一种获取网站信息的工具包
Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式.Beautiful Soup会帮你节省数小时甚至数天的工作时间。
import requests
from bs4 import BeautifulSoup #注意这里不是用BeautifulSoup4,注意严格区分大小写
r=requests.get(url='https://news.qq.com/a/20180409/001200.htm')
# print(r)
# print(r.text)
soup=BeautifulSoup(r.text,'lxml') #用'lxml'库去解析r.text; 如果不写'lxml'则表示用Python自带带库去解析
#print(type(r.text)) #<class 'str'> 文本文件
#print(type(soup)) #<class 'bs4.BeautifulSoup'> 识别每个标签带意义
#print(soup.prettify()) #输出有缩进带源代码
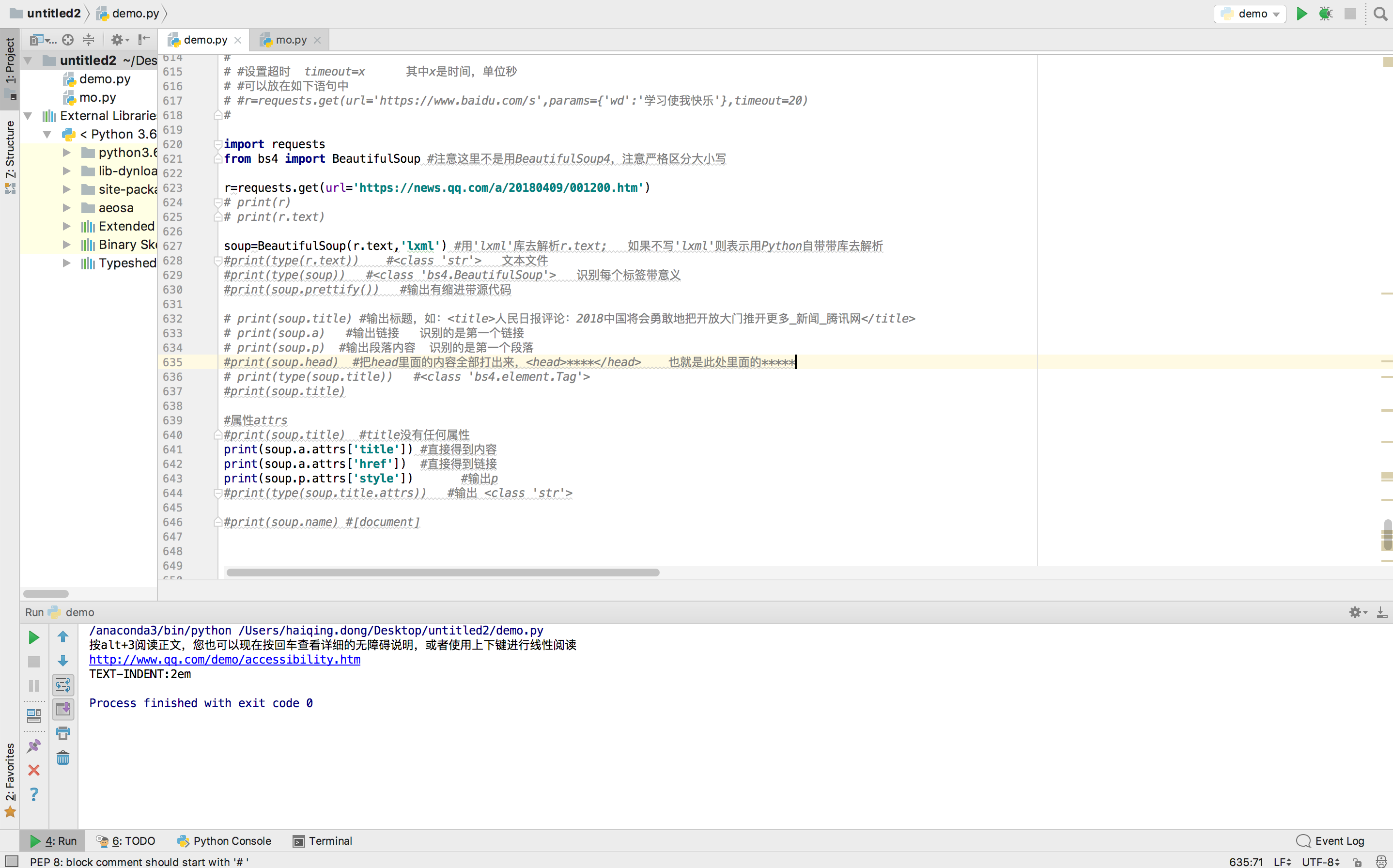
print(soup.title) #输出标题,如:<title>人民日报评论:2018中国将会勇敢地把开放大门推开更多_新闻_腾讯网</title>
print(soup.a) #输出链接
print(soup.p) #输出段落内容
#print(soup.head) #把head里面的内容全部打出来,<head>****</head> 也就是此处里面的*****运行结果:
代码2:
import requests
from bs4 import BeautifulSoup #注意这里不是用BeautifulSoup4,注意严格区分大小写
r=requests.get(url='https://news.qq.com/a/20180409/001200.htm')
# print(r)
# print(r.text)
soup=BeautifulSoup(r.text,'lxml') #用'lxml'库去解析r.text; 如果不写'lxml'则表示用Python自带带库去解析
#print(type(r.text)) #<class 'str'> 文本文件
#print(type(soup)) #<class 'bs4.BeautifulSoup'> 识别每个标签带意义
#print(soup.prettify()) #输出有缩进带源代码
# print(soup.title) #输出标题,如:<title>人民日报评论:2018中国将会勇敢地把开放大门推开更多_新闻_腾讯网</title>
# print(soup.a) #输出链接 识别的是第一个链接
# print(soup.p) #输出段落内容 识别的是第一个段落
#print(soup.head) #把head里面的内容全部打出来,<head>****</head> 也就是此处里面的*****
# print(type(soup.title)) #<class 'bs4.element.Tag'>
#print(soup.title)
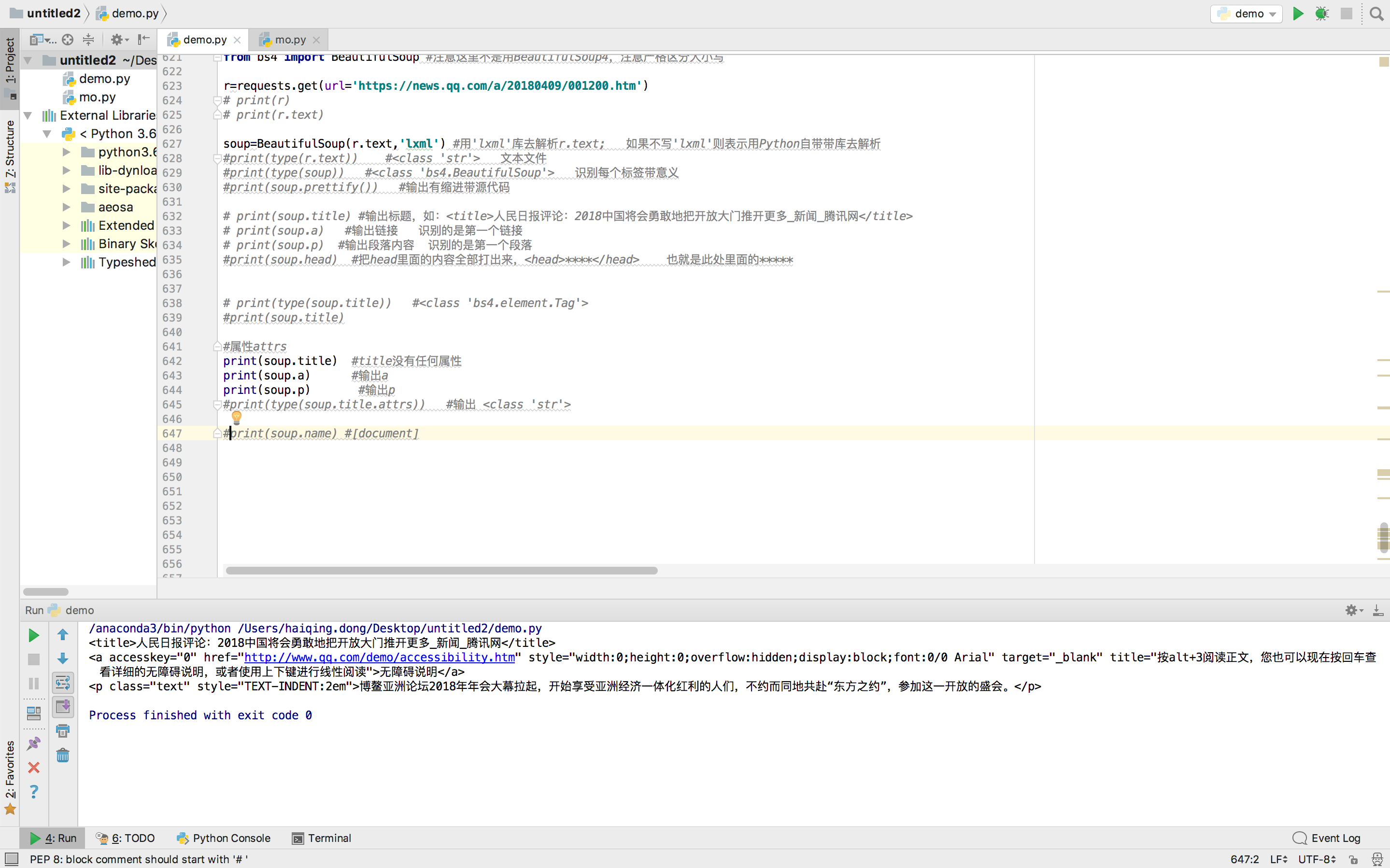
print(soup.title.name) #输出title
print(soup.a.name) #输出a
print(soup.p.name) #输出p
print(type(soup.title.name)) #输出 <class 'str'>运行结果:
代码3:
import requests
from bs4 import BeautifulSoup #注意这里不是用BeautifulSoup4,注意严格区分大小写
r=requests.get(url='https://news.qq.com/a/20180409/001200.htm')
# print(r)
# print(r.text)
soup=BeautifulSoup(r.text,'lxml') #用'lxml'库去解析r.text; 如果不写'lxml'则表示用Python自带带库去解析
#print(type(r.text)) #<class 'str'> 文本文件
#print(type(soup)) #<class 'bs4.BeautifulSoup'> 识别每个标签带意义
#print(soup.prettify()) #输出有缩进带源代码
# print(soup.title) #输出标题,如:<title>人民日报评论:2018中国将会勇敢地把开放大门推开更多_新闻_腾讯网</title>
# print(soup.a) #输出链接 识别的是第一个链接
# print(soup.p) #输出段落内容 识别的是第一个段落
#print(soup.head) #把head里面的内容全部打出来,<head>****</head> 也就是此处里面的*****
# print(type(soup.title)) #<class 'bs4.element.Tag'>
#print(soup.title)
#属性attrs
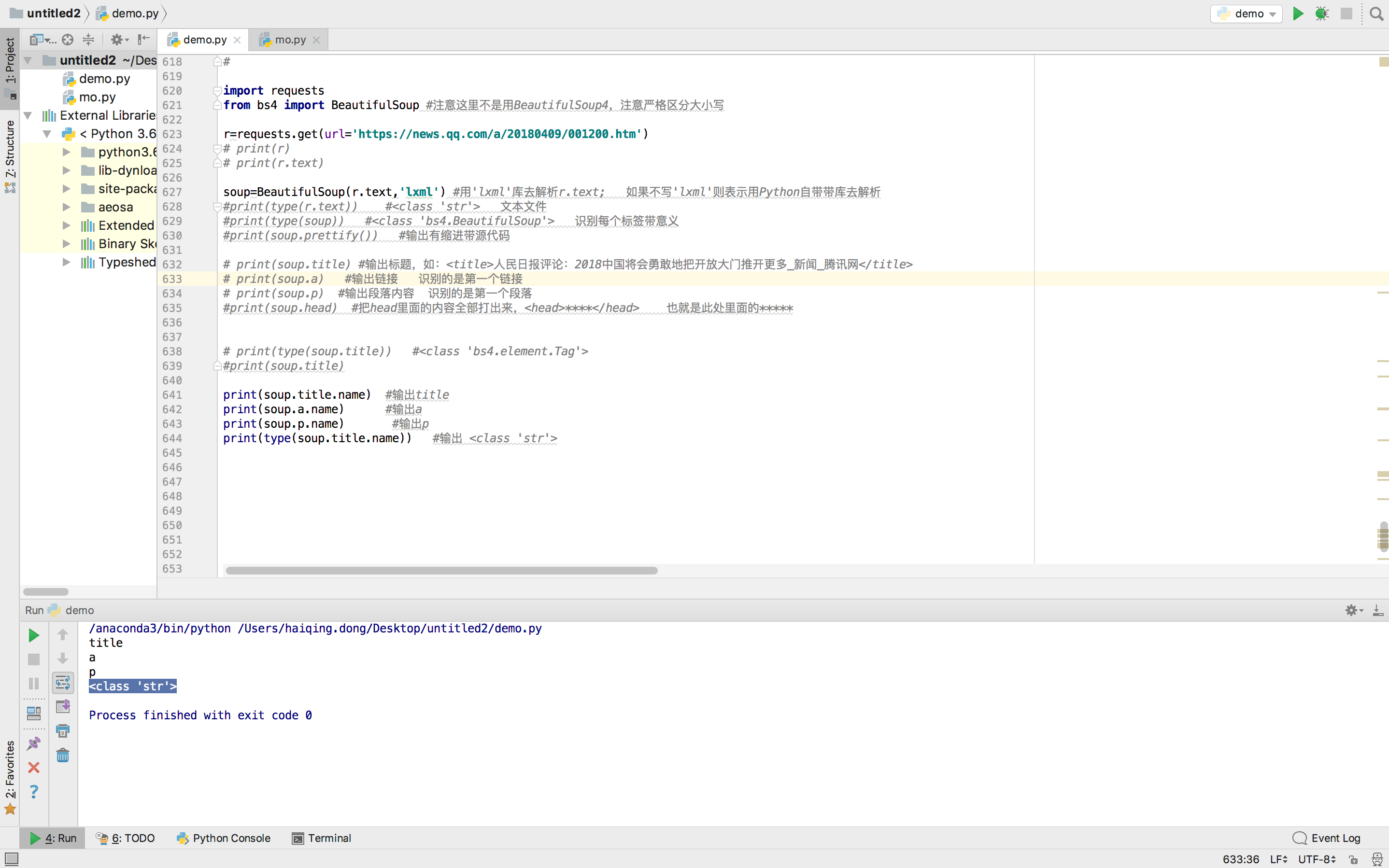
print(soup.title.attrs) #title没有任何属性
print(soup.a.attrs) #输出a
print(soup.p.attrs) #输出p
print(type(soup.title.attrs)) #输出 <class 'str'>
print(soup.name) #[document]
运行结果:

代码4:
import requests
from bs4 import BeautifulSoup #注意这里不是用BeautifulSoup4,注意严格区分大小写
r=requests.get(url='https://news.qq.com/a/20180409/001200.htm')
# print(r)
# print(r.text)
soup=BeautifulSoup(r.text,'lxml') #用'lxml'库去解析r.text; 如果不写'lxml'则表示用Python自带带库去解析
#print(type(r.text)) #<class 'str'> 文本文件
#print(type(soup)) #<class 'bs4.BeautifulSoup'> 识别每个标签带意义
#print(soup.prettify()) #输出有缩进带源代码
# print(soup.title) #输出标题,如:<title>人民日报评论:2018中国将会勇敢地把开放大门推开更多_新闻_腾讯网</title>
# print(soup.a) #输出链接 识别的是第一个链接
# print(soup.p) #输出段落内容 识别的是第一个段落
#print(soup.head) #把head里面的内容全部打出来,<head>****</head> 也就是此处里面的*****
# print(type(soup.title)) #<class 'bs4.element.Tag'>
#print(soup.title)
#属性attrs
#print(soup.title) #title没有任何属性
print(soup.a.attrs['title']) #直接得到内容
print(soup.a.attrs['href']) #直接得到链接
print(soup.p.attrs['style']) #输出p
#print(type(soup.title.attrs)) #输出 <class 'str'>
#print(soup.name) #[document]
运行结果: