环境:Python3、PyCharm
代码1:
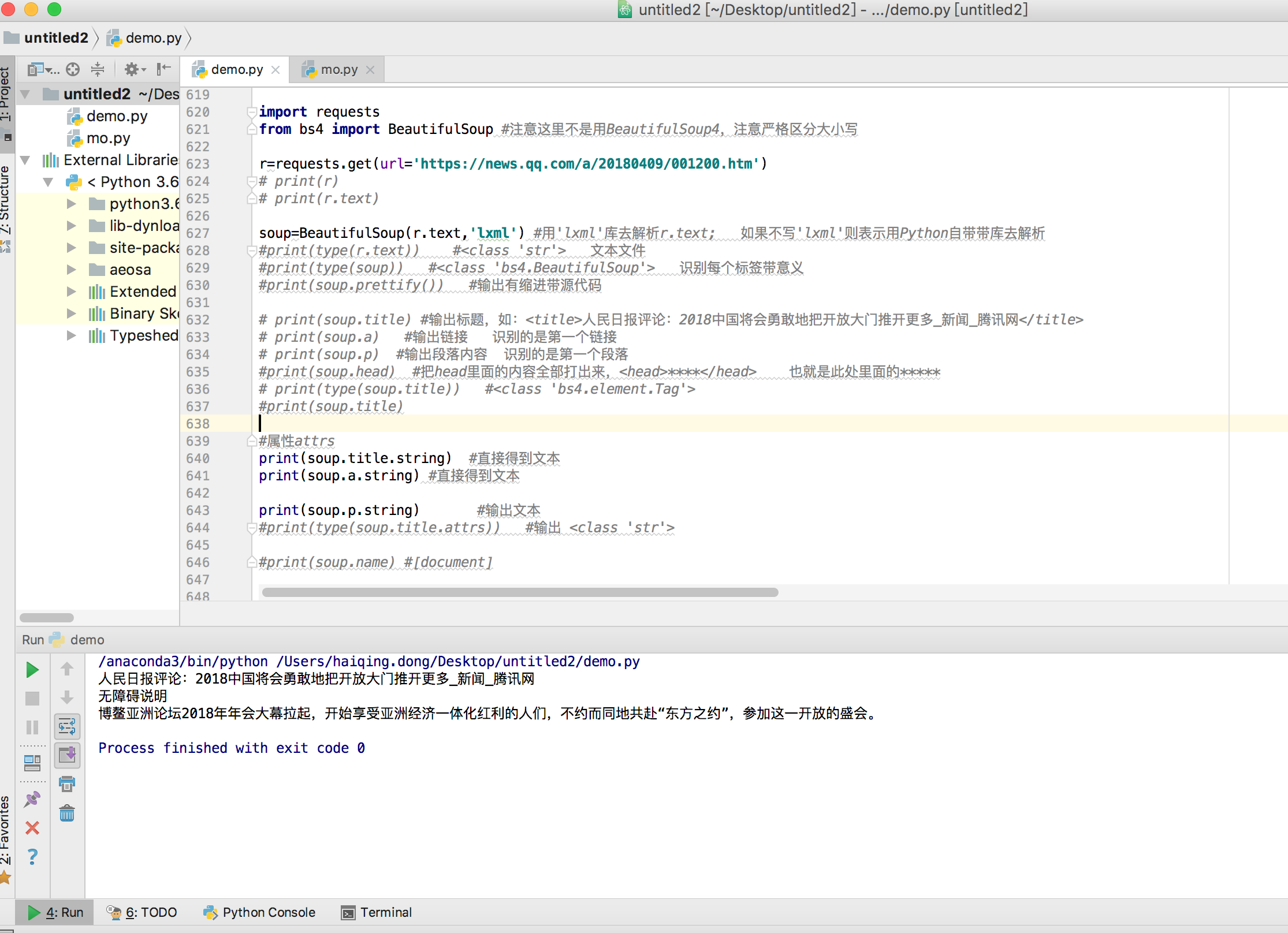
print(soup.title.string) #直接得到文本 print(soup.a.string) #直接得到文本 print(soup.p.string) #输出文本
import requests
from bs4 import BeautifulSoup #注意这里不是用BeautifulSoup4,注意严格区分大小写
r=requests.get(url='https://news.qq.com/a/20180409/001200.htm')
soup=BeautifulSoup(r.text,'lxml') #用'lxml'库去解析r.text; 如果不写'lxml'则表示用Python自带带库去解析
print(soup.title.string) #直接得到文本
print(soup.a.string) #直接得到文本
print(soup.p.string) #输出文本
运行结果:
代码2(以下代码注释掉掉也是可以运行的,需要实际试一试):
这一部分不是很重要,了解一下即可。
import requests
from bs4 import BeautifulSoup
r=requests.get(url='https://news.qq.com/a/20180409/006082.htm')
soup=BeautifulSoup(r.text,'lxml')
####直接子节点 .contents .children
# print(soup.head.contents)
#
# print(type(soup.head.contents)) #结果是list
# print(soup.head.children)
# print(type(soup.head.children)) #children是一个生成器,需要用循环打印,如下
#
# for i in soup.head.children:
# print(i)
#print(type(range(10)))
###所有子孙节点 .descendants
# print(soup.body.descendants)
#
# for i in soup.head.descendants:
# print(i)
#
# print(type(soup.head.descendants))
###父节点 .parent
# title=soup.title
#
# print(type(title))
# print(title.parent)
#
# print(title.parent.name)
# print(title.parent.attrs)
###全部父节点 .parents
# a=soup.a
# print(type(a.parents)) #<class 'generator'>
# for i in a.parents:
# print(i.name)
#
# h=soup.html
# print(h.parent.name) #输出[document],html上面就没有啦
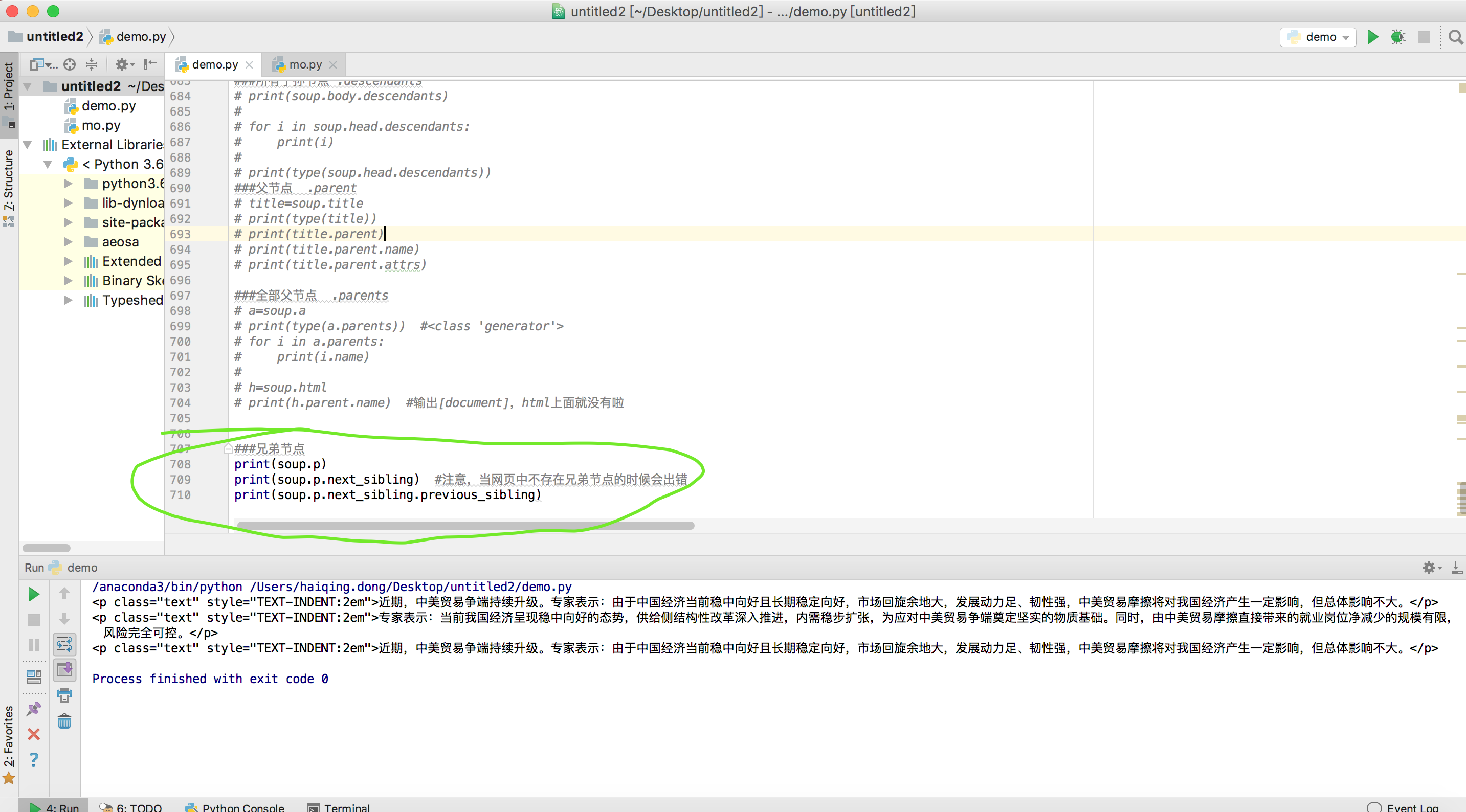
###兄弟节点
print(soup.p)
print(soup.p.next_sibling) #注意,当网页中不存在兄弟节点的时候会出错
print(soup.p.next_sibling.previous_sibling)运行结果: