微信和chatgpt
这个在另外一篇文章:微信接入chatgpt
背景
- 最近一直都在忙做文本机器人的事情,所以就很少发公众号文章了。
- 目前机器人的代码,已经全部发布在github上了。
- 做机器人的目的:一方面是为了锻炼自己的代码能力,一方面也是因为自己想做一些有趣的时候。
- 这个项目足够优雅,只需要python环境即可,就算是没有显卡也都行。而且即开即用,我也不喜欢安装太多的依赖包。
下面就是完整的介绍了。效果的话,也不介绍了,反正有点意思,这里放几个截图:
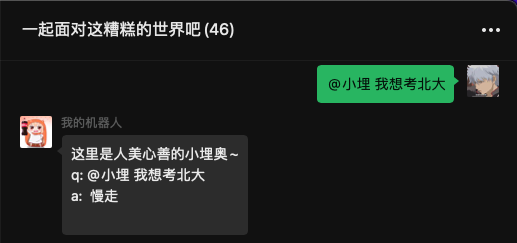

这里因为使用的是一个“怼人的知识库”导致返回的答案就很气人。
其实这里也可以换成别的知识库,都是可以的。都是通用的。
仓库地址:https://github.com/yuanzhoulvpi2017/questionAnswerSystem
介绍
本项目是在不借助数据库的情况下:
- 基于pandas、numpy、pytorch实现数据的curd的(替代数据库的)
- 基于transformers、sentence-transformers实现文本转向量的
- 基于fastapi对外暴露接口的
- 问答机器人。
目的
- 实现一个问答机器人(基于sbert来做)其实是想做搜索,其实我感觉nlp和搜索也都差不多,都是策略问题。
- 不依赖数据库,实现数据管理的crud。
- 希望依靠numpy、fastapi能做一个拥有redis功能的数据库(听起来很可笑,我自己也觉得肯定是不可能的,我就是想试一试,提高代码能力)。
- 在实现的过程中,我希望把整个nlp问答机器人的数据流都打通。数据流打通,至于用什么数据库之类的,都是小事情。
实现的功能有什么
- crud中的R功能,也就是Read。或者干脆就叫搜索吧。起码要有搜索功能
- crud中的c功能,也就是Create。对应到一个完整的问答机器人,也就是:
创建知识条目 - crud中的u功能,也就是update。对应到这个项目里面,也就是:
更新知识条目的答案、更新知识条目中相似问法 - crud中的d功能,也就是delete。对应到这个项目里面,也就是:
删除知识条目、删除相似问法 - 其实还有转换功能,实现文本转向量功能。
- 还有计算相似度功能,主要是基于cos距离
- 还有分组统计的功能,主要是使用mrr来计算。
缺点
- 没有考虑并发,但其实一般1秒处理100条,基本上不是问题。
- 应该有很多缺点,大家可以提issue给我。
数据结构
一个完整的知识库中的条目,起码要有这三个部分:
- 标题:这个知识库的标题是什么。一般来说都是文本。
- 答案:这个是要返回的结果,或者叫答案。一般是文本,有的是接口,我这里不管了,都是文本。
- 相似问法:相似问法是对标题的补充,尽可能覆盖用户会提问的语句内容。
- 其实还有别的,比如条目类型、创建时间等,我这里有的就省略了。
我这里采用标题和相似问法剥离的处理方式。把他们分为两个表:
程序上的中间表
1. 标题表(pandas保存)
维度有:
- 标题:
title - 答案:
answer - 创建时间:
create_time - 修改时间:
modify_time rep_id:和相似问法表关联- 状态:
status_question: 0代表关闭,1代表激活
2. 相似问法表(pandas保存)
维度有:
rep_id:和标题表问法关联- 相似问法:
similarity - 创建时间:
create_time - 修改时间:
modify_time - 状态:
status_similar: 0代表关闭,1代表激活 - 索引:
sim_index
还有两个表:
- 相似问法的向量:对相似问法做encoding,保存为numpy向量
- 标题的向量:对标题做encoding,保存为numpy向量
硬件要求。
这个对硬件要求不高。唯一要求就是,起码内存要16G以上。
常规版本:
我的MacBook pro 16寸的(内存16G,无cuda)
高配版本:
- cpu:12700
- 内存:64G
- 显卡:nvidia-3090
- ubuntu-22.04
运行
step0 安装包
按照requirements.txt的指导,安装对应的包。基本上都是nlp开发者经常用到的包,不需要特别注意
step1 开启向量引擎后台
backend_new.py是整个问答机器人的核心。这个能运行即可。需要等待一段时间,有加载模型数据和初始化知识库的步骤。
细节部分:
- 对外端口是8010。想要切换的话,直接在代码最后面修改即可。用的就是fastapi,熟悉fastapi的用户,随便怎么改都可以。
- 等全部的都加载完全之后,在浏览器里面打开:
http://0.0.0.0:8010/docs就能看到所以的暴露接口了。

step2 如何查询
如何把这个向量搜索引擎用起来呢?可以看看front_search.ipynb文件,这里会教你如何查询一个文本,并且提取结果。
step3 如何管理知识库
在文件front_admin.ipynb里面,你可以看到这些内容:
- 如何创建知识条目
- 如何删除条目
- 如何删除相似问法
- 如何更新答案
- 如何增加相似问法
知识库如何导出
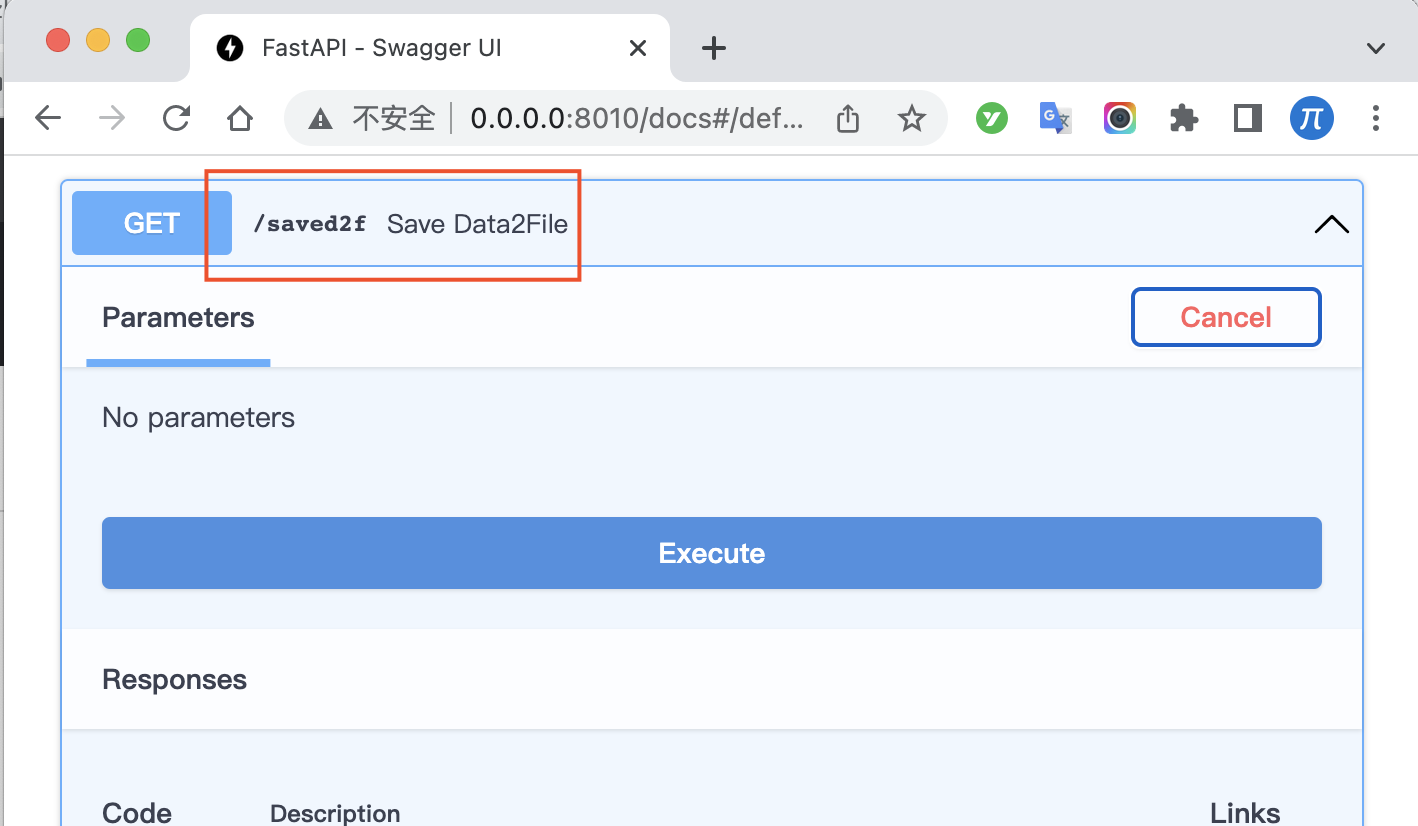
因为你的一切修改,都是在内存里面,如果你的程序结束,那么所有的内容都会消失。比如你维护的知识条目。这个也考虑到了。在http://0.0.0.0:8010/docs
你可以看到一个叫saved2f接口,运行一下,就会把你的条目放在文件夹QADIR里面,一个是相似问法的表,一个是标题的表。
如何做微信机器人
- 目前还在开发微信机器人,就是类似于在群里面聊天的,等后面整理好代码,都会分享出来~