环境:Python3、PyCharm
find_all()
代码1:
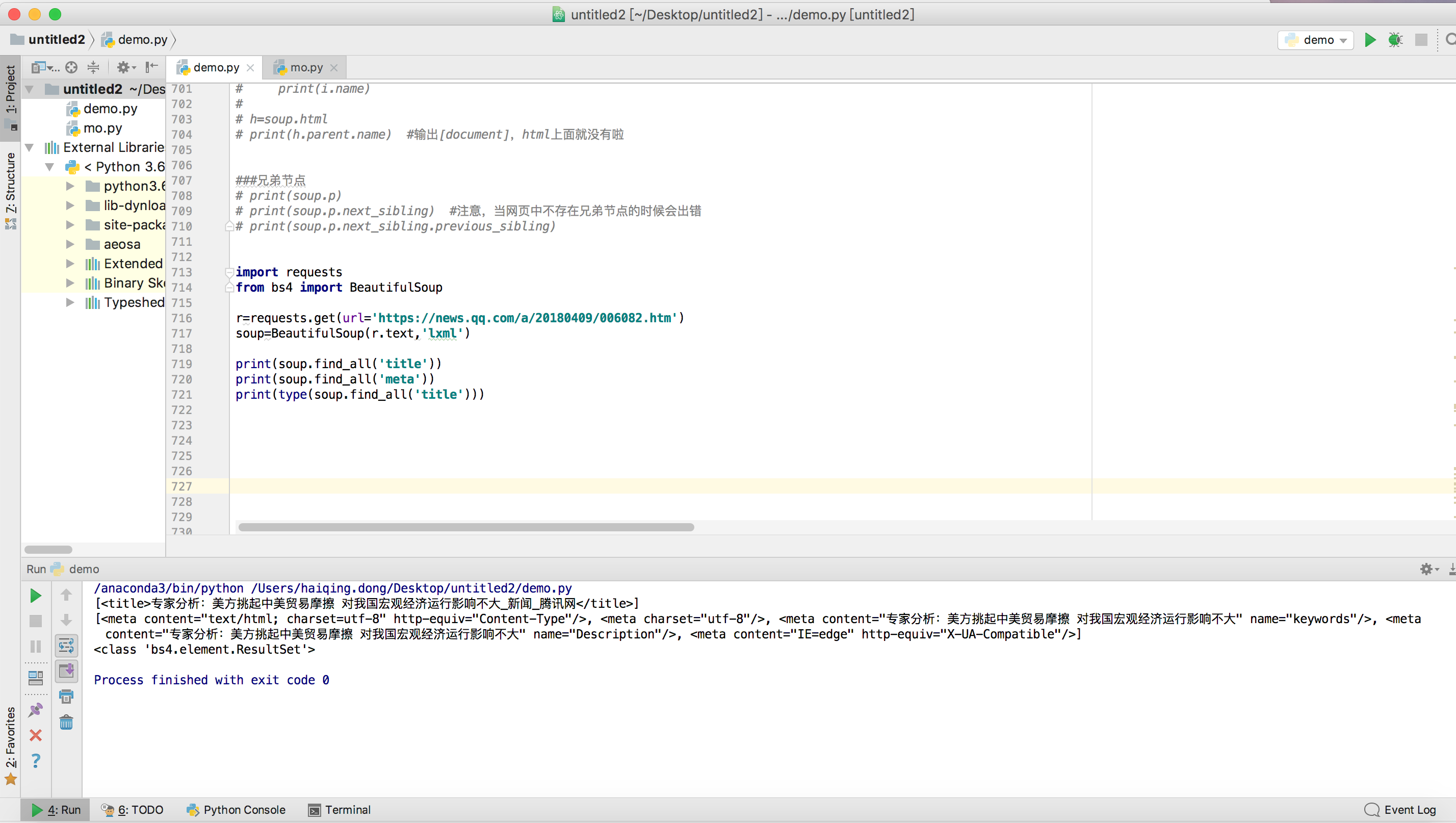
import requests
from bs4 import BeautifulSoup
r=requests.get(url='https://news.qq.com/a/20180409/006082.htm')
soup=BeautifulSoup(r.text,'lxml')
print(soup.find_all('title'))
print(soup.find_all('meta'))
print(type(soup.find_all('title')))
运行结果:
代码2:
import requests
from bs4 import BeautifulSoup
r=requests.get(url='https://news.qq.com/a/20180409/006082.htm')
soup=BeautifulSoup(r.text,'lxml')
print(soup.find_all('img')) #输出所有img
print(soup.find_all('img',"sspLogo")) #属性"sspLogo"表示只找这一个
print(soup.find_all('img',limit=2)) #limit=2表示返回两个
运行结果:

代码3:
import requests
from bs4 import BeautifulSoup
import re
r=requests.get(url='https://news.qq.com/a/20180409/006082.htm')
soup=BeautifulSoup(r.text,'lxml')
# print(soup.find_all('img')) #输出所有img
# print(soup.find_all('img',"sspLogo")) #属性"sspLogo"表示只找这一个
#
# print(soup.find_all('img',limit=2)) #limit=2表示返回两个
# print(soup.find_all('img',height="20")) #height="20"是具体参数
#
# print(soup.find_all('img',src=True)) #包含src参数的都在内
#
# for i in soup.find_all('img',height=True):
# print(i)
#####以下没有输出,可能是因为'https://news.qq.com/a/20180409/006082.htm'网站本省就没有
#print(soup.find_all('a',href=re.compile('https://news.qq.com/a/20180409/')))
#for i in soup.find_all('a',href=re.compile('https://news.qq.com/a/20180409/')):
# print(i.attrs['href'])
###########
# print(soup.find('a'))
# print(soup.find('a').text)
print(soup.find('div',id="shareBtn")) #查找特定的以上命令,到IDE试一试即可,没必要全部记住哦。
扫描二维码关注公众号,回复:
2437085 查看本文章
