这两天把要前几天的知识点回顾一下,接下来我会用自己对知识点的理解来写一些东西
一、知识点回顾
1.hbase集群启动:$>start-hbase.sh ===>hbase-daemon.sh start hmaster + hbase-daemon.sh start regionserver
hbase集群关闭:$>stop-hbase.sh ===>hbase-daemon.sh staop hmaster +hbase-daemon.sh stop regionserver //注意字母都是小写的
2.预先切割:在创建表时预先对表进行切割,切割之后将其中的表移动到别的服务器上去,以后插入的时候就直接进入该区域,切割线是rowkey:$hbase>create 'ns1:t2' ,'f1',SPLITS['row3000','row6000']
查看列信息: scan 'ns1:t2'
查看切片信息:scan 'hbase:meta'
删除某一列的数据: delete 'ns1:t1', 'r1', 'c1', ts1
scan原生扫描(专家级操作):$hbase>scan 'ns2:t1',{COLUMN=>'f1',RAW=>true,VERSIONS=>10} //原生扫描的时候包含了删除的标记
.通过scan来扫描表,scan可以根据rowkey,cf,column,timestamp,filter来获取方式,第一种方式通过rowkey的方式可以指定startrow和endrow,也可以指定具体的某个行键去获取数据,在源码中也指出了如果具体指定了rowkey,那么会只是扫描那一段的数据,具体的可以去看我上一篇博客<hbase学习笔记之scan源码研究>,hbase底层存储数据是根据rowkey的字典顺序存储数据的,所以如果使用rowkey的方式去查找,scan就可以顺序查找,大大缩短了时间。第二种就是根据timestamp去查找,对于这个时间戳,特别注意的是指的是存入hbase中的时间,在存入时,对应的cell中会记录下来。而不是客户端插入的数据的时间,这里肯定会有一定的使时间偏移,但相差不会很大。对于timestamp的方式来说,它也是只是去扫描对应范围或者对应某个时间戳去获取。
3.VERSIONS版本
创建列族的时候指定版本数,该列族的所有列具有相同数量的版本
$hbase> create 'ns1:t3',{NAME=>'f1',VERSIONS=>3} //创建列
$hbase>get 'ns1:t3','row1',{COLUMN=>'f1',VERSIONS=>3} //检索的时候查询的版本
4.TTL(time to live ):用于限定数据的超时时间,TTL是影响所有的数据,包括没有被删除的数据,一旦超过这个时间的话,就会被删除,原生扫描也扫不到数据。
5.缓存和批处理:对于每个next()调用都会为每行数据生成一个单独的RPC请求,即使使用next()方法,也是如此,因为该方法仅仅是在客户端调用next()方法,因此当单元格数据比较小的时候,这样的性能不会很好。所以一次RPC请求如果可以获取比较多得数据的时候,这就更加的有意义,这样的方法可以用扫描器缓存来实现,默认情况下,这个扫描器是关闭的。
1)开启服务器端的扫描器缓存,扫描器缓存是面向行这一级别的
a)表层面:
<property>
<name>hbase.client.scanner.caching</name>
<!-- 整数最大值 -->
<value>2147483647</value>
<source>hbase-default.xml</source>
</property>
b)操作层面:
setCaching = 10 ;
2)批量扫描是面向列级别的。批量可以让用户选择每次ResultScanner实例的next()操作每次取回多少列。比如在扫描设置中设置setBatch(5),则一次next()返回result的实例会包括5列
scan.setBatch(5); //每次next()会返回5列
实例:先创建有两个列族的表:$hbase>create 'ns1:t3','f1','f2'
public void testBatchAndCaching() throws IOException { Configuration conf = HBaseConfiguration.create(); Connection conn = ConnectionFactory.createConnection(conf); TableName tableName = TableName.valueOf("ns1:t7"); Scan scan=new Scan(); //每次缓存多少行数据 scan.setCaching(2); //将缓存的行数据切分4列,每次调用就会返回每行数据的4列数据 scan.setBatch(4); Table table = conn.getTable(tableName); ResultScanner rs = table.getScanner(scan); Iterator<Result> iterator = rs.iterator(); while(iterator.hasNext()){ Result r = iterator.next(); //得到一行的所有map,key=f1,value=Map<Col,Map<Timestamp,value>> NavigableMap<byte[], NavigableMap<byte[], NavigableMap<Long, byte[]>>> map = r.getMap(); for(Map.Entry<byte[], NavigableMap<byte[], NavigableMap<Long, byte[]>>> entry:map.entrySet()){ //得到列族 String f = Bytes.toString(entry.getKey()); NavigableMap<byte[], NavigableMap<Long, byte[]>> colDataMap = entry.getValue(); for(Map.Entry<byte[], NavigableMap<Long, byte[]>> ets:colDataMap.entrySet()){ String c = Bytes.toString(ets.getKey()); NavigableMap<Long, byte[]> tsValueMap = ets.getValue(); for(Map.Entry<Long, byte[]> e :tsValueMap.entrySet()){ Long ts = e.getKey(); String value = Bytes.toString(e.getValue()); System.out.print(f + "/" + c + "/" + ts + "=" + value + ","); } } } System.out.println(); } }
二、过滤器
首先我们要了解HBase中过滤器的主要功能是为了筛选掉没有用的信息,被过滤的信息不回传递到客户端,过滤器不能用来指定用户需要哪些信息,而是在读取数据的过程中不返回用户不需要的信息。但是正好相反,所有基于CompareFilter的过滤器过滤处理的过程与上述描述的刚好是相反的,比如用户需要大于或等于某值的数据,就应该使用GREATER_OR_EQUAL来挑选所需要的数据。
1.比较过滤器。
HBase过滤器提供了非常强大的特性来帮助用户提高其处理表中数据的能力,我们不急可以使用HBase中定义好的过滤器,而且可以实现自定义过滤器。在HBase中两种主要的读取函数是get()和scan()函数,他们都支持直接访问数据和指定起止行键访问数据的功能,get()和scan()这两个类都支持过滤器,因为这列对象提供的基本API不能对行键,列名,列值进行过滤,但是通过过滤器可以达到基本的目的。同时我们还可以通过继承Filter类来实现自己的需求,所有的过滤器在服务端生效叫做为此下推,保证被过滤掉的数据不被传送到客户端,下图描述了怎样在客户端进行配置,怎样在网络中被序列化,怎样在服务端进行执行。
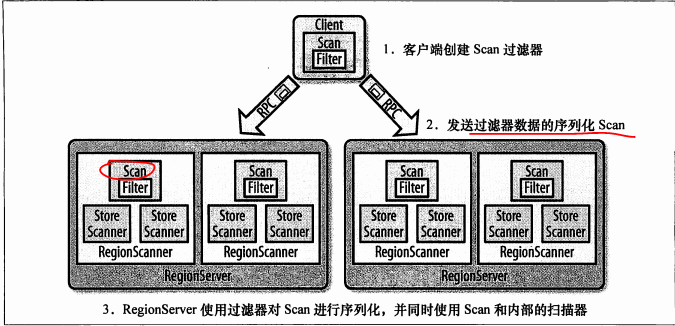
如上图,客户端在创建扫描器的时候可以把过滤器附加上,通过RPC发送给远程服务器,远程服务器会受到Scan对象,进行反序列化,在过滤器中是对每个区域进行过滤的,区域服务器里面有很多的区域,区域里面有区域扫描器,区域服务器使用过滤器对Scan进行序列化,并同时使用scan和内部扫描器。
2.过滤器的层次结构:
在过滤器层次结构的最底层是Filter接口和FilterBase抽象类,他们实现了过滤器的空壳和骨架,这使得实际的过滤器类可以避免许多重复的结构代码。他们的使用流程差不多,用户定义一个所需要的过滤器实例,把定义好的过滤器实例传递给get或者scan实例,setFilter(filter);
3.比较运算符。因为继承自Comparator的过滤器比基类多一个compare(0方法,他需要使用传入参数定义比较操作的过程。
4.比较过滤器:对于比较过滤器而言,用户需要提供比较运算符和比较过滤器来让过滤器工作。
1.1)行过滤器:RowFilter,基于行键来过滤数据,使用多种比较运算符来返回符合条件的行键,同时会过滤掉不符合条件的行键
//本方法实现测试行过滤器,指定比较运算符和比较器,需要精确匹配 @Test public void testRowFilter() throws Exception { //创建配置对象 Configuration conf = HBaseConfiguration.create(); //创建连接 Connection conn = ConnectionFactory.createConnection(conf); // TableName tname = TableName.valueOf("ns1:t4"); Table table = conn.getTable(tname); Scan scan = new Scan(); RowFilter rf = new RowFilter(CompareFilter.CompareOp.LESS_OR_EQUAL,new BinaryComparator(Bytes.toBytes("row0100"))); scan.setFilter(rf); ResultScanner rs = table.getScanner(scan); Iterator<Result> it = rs.iterator(); while (it.hasNext()){ Result r = it.next(); System.out.println((r.getColumnLatestCell(Bytes.toBytes("f1"),Bytes.toBytes("name")))); } }
1.2)列族过滤器:FamilyFilter
通过比较列族来返回结果,使用不同组合的运算符和比较器,来筛选在列族一级的数据
//本方法实现测试列族过滤器 @Test public void testFamilyFilter() throws Exception { //创建配置 Configuration conf =HBaseConfiguration.create(); //创建连接 Connection conn = ConnectionFactory.createConnection(conf); TableName tname = TableName.valueOf("ns1:t3"); Table table = conn.getTable(tname); Scan scan = new Scan(); FamilyFilter familyFilter = new FamilyFilter(CompareFilter.CompareOp.LESS,new BinaryComparator(Bytes.toBytes("f2"))); scan.setFilter(familyFilter); ResultScanner rs =table.getScanner(scan); Iterator<Result> it = rs.iterator(); while(it.hasNext()){ Result r = it.next(); byte[] f1id = r.getValue(Bytes.toBytes("f1"),Bytes.toBytes("id")); byte[] f2id = r.getValue(Bytes.toBytes("f2"),Bytes.toBytes("id")); byte[] f1name= r.getValue(Bytes.toBytes("f1"),Bytes.toBytes("name")); byte[] f2name = r.getValue(Bytes.toBytes("f2"),Bytes.toBytes("name")); System.out.println("f1id:"+f1id+"; f2id:"+f2id); } }
1.3)列过滤器:QualifierFilter
@Test public void testQualifierFilter() throws Exception { //配置 Configuration conf = HBaseConfiguration.create(); //创建连接 Connection conn = ConnectionFactory.createConnection(conf); // TableName tname =TableName.valueOf("ns1:t4"); //创建表 Table table = conn.getTable(tname); //创建扫描器 Scan scan = new Scan(); QualifierFilter qualifierFilter = new QualifierFilter(CompareFilter.CompareOp.EQUAL, new BinaryComparator(Bytes.toBytes("id")) ); scan.setFilter(qualifierFilter); ResultScanner rs = table.getScanner(scan); Iterator<Result> it =rs.iterator(); while(it.hasNext()){ Result r = it.next(); byte[] f1id = r.getValue(Bytes.toBytes("f1"),Bytes.toBytes("id")); byte[] f2id = r.getValue(Bytes.toBytes("f2"),Bytes.toBytes("id")); byte[] f1name= r.getValue(Bytes.toBytes("f1"),Bytes.toBytes("name")); byte[] f2name = r.getValue(Bytes.toBytes("f2"),Bytes.toBytes("name")); System.out.println("f1id:"+f1id+"; f2id:"+f2id); } }
1.4)值过滤器:ValueFilter,这个过滤器可以帮助用户选用某个特定值的单元格
//测试值过滤器 @Test public void testValueFilter() throws Exception { Configuration conf = HBaseConfiguration.create(); Connection conn = ConnectionFactory.createConnection(conf); TableName tableName = TableName.valueOf("ns1:t3"); Table table = conn.getTable(tableName); Scan scan = new Scan(); ValueFilter valueFilter = new ValueFilter(CompareFilter.CompareOp.EQUAL, new SubstringComparator("ack") ); scan.setFilter(valueFilter); ResultScanner rs = table.getScanner(scan); Iterator<Result> it =rs.iterator(); while(it.hasNext()){ Result r = it.next(); byte[] f1id = r.getValue(Bytes.toBytes("f1"),Bytes.toBytes("id")); byte[] f2id = r.getValue(Bytes.toBytes("f2"),Bytes.toBytes("id")); byte[] f1name= r.getValue(Bytes.toBytes("f1"),Bytes.toBytes("name")); byte[] f2name = r.getValue(Bytes.toBytes("f2"),Bytes.toBytes("name")); System.out.println("f1id:"+f1id+"; f2id:"+f2id); System.out.println("f1Name:"+f1name+"; f2name:"+f2name); } }
2.专用过滤器:继承自FilterBase,用于更特定的使用场景,
2.1)单列值过滤器:SingleColumnValueFilter,用一列的值决定是否一行数据被过滤。先设置待检查的列,然后再设置待检查列的对应值,具体的构造如下:
(1):SingColumnValueFilter(byte[] family,byte[] qualifier,CompareOp compareop ,byte[] value)
这个构造比较简单,只在内部创建一个BinaryComparator实例,
(2)SingleColumnValueFilter(byte[] family,byte[] qualifier,CompareOp compareop,WritableByteArrayComparable comparator)
构造函数中所需的参数与用户一直在使用的基于CompareFilter的类相同,尽管SingleColumnValueFilter并不是直接继承自CompareFilter,但是还是使用了相同的参数类型
@Test public void testSingleColumValueFilter() throws IOException { Configuration conf = HBaseConfiguration.create(); Connection conn = ConnectionFactory.createConnection(conf); TableName tname = TableName.valueOf("ns1:t7"); Scan scan = new Scan(); SingleColumnValueFilter filter = new SingleColumnValueFilter(Bytes.toBytes("f2", Bytes.toBytes("name"), CompareFilter.CompareOp.NOT_EQUAL), new BinaryComparator(Bytes.toBytes("tom2.1"))); //ValueFilter filter = new ValueFilter(CompareFilter.CompareOp.EQUAL, new SubstringComparator("to")); scan.setFilter(filter); Table t = conn.getTable(tname); ResultScanner rs = t.getScanner(scan); Iterator<Result> it = rs.iterator(); while (it.hasNext()) { Result r = it.next(); byte[] f1id = r.getValue(Bytes.toBytes("f1"), Bytes.toBytes("id")); byte[] f2id = r.getValue(Bytes.toBytes("f2"), Bytes.toBytes("id")); byte[] f1name = r.getValue(Bytes.toBytes("f1"), Bytes.toBytes("name")); byte[] f2name = r.getValue(Bytes.toBytes("f2"), Bytes.toBytes("name")); System.out.println(f1id + " : " + f2id + " : " + Bytes.toString(f1name) + " : " + Bytes.toString(f2name)); } } 复杂查询 ----------------- select * from t7 where ((age <= 13) and (name like '%t') or (age > 13) and (name like 't%')) FilterList ---------------- @Test public void testComboFilter() throws IOException { Configuration conf = HBaseConfiguration.create(); Connection conn = ConnectionFactory.createConnection(conf); TableName tname = TableName.valueOf("ns1:t7"); Scan scan = new Scan(); //where ... f2:age <= 13 SingleColumnValueFilter ftl = new SingleColumnValueFilter( Bytes.toBytes("f2"), Bytes.toBytes("age"), CompareFilter.CompareOp.LESS_OR_EQUAL, new BinaryComparator(Bytes.toBytes("13")) ); //where ... f2:name like %t SingleColumnValueFilter ftr = new SingleColumnValueFilter( Bytes.toBytes("f2"), Bytes.toBytes("name"), CompareFilter.CompareOp.EQUAL, new RegexStringComparator("^t") ); //ft FilterList ft = new FilterList(FilterList.Operator.MUST_PASS_ALL); ft.addFilter(ftl); ft.addFilter(ftr); //where ... f2:age > 13 SingleColumnValueFilter fbl = new SingleColumnValueFilter( Bytes.toBytes("f2"), Bytes.toBytes("age"), CompareFilter.CompareOp.GREATER, new BinaryComparator(Bytes.toBytes("13")) ); //where ... f2:name like %t SingleColumnValueFilter fbr = new SingleColumnValueFilter( Bytes.toBytes("f2"), Bytes.toBytes("name"), CompareFilter.CompareOp.EQUAL, new RegexStringComparator("t$") ); //ft FilterList fb = new FilterList(FilterList.Operator.MUST_PASS_ALL); fb.addFilter(fbl); fb.addFilter(fbr); FilterList fall = new FilterList(FilterList.Operator.MUST_PASS_ONE); fall.addFilter(ft); fall.addFilter(fb); scan.setFilter(fall); Table t = conn.getTable(tname); ResultScanner rs = t.getScanner(scan); Iterator<Result> it = rs.iterator(); while (it.hasNext()) { Result r = it.next(); byte[] f1id = r.getValue(Bytes.toBytes("f1"), Bytes.toBytes("id")); byte[] f2id = r.getValue(Bytes.toBytes("f2"), Bytes.toBytes("id")); byte[] f1name = r.getValue(Bytes.toBytes("f1"), Bytes.toBytes("name")); byte[] f2name = r.getValue(Bytes.toBytes("f2"), Bytes.toBytes("name")); System.out.println(f1id + " : " + f2id + " : " + Bytes.toString(f1name) + " : " + Bytes.toString(f2name)); } }