏层误差(此时的Err3为隐藏层单层3的误差,Err4卫输出层单层4的误差)Err3=O3(1-O3)Err4W34⑤。权重偏置学习率,,,学习率l 能够动态调整模型学习的速度,取值为0-1。
W13=W13+(l)Err3O1; W23=W23+(l)Err3O2; Θ3=Θ3+(l)Err3;更新权值和偏置反应传播误差
实例分析模型流:

1. 首先输入训练样本数据,以及初始化权值和偏置,
2. 第一步单元4的净输入I4=O1W14+O2W24+O3W34+Θ4=0.3;单元4的输出O4=1/1+e-i4=0.57;
同理I5=0.7;O5=0.67; I6=O4W46+O5W56+Θ6=0.672; O6=1/1+e-i6=0.66.
3. 第二步:Err6=O61-O6)(T6-O6)=0.76,接下来反向传递误差,Err4=O4(1-O4)Err6W46=0.006;Err5=0.005;
4. 第三步:本例中I=0.8,根据Wij=Wij+(l)ErrjOj; Θj=Θj+(l)Errj。更新所有的权值w和偏置Θ。
神经网络模型:具有自适应不断调整参数的学习能力。利用权值存储信息。结合误差大小通过多次实例更新来获得神经网络的最新链接权值。
泛化能力:是指构建的模型对样本数据所隐含规律的接近程度。一般样本数据随机分为训练样本和测试样本,通过比较两个样本之间的误差大小的一致性程度来判断模型的泛化能力。
贝叶斯:
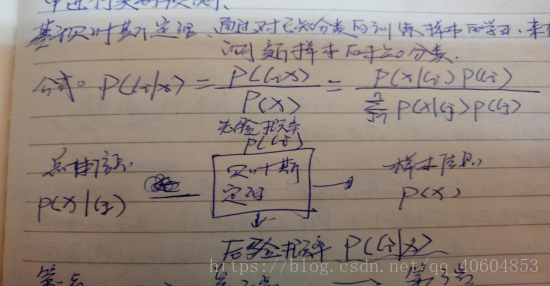
1. 预处理阶段:输入训练样本数据和特征属性,计算先验概率P(Ci).
2. 分类模型生成阶段,计算每个特征属性X的条件概率P(X|Ci),利用贝叶斯公式转化为后验概率P(Ci|X) 3.应用预测阶段,将待分类的新数据输入到分类模型中进行类别预测。
***根据贝叶斯公式计算后验概率P(Ci|X)时,通常P(X)对所有类别来说是常数,所以可以不考虑P(X)的值。P(Ci|X)=P(X|Ci)P(Ci)/P(X)。
对于事先已经确定的待分类新数据X,求出在X出现的条件下,各个分类C出现的概率,保留概率最大的类别作为X的分类结果,即需要计算每个分类类别Ci的后验概率P(Ci|X).。

1. 首先要获得属于结果类别的概率Pci,(Pci是样本属于类别Ci的概率,一般可用|Ci|/|S|来估计,S表示样本数据,|S|是样本总数10,C表示类标号属性,|Ci|表示属于各个类别的下的样本数。)PC1=|c1|/|s|=0.6,PC2=0.4 (C1表示购买汽车C2表示否)
2. ①类别C1下性别为男的概率P(X1|C1)=类C1下的男的样本数比上类别C1的样本数=4/6=0.67,同理类别C2下、、、、P(X1|C2)=1/4=0.25;②类别C1下为青年的的概率P(X2|C1)=类C1下青年的样本数比上类别C1的样本数=3/6=0.5同理类别C2下,,,P(X2|C2)=0.5
③类别C1下收入为高的概率P(X3|C1)=类C1下收入高的样本数比上类别C1的样本数=2/6=0.33,同理类别C2下、、、、P(X3|C2)=1/4=0.25④类别C1下未婚的概率P(X4|C1)=类C1下未婚的样本数比上类别C1的样本数=1/6=0.17,同理类别C2下、、、P(X4|C2)=0.5
3. P(C1)=0.6, P(c2)=0.4
P(X|C1)=∏p(Xk|c1)-----(k=1-4) P(X|C2)=∏p(Xk|c2)-----(k=1-4)
=0.67*0.5*0.33*0.17=0.019 =0.25*0.5*0.25*0.5=0.016;
P(C1|X)=0.019*0.6=0.0114 > P(C2|X)= 0.016*0.4=0.0064
所以表明新样本属于类别“是”的概率最大、
关联规则:p(b|a)/p(b)表示购买A商品项集的条件下,购买B商品项集的概率值(置信度)与没有任何前提条件的概率值之比。
置信度:(A->B)=包含AB的事物数比包含A的事物数=3/4=|AB|/|A|
支持度:=包含AB的事物数/总的事物数=3/4=|AB|/|S|;
提升度:=置信度/(包含B的事物数/总的事物数)=(3/4)/(3/4)=1 AB正相关则提升度>1
关联规则的生成主要基于频繁项集的两阶段的递推算法:1.找出所有满足最小支持度的频繁项集,2生成满足最小置信度的强关联规则。剪枝就是删除不满足最小支持度的项。
***关联规则(啤酒^面包->尿布)的置信度等于包含啤酒A面包C尿布B的事物数比上包含啤酒A和面包C的事物数为1
选取置信度大于0.8的规则计算提升度,提升度大于1说明规则是有用的。=1说明独立。
.关联规则(啤酒^面包->尿布)的提升度等于在购买啤酒面包的条件下,购买尿布B的概率值(置信度)与没有任何前提条件的概率值的比值,即置信度(A^c->B)/(包含B的事物数/总的事物数),结果4/3, 面包->啤酒^尿布 结果也一样。