YOLOv2 沉思录
思考3个问题?
第一、模型最后一层输出的值,是什么?
第二、模型输出的结果,如何转换计算得到预测框(手工标准那种框)?
第三、数据处理计算target,如何算?也就是如何计算真值,然后去计算loss?
这三个问题,一直困扰我很久,也反反复复得看,当时看的时候,是想明白了,过了一阵子又忘了,所以还是决定记录下来。
第一个问题
第一、模型最后一层输出的值,是什么?
先来看看论文给出的预测框,这个图
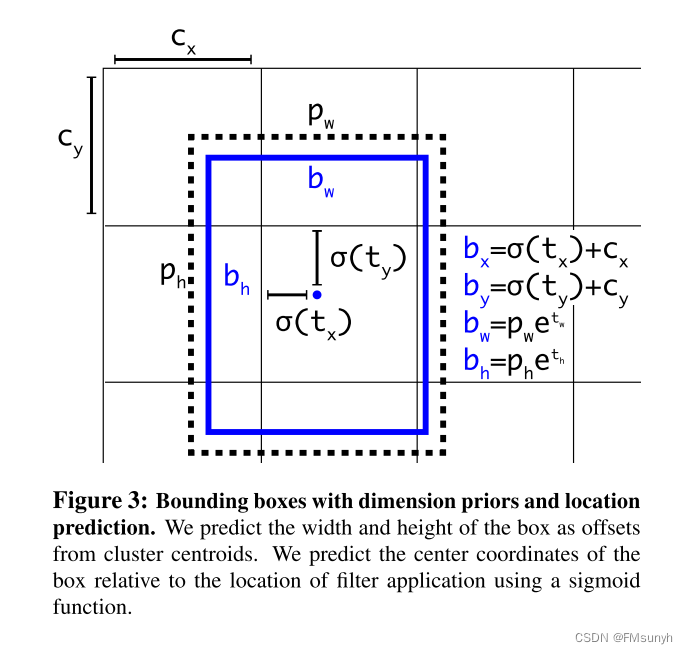
预测框,模型预测出来的结果是? 就是我们的网络,最后一层输出的值,
网络最后一层输出值:
第一步结果: t x , t y , t w , t h 第一步结果:t_x,t_y,t_w,t_h\\ 第一步结果:tx,ty,tw,th
从yolov1那里,我们是可以知道,
t x , t y , t w , t h t_x,t_y,t_w,t_h\\ tx,ty,tw,th是可以直接用来当做最终的预测框,但作者在yolov2中,引入anchor计算的机制,采用归一化,anchor转换,得到最终预测框。
归一化处理:
第二步结果: σ ( t x ) , σ ( t y ) , ℮ t w , ℮ t h 第二步结果:\sigma\left(t_x\right),\sigma\left(t_y\right),℮^{t_w},℮^{t_h}\\ 第二步结果:σ(tx),σ(ty),℮tw,℮th
σ 是 s i g m o i d 函数, , ℮是 l o g 函数,论文没有直接给出 \sigma是sigmoid函数, ,℮是log函数,论文没有直接给出 \\ σ是sigmoid函数,,℮是log函数,论文没有直接给出
为什么要归一化处理,不做行不行,答案是行的,放进去做实验,可能模型在收敛和精度上,有比较大的差别。
转换处理:
第三步结果: b x = σ ( t x ) + c x b y = σ ( t y ) + c y b w = p w ℮ t w b h = p h ℮ t h 第三步结果:\\ b_x= \sigma\left(t_x\right)+c_x\\ b_y= \sigma\left(t_y\right)+c_y\\ b_w= p_w℮^{t_w}\\ b_h= p_h℮^{t_h}\\ 第三步结果:bx=σ(tx)+cxby=σ(ty)+cybw=pw℮twbh=ph℮th
b x , b y , b w , b h 就是我们最终得到的框,就像手工标注的框一样 . b_x,b_y,b_w,b_h 就是我们最终得到的框,就像手工标注的框一样.\\ bx,by,bw,bh就是我们最终得到的框,就像手工标注的框一样.
其中
p w , p h 是 a n c h o r 的宽和高, c x , c y 是格子的左上角坐标 . (下文,进一步解析这四个参数值,是已知的,固定的) p_w,p_h是anchor的宽和高,c_x,c_y是格子的左上角坐标. \\ (下文,进一步解析这四个参数值,是已知的,固定的) pw,ph是anchor的宽和高,cx,cy是格子的左上角坐标.(下文,进一步解析这四个参数值,是已知的,固定的)
第一个问题,小结:
从模型计算出来的计算,经过第一、二、三步,最后才得到我们想要的预测框(就像手工标准的那种框)。
第三个问题
数据处理,GT值如何计算出来?
第一,先来看看输入到loss函数的预测值是什么?
在前面,我们谈到,预测值,有三个阶段的值,可以作为预测输出,但取哪一个送到loss中呢?
答案:
σ ( t x ) , σ ( t y ) , ℮ t w , ℮ t h \sigma\left(t_x\right),\sigma\left(t_y\right),℮^{t_w},℮^{t_h}\\ σ(tx),σ(ty),℮tw,℮th
这个数值,将会作为预测值输入给loss。
第二, 如何得到对应的GT值呢?
一个GT框,分2部分: x, y和w,h。
为什么要这样分? 因为获取x,y,w,h的值,方式是不同的,这个地方很绕,容易忘记。
先看x, y
一张416x416的图上,可以生成13x13x5个anchor,也就是每个格子里面,先画5个anchor(锚框)。下图是7x7格子的路,来自yolov1的论文。

假设,我想要输入loss的target是这样的:
t a r g e t x , t a r g e t y , t a r g e t w , t a r g e t h target_x,target_y,target_w,target_h\\ targetx,targety,targetw,targeth
开始计算
t a r g e t x , t a r g e t y target_x,target_y\\ targetx,targety
计算步骤:
Step1: 计算GT真实框的中心点坐标,落在哪个gird(格子),称之为中标格子
Step2: 每个格子的宽度(宽和高相等):
g i r d w = 416 13 = 32 gird_w = \frac{416}{13} = 32\\ girdw=13416=32
Step3:
t a r g e t x = σ ( t x ) = G T 真实框中心点坐标 x − 中标格子左上角 x g i r d w target_x=\sigma\left(t_x\right) = \frac{GT\mathrm{真实框中心点坐标}x-\mathrm{中标格子左上角}x}{gird_w}\\ targetx=σ(tx)=girdwGT真实框中心点坐标x−中标格子左上角x
这个值,就是我们要给loss函数送的GT值。
同理可以得到:
t a r g e t y = σ ( t y ) = G T 真实框中心点坐标 y − 中标格子左上角 y g i r d h target_y=\sigma\left(t_y\right) = \frac{GT\mathrm{真实框中心点坐标}y-\mathrm{中标格子左上角}y}{gird_h}\\ targety=σ(ty)=girdhGT真实框中心点坐标y−中标格子左上角y
到这里,可以发现,计算
t a r g e t x , t a r g e t y target_x,target_y\\ targetx,targety
整个计算过程与5个anchor没有任何联系,并没有用到anchor的数值。
但,可以注意到一个信息,中标格子左上角的坐标,其实就是anchor的中心坐标,这个理解在代码里面很关键,因为有的代码实现,用到这个技巧,阅读代码的时候,要灵活转过来。
这也是格子和anchor一个很密切的关联。
再来看看,w, h
前面我们已经假设,要输入loss的target是这样的:
t a r g e t x , t a r g e t y , t a r g e t w , t a r g e t h target_x,target_y,target_w,target_h\\ targetx,targety,targetw,targeth
开始计算
t a r g e t w , t a r g e t h target_w,target_h\\ targetw,targeth
如何得到这两个数值呢?
- 直接等于GT真实框的w,h? 不是!
- 等于某个anchor的w,h? 不是!
- 格子,anchor,GT框的转换关系,又是怎么样的?
引入anchor的目的? 如何怎么用?
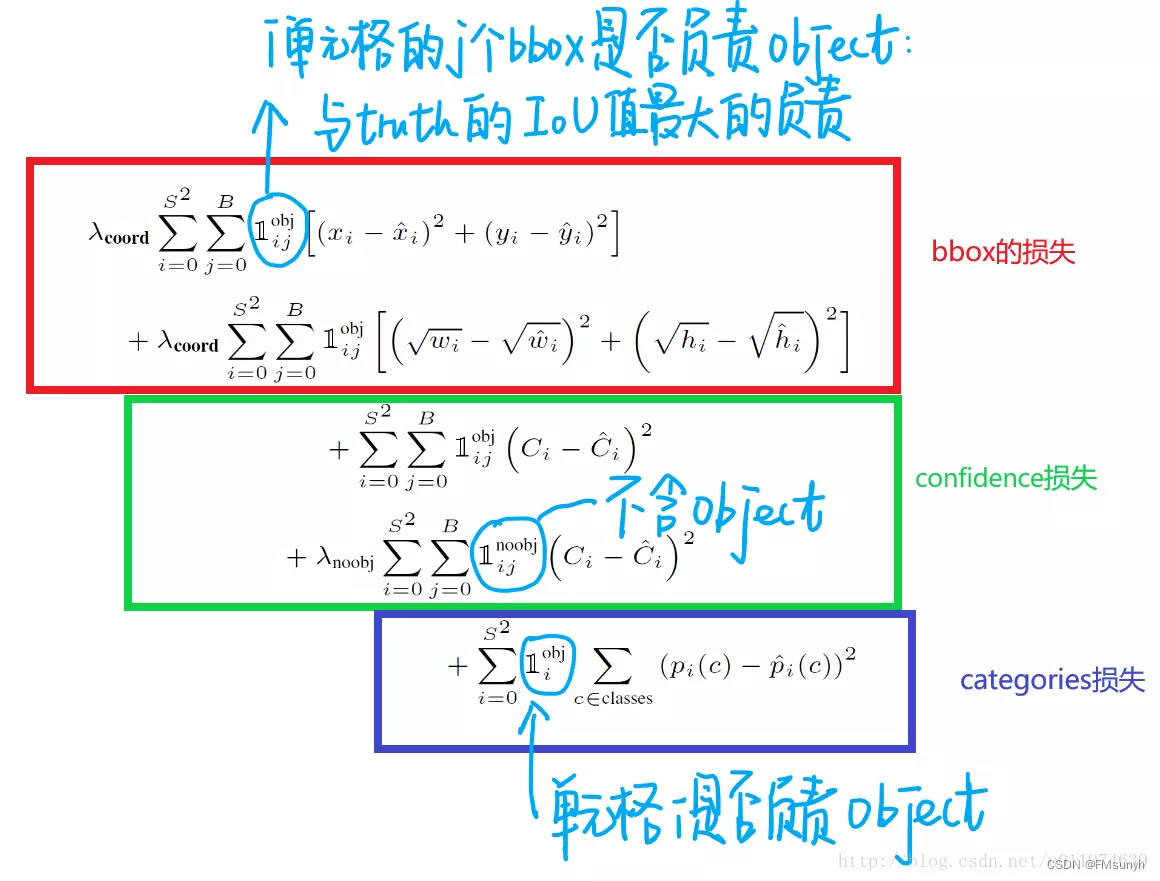
在谈论anchor之前,先来明确一下,yolo中,计算框和分类的loss,只考虑有目标的情况,即:只计算正样本,不考虑负样本。计算置信度的时候同时考虑正负样本。
回顾yolov1
在yolov1中,一个gt框,直接作为loss的gt target,计算loss,网络出来有2个预测框,用哪一个框和GT框计算loss呢?这是yolov1比较容易忘记的细节:
计算2个预测框与GT框的IOU,IOU大的一方,取的胜利,用来计算和GT框的loss,另外一个就是计算no object。
FasterRCNN
到了yolov2,并没有直接将GT 框送到loss,而是与anchor做了转换后,才送进去,如何转换?
anchor的引入是从Faster RCNN而来,先来看看FasterRCNN中是怎么样使用anchor的:
1) anchor与GT计算IOU,得到网络的输入: IOU在大于0.7的anchor就是 正样本(前景),在0.1~0.3之间的作为负样本(背景),0.3 ~0.5之间的忽略掉 直接使用anchor作为输入的框,类别是1(前景,有目标),0(背景,无目标)。
2) 通过RPN网络从feature map得到候选框ROIs,并对ROIs进行二分类,判别候选框内容是前景还是背景,留下前景的候选框,抛弃背景候选框,并通过回归微调前景的BBox与标注gt接近。
3) 两个loss, rpn loss计算框loss: anchor与预测值,类别loss:0,1是否有目标,rcnn loss,rpn预测出来的前景与GT框的loss,类别有N类。
以上,就是anchor在Faster RCNN中的应用, 可以看到anchor的使用,让模型在rpn阶段得到了 大量的前景框,比较接近GT框了,同时也去掉了大量的背景框,最后把RPN预测出来的前景框送到RCNN阶段,进行微调修正,准确率非常的高,速度是慢一些。
yolov2
在yolov2中,又是怎么样使用anchor的呢?
在yolov2中,预设了5个anchor,其中只有一个anchor与GT框是有目标关系,另外4个anchor是无目标关系,没有目标也就不参与loss计算。
到这里可以再看一下yolov1,有anchor和没有anchor好像没有太大的本质区别,因为正样本,只有一个,也是通过网格去找这个GT框,唯一可以往下思考的是anchor带来了先验的概念。
模型从找一个具体的框,变成找一个微调的框,这个地方,我无法理解他的效果为什么就会变好。
如果从负样本的角度来看,他多了4个负样本,而且是明确的先验框,这点是比yolov1强的。
同时,在计算置信度得分时,会考虑正负样本,yolov1是1:1的关系,yolov2是1:4的关系,当然,这中间,还有忽略掉 IOU>0.6的anchor,这个处理能理解,因为已经有最大的IOU-anchor了,其他的anchor大于阀值0.6,但不能把他们当做正样本了,也不能当做负样本,所以忽略掉,不要这样的anchor参与loss计算,这些都是很细小的处理。
有了上面的理解,来看看anchor和gt的关系,然后计算出:
t a r g e t w = ℮ t w = G T 框 w a n c h o r w , t a r g e t h = ℮ t h = G T 框 h a n c h o r h , target_w=℮^{t_w}=\frac{GT框_w}{anchor_w},target_h=℮^{t_h}=\frac{GT框_h}{anchor_h}, targetw=℮tw=anchorwGT框w,targeth=℮th=anchorhGT框h,
通过观察,我们发现,
每个格子的左上角这个点,就是anchor的中心点.