作为一个已经2年经验的程序员,随着项目经验的逐渐积累,特别是技术栈深度和广度的逐渐扩展,现在越来越认识到算法基础 也是越来越重要,在某些时候更是会让你在技术栈深度扩展时过早的出现瓶颈(只知其一不知其二或者无法做到举一反三)。所以现在决定在算法领域开始自己的积累,也希望大家可以一起成长。
在算法的学习中,算法分析是基础的一部分,在设计算法的时候,效率是非常重要的因素之一。所以在设计算法前,快速、合理的对算法的效率进行分析是进行算法设计的必备基础技能之一。
在计算机领域中,在处理相同的数据问题时,衡量两个算法孰优孰劣无非也就两点:
1、算法执行需要的时间(这里我们称为时间复杂度)
2、算法执行需要的内存空间(空间复杂度)
那么怎么去快速和准确的对某个算法的时间复杂度和空间复杂度。难道真的要挨个语句和指令去计算时间和空间吗?其实不然。MIT算法导论中第二章讲述了,算法分析是对一个算法所需要的资源(时间、内存空间、带宽等)进行预测。但在程序实际运行中,实际所消耗的资源跟众多因素(操作系统、编译器、CPU等)相关。如何能在如此复杂的环境中快速准确的计算并比较各算法之间优劣势呢?这里需要在算法分析时,摒弃掉一些琐碎的东西。那主要摒弃哪些东西呢?
总所周知,一个程序执行所需要的总时间主要取决于以下三点:
1.执行每条语句所需要的时间
2.一个程序需要执行多少条语句和每条语句执行的频率
3.数据输入规模
由于第1点主要取决于操作系统,CPU等硬件因素,每台电脑在执行时都会不一样,为了方便计算,我们可以摒弃这些繁琐的细节,并假设所有电脑执行一条语句所需要的时间是θ(1)。
此时,要计算出一个程序在不同的输入规模时,执行所需要的总时间只需要计算出执行的语句数和各条语句的频率乘积,便可以推断和比较各算法间的区别。
在我们正常的视觉效果中,数据输入规模越大,算法执行的时间就会越高,而执行时间和数据输入规模也势必会呈现出函数式增长。
在MIT算法导论中第三章 函数的增长 中着重讲述了如何使用数学表达式正确的表述某个算法的随着输入规模的增长时,所需要消耗资源的增长数量级别。
虽然我们摒弃掉了由于硬件和编译器因素带来的繁琐的细节,但在实际的消耗资源计算过程中仍存在很多复杂而繁琐的细节。而在计算算法所消耗资源的时候,往往不需要“太精确”(后面的章节中会再讲述其他摒弃掉的细节问题)。对于输入规模足够大的时候,我只要关心算法所消耗的增加量级,也就是研究算法的渐进效率。
关于增长量级的常见假设有以下几种类型:
描述 |
增长的数量级 | 典型的代码 | 说明 | 举例 |
| 常数级别 | 1 | 单条语句 | 程序的某条执行语句 | |
| 对数级别 | log N | 二分查找法 | 二分查找 | |
| 线性级别 | N | 单层循环 | 数组遍历 | |
| 线性对数级别 | N log N | 递归排序 | 归并排序 | |
| 平方级别 | N^2 | 双层循环 | 枚举所有元素对 | |
| 立方级别 | N^3 | 三层循环 | 枚举所有三元组 | |
| 指数级别 | N^N | 穷举查找 | 枚举所有子集的组合 |
描述 增长的数量级 典型的代码 说明 举例 常数级别 1 单条语句 程序的某条执行语句 对数级别 log N 二分查找法 二分查找 线性级别 N 单层循环 数组遍历 线性对数级别 N log N 递归排序 归并排序 平方级别 N^2 双层循环 枚举所有元素对 立方级别 N^3 三层循环 枚举所有三元组 指数级别 N^N 穷举查找 枚举所有子集的组合
下图是用matlab对各个增长数量级进行的对比:
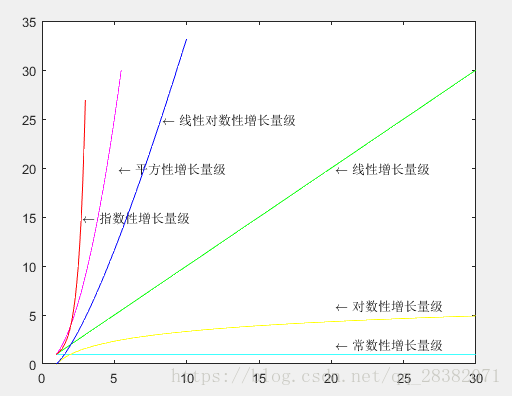
由图中可以直观的看出各个增长量级随着的n的增加,所需要消耗的资源的增长趋势。所以从算法的渐进效率角度出发,设计出常数性或者对数性增长量级的算法在上是最优的。
ps:常数级别这辈子是不可能的了,这辈子最多也就对数性级别了
链接中是对比各增长量级 matlab源代码,有需要的可自行下载,没积分的同学,可以私我或者留言邮箱,手动无偿转发