第一章 绪论
1、填空题
(1)从技术层面上看,数据挖掘是( )。从商业层面看,数据挖掘是( )。
答:是从大量的、不完全的、有噪声的、模糊的、随机的实际应用数据中,提取隐含在其中、人们事先不知道的、但又潜在有用的信息的过程。
一种商业信息处理技术,其主要特点是对大量业务数据进行抽取、转换、分析和建模处理,从中提取辅助商业决策的关键性数据。
(2)数据挖掘所得到的信息具有( )、有效和实用三个特征。
答:先前未知。
2、数据挖掘在生活场景中的应用


3、区分数据挖掘和查询
数据挖掘和传统数据分析方法(如:查询、报表、联机应用分析等)有本质区别。数据挖掘是没有明确前提下去挖掘信息和 发现知识。
例:
在一句话中找出人名是数据挖掘,在表格中找出人民是查询
第二章 数据处理基础
1、填空题
(1)数据是( ),属性分为( )。
答:数据对象及其属性的集合;标称和序数属性、区间和比率属性。
2、计算题
(1)计算相似度量
老师给的范围:
距离度量(曼哈顿、欧式):

相似系数(余弦相似度):
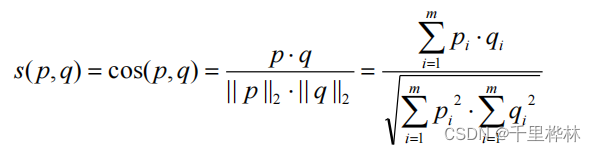
二值属性的相似性(简单匹配相似度关系数 d、s)
Jaccard系数:
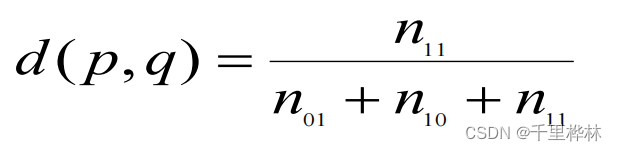
例题1:

答:

例题2:

答:


(2)数据统计特征计算
记公式:
算术平均数
加权算术均值
截断均值:丢弃高端和低端(p/2)%的数据,再算均值。
中位数
四分位数
中列数:(max+min)/2
众数

答:

3、问答题
(1)为什么要数据预处理?列出三种常用的预处理技术?
答:数据预处理的目的:提供干净、简洁、准确的数据,提高挖掘效率和准确性。
预处理技术:数据清理、数据集成、数据变换、数据归约、数据离散化。
①数据清理:数据是不完整的、有噪声的、不一致的(填充缺失值、去除噪声并识别离散点、纠正数据中的不一致值)
②数据集成(聚合):对数据进行聚合,将两个或多个数据源的数据,存放在一个一致的数据存储设备中。
③数据变换:将数据转换成适合于挖掘的形式。(平滑、聚集、数据泛化、规范化、数据离散化)
④数据归约:包含抽样、特征选择。
4、噪声数据的平滑方法
(1)分箱:
第一步:数据被分为n个等深箱
第二步:使用平均值或者边界平滑
箱越深、宽度越大,平滑效果越好。
(2)聚类:删除离群点
(3)回归:找适合的函数
5、数据变换
A、规范化
规范化是将原来的度量值转换为无量纲的值。(按比例缩放,映射到一个新的值域中)
(1)最小-最大规范化(转化为【0,1】范围内)
(2)z-score规范化(概率论的标准化)
(3)小数定标规范化(转化为”零点几×10的n次方“的格式)
B、特征构造
从原始特征船舰新的特征集。
C、数据离散化
利用分类值标记替换连续属性的数值。分为监督和非监督离散化。
无监督离散方法:(1)等宽(2)等频(3)基于聚类分析。
有监督离散方法:(1)基于熵:自顶向下
6、数据归约
A、抽样
压缩行数
有三种抽样方法。有放回、无放回、分层(p36)
B、特征选择
压缩列数
理想的特征子集:每个有价值的非目标特征应与目标特征强相关,而非目标特征之间不相关或者弱相关。
第三章 分类与回归
1、填空题
(1)评估分类模型准确率的方法包括:( )、( )和随机子抽样的方法。
答:保持方法、k-折交叉验证。
2、判断题
(1)回归预测输出的是连续取值( )
答:√
分类预测输出:离散类别值(预测一个类)。回归预测输出的是连续取值。
(2)KNN分类方法需要事先建模。( )
答:×
KNN是消极学习方法,不用事先建模。基本步骤:
1 算距离。给定测试对象,计算它与训练集中每个对象的距离;
2 找邻居。圈定距离最近的 k 个训练对象,作为测试对象的近邻。
3 做分类。 根据这k个近邻归属的主要类别,来对测试对象分类。
(3)AdaBoost 算法是一种将多个分类器聚集在一起来提高分类准确率的算法。( )
答:√
3、计算机题
公式:
信息熵:
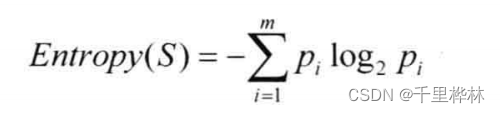
信息增益:
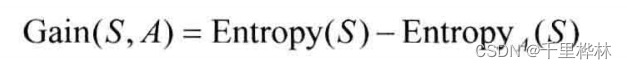
分裂信息:
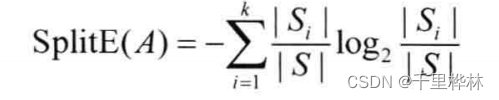
信息增益率:
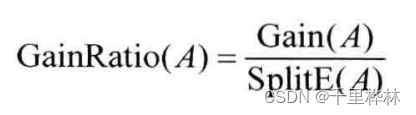
Gini系数:
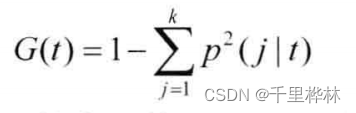
Gini系数增益:
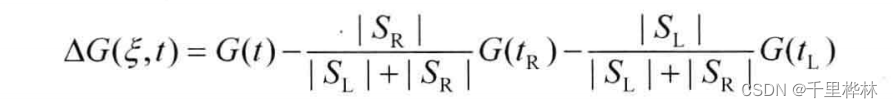
(1)用ID3算法,描述决策树建立过程
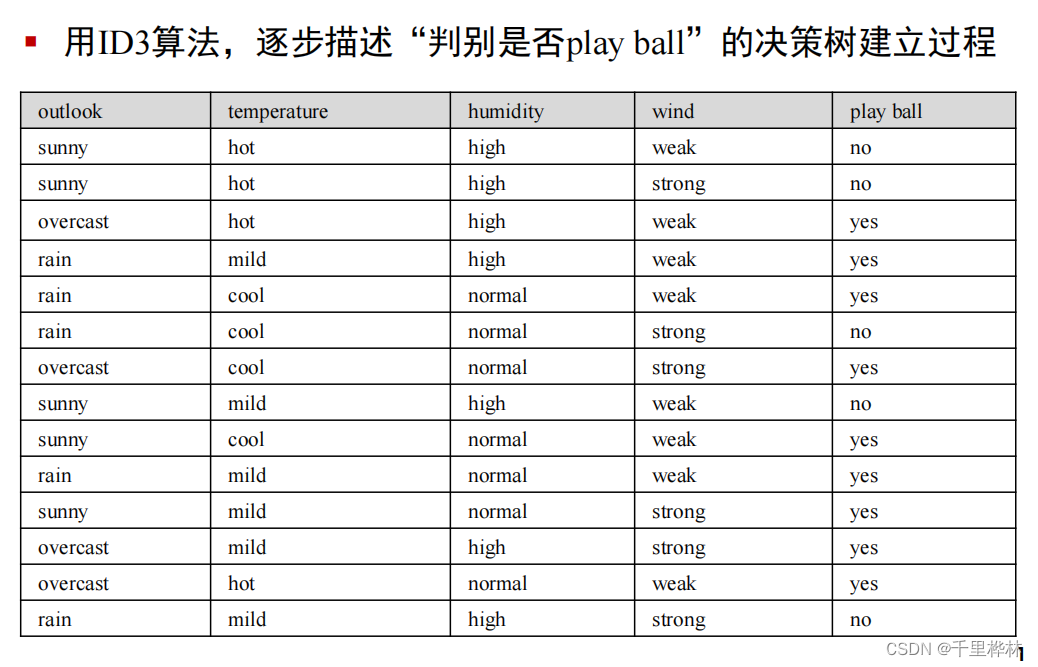


(2)给定某个天气数据集,求信息增益,信息增益率,Gini系数增益。
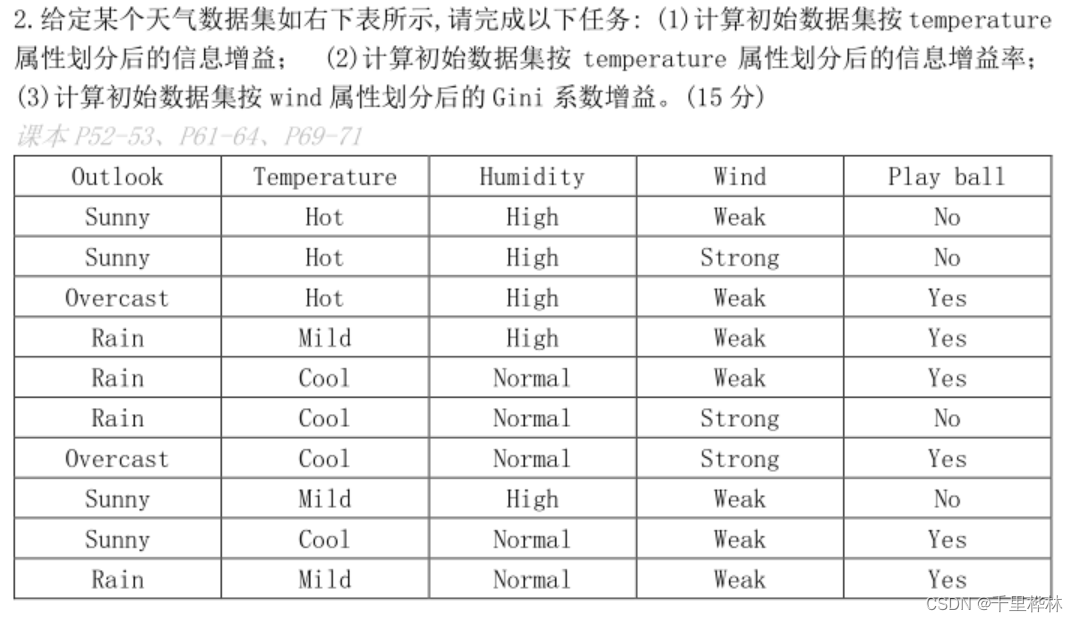
(1)步骤:
计算数据集的熵 E(S)
计算根据temperature划分的子集的熵 E(Si)
计算E temperature(S)= (|Si|/|S|) *E(Si) 的加和
计算信息增益Gain(S,temperature)=E(S)-E temperature(S)



(3)KNN书本例题
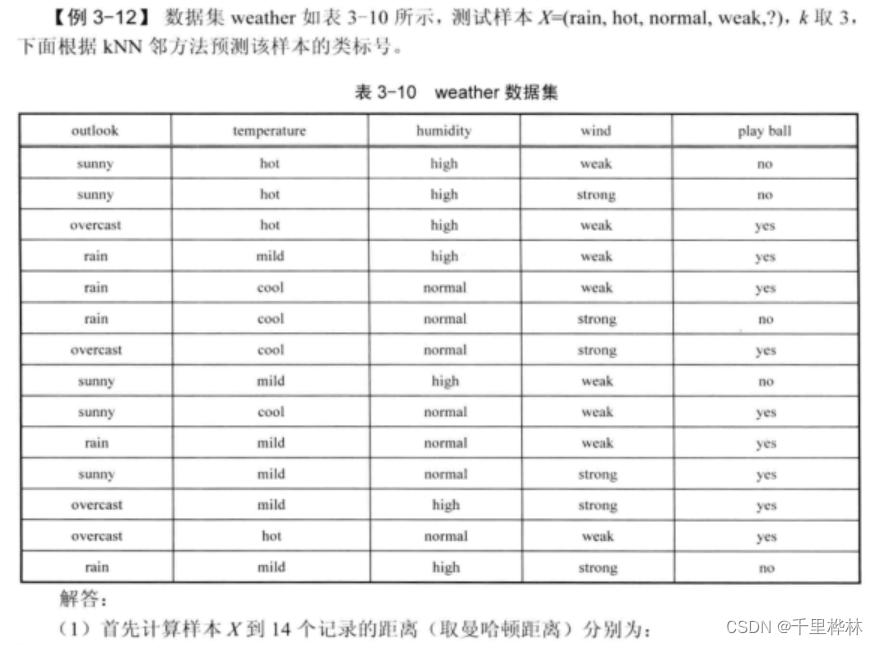

4、问答题
(1)写出贝叶斯公式,请给出朴素贝叶斯方法步骤。
答:公式:P(A|B) = P(B|A)*P(A) / P(B)
步骤:
(官方答案如下,每一个字单看我都认识,放一起就看不懂了。。。)
- 先根据所给的类标号未知的样本,计算类标号各类的后验概率.
- 根据贝叶斯公式,将后验概率的计算转化为样本各属性条件概率和先验概率的概率乘积计算,这两者易从所给条件算出.
- 在各类的计算结果中取概率最大的一类,将样本归入该类。
(简化版)
- 首先计算各个分类的概率;
- 然后计算预测数据的各个特征在每个分类维度下的概率;
- 按照分类维度计算:分类概率*每个特征概率;
- 选出步骤3中最大的结果即为所求;
(2)朴素贝叶斯的“朴素”是什么意思?简述朴素贝叶斯的主要思想。

第四章 聚类分析
1、填空题
(1)聚类算法分为划分方法、层次方法、基于密度的方法、基于图的方法、基于模型的方法,其中k-means属于( )方法,DBSCAN属于( )方法。
答:划分;基于密度的。
2、判断题
(1)一趟聚类算法能够识别从任意形状的簇。( )
答:×
一趟算法是将数据划分为大小几乎相同的超球体,不能用于发现非凸形状的簇。
(2)DBSCAN是相对抗噪声的,并且能够识别任意形状和大小的簇。( )
答:√
DBSCAN算法是基于密度的
(3)在聚类分析中,簇内的相似性越大,簇间的差别越大,聚类的效果越差。( )
答:×
一个好的聚类方法产生高质量的簇:高的簇内相似度,低的簇间相似度。
3、计算题
(1)k-means算法
算法:

题目:
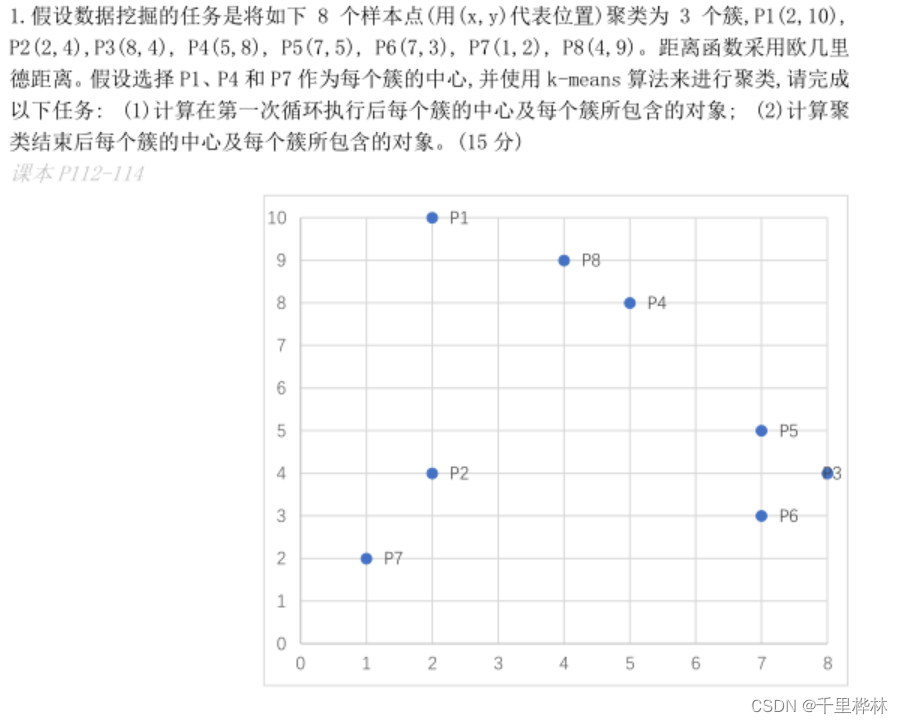
答:

4、典型的聚类方法
(1)划分方法:k-means、一趟算法
(2)层次方法:凝聚(自下而上)、分裂层次聚类方法(自顶向下)、CURE、BIRCH
(3)基于密度的方法:DBSCAN
(4)基于图的聚类算法:Chameleon、SNN
(5)基于模型的方法
K-means的不足
(1)簇的个数是预先给定的
(2)对初始值的选取依赖性极大,算法常常陷入局部最优解
(3)算法需要不断对样本分类调整
(4)对噪声点和离群点敏感
(5)不能发现非凸形状的簇,或者各种不同大小或密度的簇
(6)只能用于数值属性的数据集
层次聚类算法
自顶向下、自下而上两类。
三种改进的凝聚层次聚类(自下而上)方法 : BIRCH、ROCK、CURE。
基于密度的聚类算法 DBSCAN
根据点的密度,分为三类点:
(1)核心点:稠密区域内部的点
(2)边界点:稠密区域边缘上的点
(3)噪声或背景点:稀疏区域中的点
直接密度可达:p在q的Eps邻域内
密度可达:有在Eps范围内的连线,注意方向性!
密度相连:p和q都是从O关于Eps和MinPts密度可达的
DBSCAN课本例题:
算法:

题目:



基于图的聚类算法 Chameleon
绝对互联度 EC (EC越大,关联度越高,更应该合并)
相对互联度 RI (RI越大,两个类之间的连接都和两个类内部的连接度相差不大,可以更好地连接)

绝对紧密度 S
相对紧密度 RC

5、聚类算法评价
(1)内部质量评价标准
内部质量评价标准通过计算簇内平均相似度、簇间平均相似度、整体相似度来评价聚类效果。
例如:
CH指标:

CH越大(即 traceB 增大,traceW 减小),各个簇的均值差异越大,聚类效果越好。
traceW min = 0,一个类中各点重合,效果好。
(2)外部质量评价标准
外部质量评价标准是基于一个已经存在的人工分类数据集(已经知道每个对象的类别)进行评价的。
第五章 关联分析
1、填空题
(1)关联规则挖掘算法可分为两个步骤:①( ),②( )。
答:①产生频繁项集:发现满足最小支持度阈值的所有项集,即频繁项集。
②产生规则:从上一步发现的频繁项集中提取大于置信度阈值的规则,即强规则。
2、判断题
(1)若项集X是频繁项集,则X的子集必是频繁项集( )
答:√
(2)具有较高支持度的项集一定具有较高的置信度( )
答:×

3、计算题
Aprior算法:

(1)已知购物篮数据如右下表所示,请完成以下任务

答:(后来检查时发现,2-项集写漏了{面包,鸡蛋}:1,{啤酒,鸡蛋}:1,{尿布,鸡蛋}:1,但是对最终结果影响不大。)

(2)
support({面包}->{尿布})= 3/5
confidence({面包}->{尿布})= 3/4 <80%
所以不是强关联规则。
4、关联分析的应用场景
(1)挖掘商场销售数据,发现商品间的联系,帮助商场之间进行促销及货架的摆放。
(2)挖掘医疗诊断数据,可以发现某些症状与某种病之间的关联,为医生进行疾病诊断
(3)网页挖掘:揭示不同浏览网页之间的有趣联系。
5、关联分析概念
(1)项集:一个包含k个数据项的项集就称为k-项集。
(2)频繁项集:若一个项集的支持度大于或者等于某个阈值,则称为频繁项集。
(3)支持度计数:一个项集的出现次数,也就是整个交易数据集中包含该项集的事务数。
(4)关联规则:形如 X->Y 的蕴含式
(5)支持度:

(6)置信度:
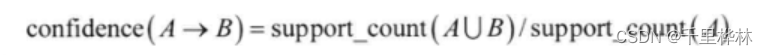
(7)强关联规则:大于最小支持度阈值和最小置信度阈值的关联规则。
6、Apriori算法
Apriori性质:一个频繁项集的任一子集也应该是频繁项集。
推论:如果一个项集是非频繁的,则它的超集也是非频繁的。
算法包含连接和剪枝两步。
7、相关性分析
(1)提升度(lift)。其值大于1,表示二者存在正相关;小于1,负相关;等于1,没有相关性。
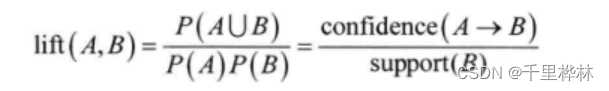
(2)兴趣因子
(3)相关系数
(4)余弦度量
8、项集个数计算
1、给定k个项,一共有2k-1 个项集。
2、频繁k项集有2k-2个调候选关联规则(除去L->ᴓ和ᴓ->L)
第六章 离群点挖掘
1、判断题
(1)如果一个对象不强属于任何簇,那么该对象是基于聚类的离群点( )。
答:√
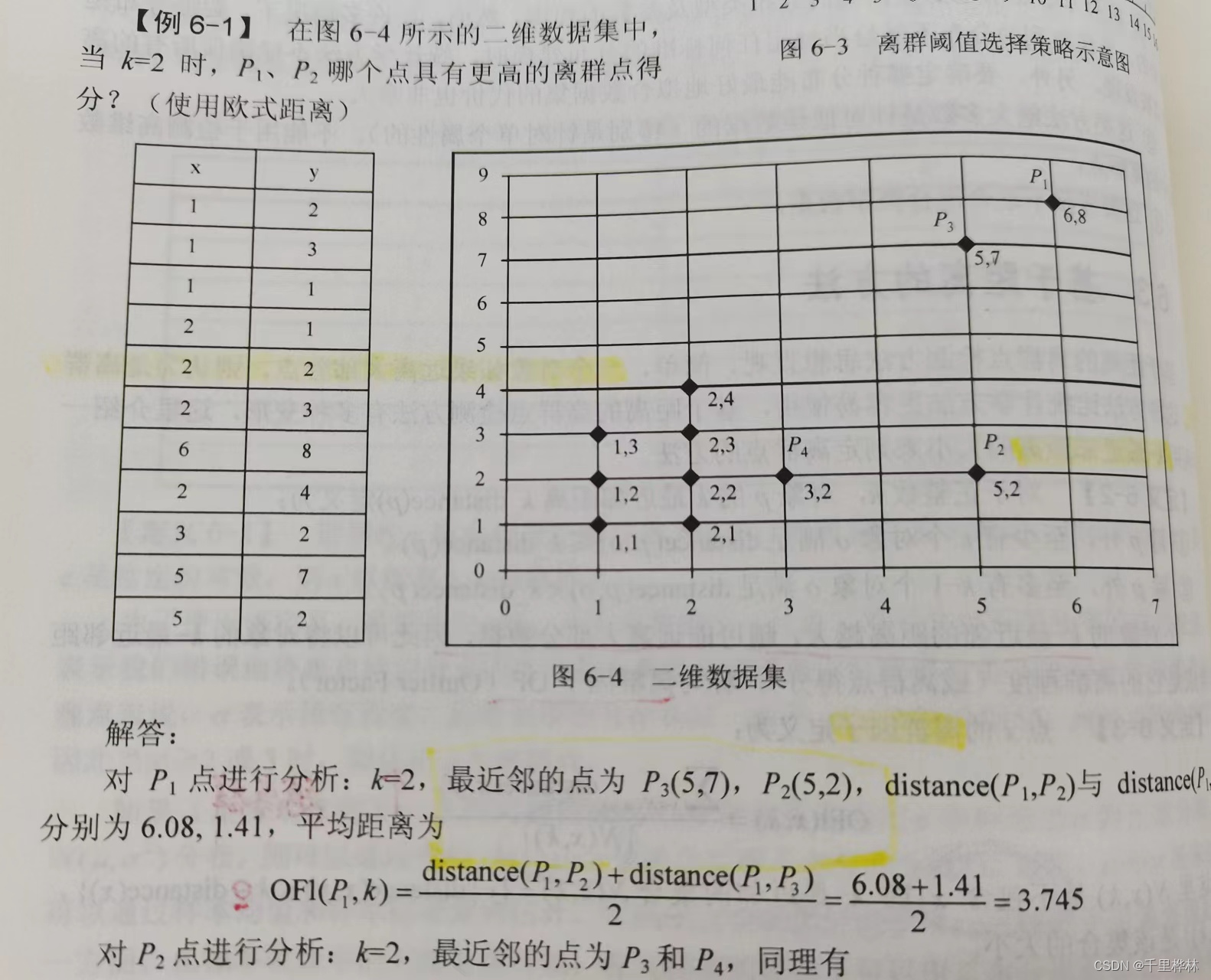
2、计算题
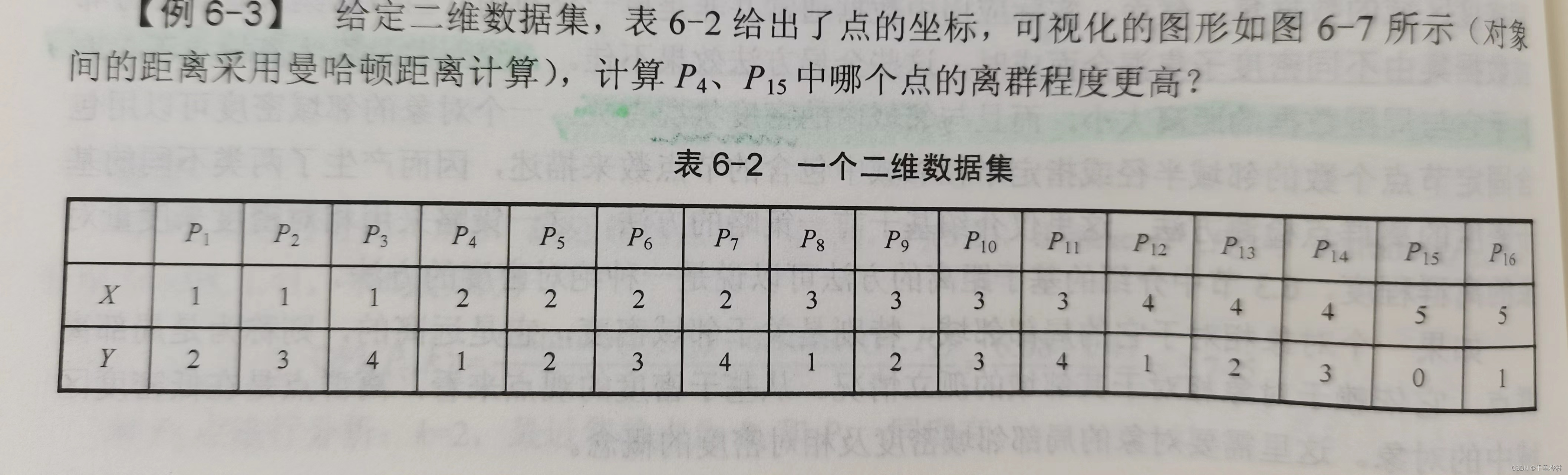
(1)给定二维数据集,点的坐标如下,取k=3,利用k-means算法求点p14和p16的离群因子OF1,哪个点更可能是异常点?
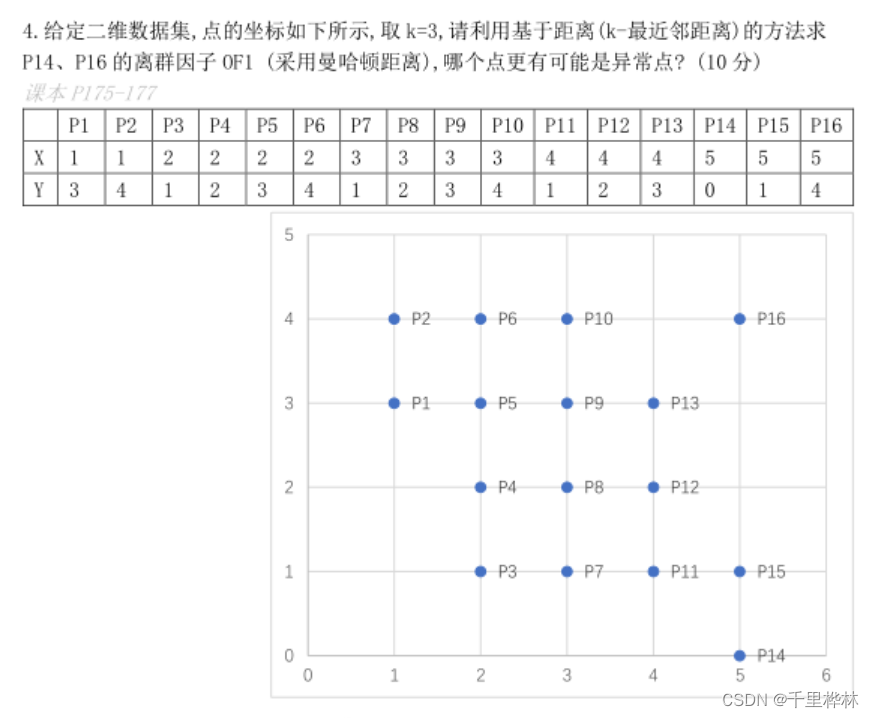
答:


3、问答题
(1)什么是离群点?请问离群点挖掘算法检测出的离群点是否一定对应实际的异常行为?如果是,请给出说明;如果不是,请举一个反例。
答:离群点是数据集中偏离大部分数据的数据,使人怀疑这些数据的偏离并非由随机因素产生,而是产生于不同的机制。
一般地,离群点可能对应实际的异常行为。由于离群点产生的机制是不确定的,离群点挖掘算法检测出的“离群点”是否对应实际的异常行为,不算由离群点挖掘算法来说明、解释的,只能由领域专家来解释。
离群点可能是测量、输入错误或系统运行错误而造成的,也可能是数据内在特性所决定的,或因客体的异常行为所导致的。
例如:一个的年龄为-999,就可能是由于程序处理默认数据、设置默认值造成的。一个公司的高层管理人员的工资明显高于普通员工的工资而可能成为离群数据,却是合理的数据。一部住宅电话的话费由每月200元以内增加到数千元,可能是因为被盗打或其他特殊原因所导致的。一张信用卡出现明显的高额消费也许是因为该卡被盗用了。
4、离群点产生原因
(1)测量、输入错误或者系统运行错误而造成
(2)数据内在特性所决定
(3)因客体的异常行为所导致
5、离群点挖掘中需要处理的3个问题

6、基于统计的方法
将于模型不一致的数据标识为离群数据。如果一个对象关于数据的概率分布模型具有低概率值时,则认为其是离群点。
概率分布模型通过估计用户指定的分布参数,由数据创建。
质量控制示意图


7、基于距离的方法
(1)点x的离群因子:OF1越大,点x越离群。
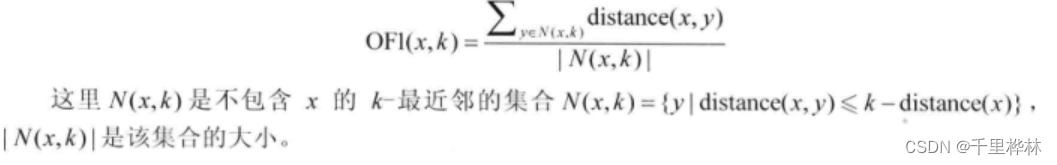
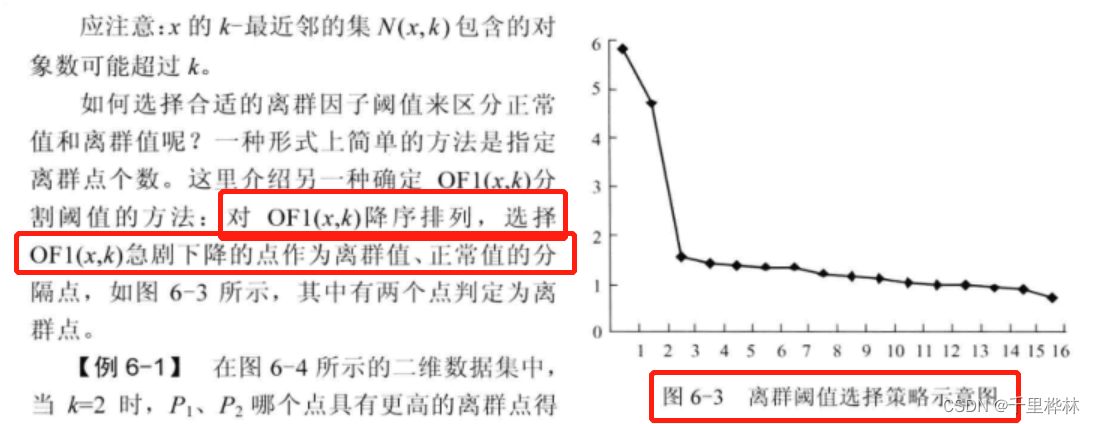
课本例题:计算OF1
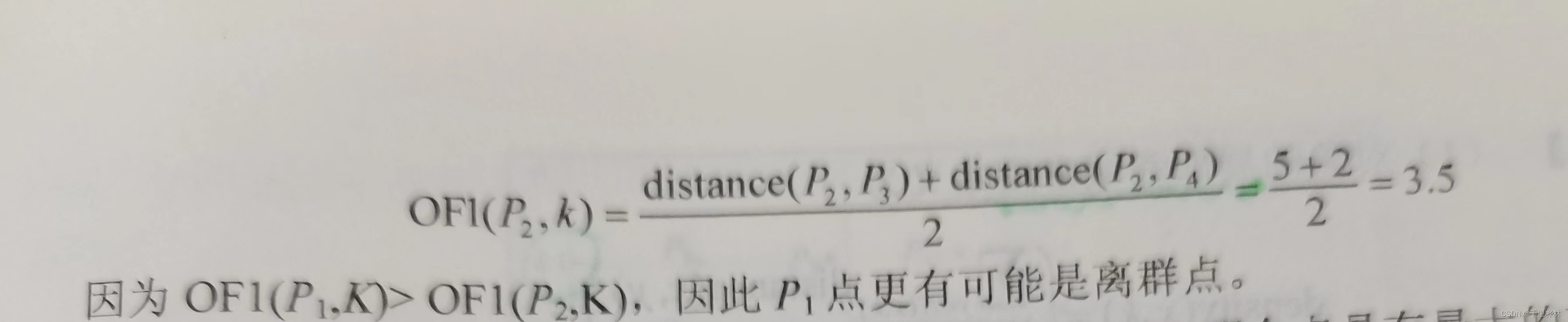
8、基于相对密度的方法
(1)局部邻域密度:
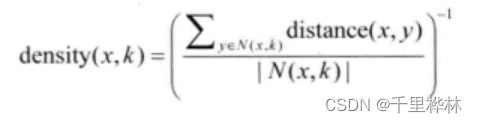
(2)相对密度:通过比较对象的密度和它的邻域中的对象平均密度来检测离群点。

课本例题:计算OF3

9、基于聚类的方法
对动态和静态数据离群点的检测方法:

10、离群点挖掘方法的评估
混合矩阵:

离群点挖掘方法准确性的两个指标:
(1)检测率
(2)误报率

以上就是全部内容了。
END