1. 创建RDD
创建RDD有两种方式:
1) 测试:通过并行化一个已经存在的集合,转化成RDD;
2) 生产:引用一些外部的数据集(共享的文件系统,包括HDFS、HBase等支持Hadoop InputFormat的都可以)。
1.1 第一种方式创建RDD: Parallelized Collection
[hadoop@hadoop01 ~]$ spark-shell --master local[2]
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
18/07/12 22:30:58 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
18/07/12 22:31:05 WARN ObjectStore: Failed to get database global_temp, returning NoSuchObjectException
Spark context Web UI available at http://10.132.37.38:4040
Spark context available as 'sc' (master = local[2], app id = local-1531405859803).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.2.0
/_/
Using Scala version 2.11.8 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_45)
Type in expressions to have them evaluated.
Type :help for more information.
scala> val data = Array(1, 2, 3, 4, 5) # 定义一个数组
data: Array[Int] = Array(1, 2, 3, 4, 5)
scala> val distData = sc.parallelize(data) // 把这个数组转化成RDD。这一步只是类型转换,不触发job的执行
distData: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at <console>:26
// 这里注明了RDD泛型类型是Int类型的,是因为data在定义时就是一个Int类型的数组
scala> 把数组转换成RDD的过程是一个类型转换,不触发job的执行。此时查看Spark Web UI,是没有任何内容的。
调用.collect方法执行以下,触发job的执行。
scala> distData.collect
res0: Array[Int] = Array(1, 2, 3, 4, 5)
scala> 再查看Spark Web UI,网页下方会显示这个job。
观察这里的Task的数量是2,因为spark源码中,task默认值定义的是2。这个默认值可以修改。

继续rdd的使用
scala> distData.reduce((a, b) => a + b)
res1: Int = 15 // 数组求和
scala> 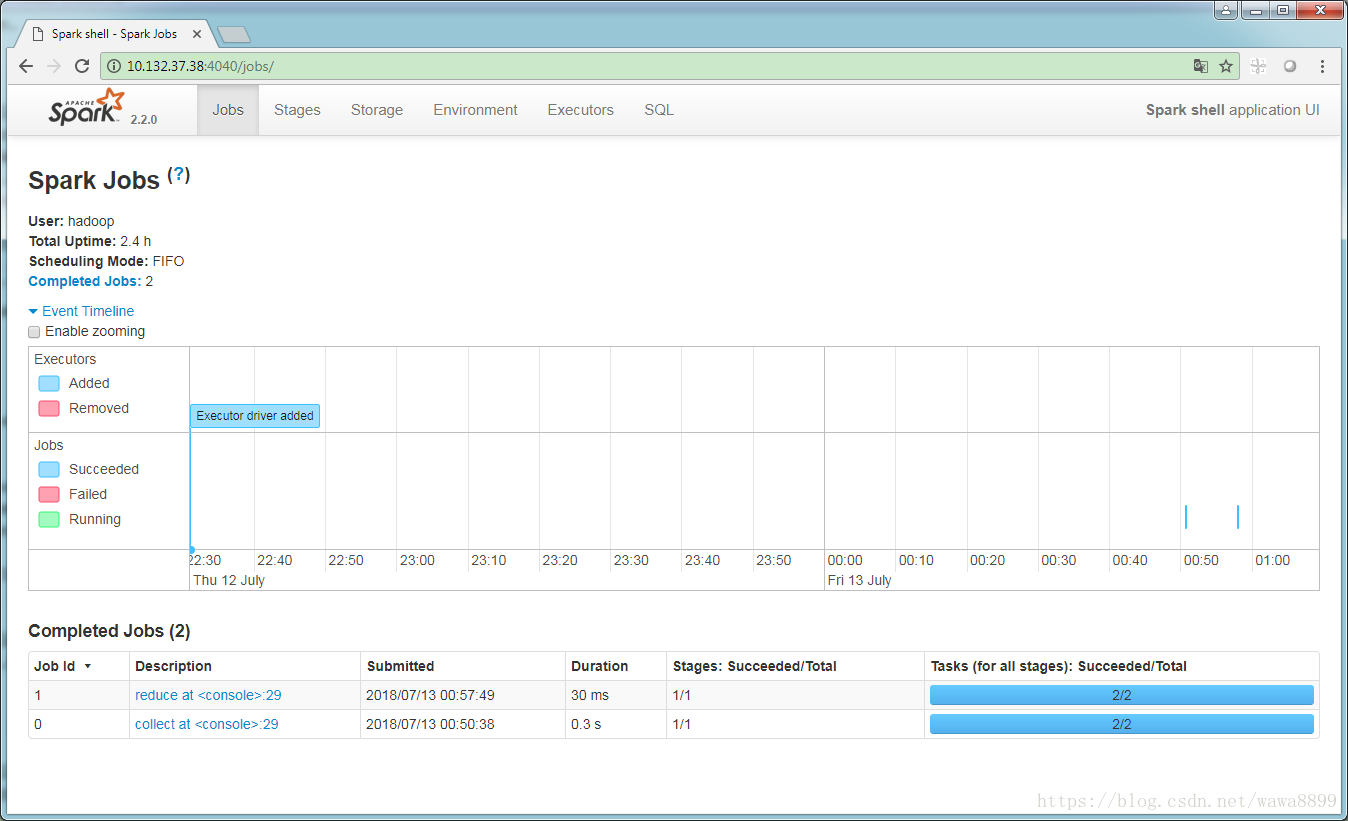
scala> val distData = sc.parallelize(data,5) // 这里的第二个参数5,是task的数量
distData: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[2] at parallelize at <console>:26
scala> distData.collect
res2: Array[Int] = Array(1, 2, 3, 4, 5)
scala> 
观察到网页上最后一个job,task数量是5,而前两个job,task是2。
在Spark中,partition数量 = task数量,5个partitions = 5个tasks。生产中通常给一个CPU设置2-4个partition,这样不会造成太多的资源浪费。
1.2. 第二种方式创建RDD: External Datasets
1.2.1 本地文件转换RDD
准备一个本地文件
[hadoop@hadoop01 data]$ pwd
/home/hadoop/data
[hadoop@hadoop01 data]$ cat input.txt
this is test data
this is test sample
[hadoop@hadoop01 data]$ 去spark-shell里面把文件里面的数据读取出来并输出
scala> val distFile = sc.textFile("file:///home/hadoop/data/input.txt") // 本地文件导入到rdd
distFile: org.apache.spark.rdd.RDD[String] = file:///home/hadoop/data/input.txt MapPartitionsRDD[6] at textFile at <console>:24
// 此时的rdd是String类型
scala> distFile.collect // 把rdd的内容输出一下
res3: Array[String] = Array(this is test data, this is test sample)
scala> rdd里面所有的元素的长度求和
scala> distFile.map(s => s.length).reduce((a, b) => a + b)
res4: Int = 38
scala> 1.2.2 HDFS文件转换RDD
已有HDFS文件
[hadoop@hadoop01 data]$ hdfs dfs -put input.txt /tmp/
[hadoop@hadoop01 data]$ hdfs dfs -cat /tmp/input.txt
this is test data
this is test sample
[hadoop@hadoop01 data]$ 导入Spark
scala> val distFile = sc.textFile("hdfs://10.132.37.38:9000/tmp/input.txt")
distFile: org.apache.spark.rdd.RDD[String] = hdfs://10.132.37.38:9000/tmp/input.txt MapPartitionsRDD[13] at textFile at <console>:24
scala> distFile.collect
res7: Array[String] = Array(this is test data, this is test sample)
scala> 2. 创建RDD的注意事项

1) 如果使用本地文件系统读文件到rdd,需要把数据文件拷贝到每个节点,并且路径一样;
2) textFile支持读文件、读文件夹,甚至压缩文件,还支持通配符;
3) textFile的第二个参数(textFile minPartitions)可以控制partition的数量,默认情况下spark只为每个block(默认128M)创建一个partition;
其他格式的数据支持:
4) SparkContext.wholeTextFiles支持读取文件夹里面的多个小文件,返回的数组里面(filename, content)格式;
已有hdfs数据文件夹
[hadoop@hadoop01 data]$ cat input.txt
this is test data
this is test sample
[hadoop@hadoop01 data]$ cat input1.txt
this is test data
[hadoop@hadoop01 data]$ cat input2.txt
this is test sample
[hadoop@hadoop01 data]$ hdfs dfs -put input.txt /tmp/data
[hadoop@hadoop01 data]$ hdfs dfs -put input1.txt /tmp/data
[hadoop@hadoop01 data]$ hdfs dfs -put input2.txt /tmp/data
[hadoop@hadoop01 data]$ hdfs dfs -ls /tmp/data
Found 3 items
-rw-r--r-- 1 hadoop supergroup 40 2018-07-13 01:58 /tmp/data/input.txt
-rw-r--r-- 1 hadoop supergroup 19 2018-07-13 01:58 /tmp/data/input1.txt
-rw-r--r-- 1 hadoop supergroup 21 2018-07-13 01:58 /tmp/data/input2.txt
[hadoop@hadoop01 data]$ 导入到rdd
scala> val rdd = sc.wholeTextFiles("hdfs://10.132.37.38:9000/tmp/data")
rdd: org.apache.spark.rdd.RDD[(String, String)] = hdfs://10.132.37.38:9000/tmp/data MapPartitionsRDD[17] at wholeTextFiles at <console>:24
scala> rdd.collect
res9: Array[(String, String)] =
Array((hdfs://10.132.37.38:9000/tmp/data/input.txt,"this is test data
this is test sample
"), (hdfs://10.132.37.38:9000/tmp/data/input1.txt,"this is test data
"), (hdfs://10.132.37.38:9000/tmp/data/input2.txt,"this is test sample
"))
scala> 这种情况下返回的数组里面每一对值,前面的是文件的名称,后面的是文件的具体内容;
5) SequenceFiles,可以从hive里面读一个sequencefile出来;
历史原因:Hive中有些表是采用SeqienceFile存储,现在我们想使用Spark Core来作为分布式计算框架。
作业:Spare Core读取SequenceFile文件
6) 其他Hadoop InputFormats可以使用SparkContext.hadoopRDD方法;
7) RDD.saveAsObjectFile and SparkContext.objectFile支持包含序列化Java对象的简单格式保存RDD。