1.关于非线性转化方程(non-linear transformation function)
sigmoid函数(S曲线)用来作为activation function:
1.1 双曲函数(tanh)
1.2 逻辑函数(logistic function)
sigmoid 函数:
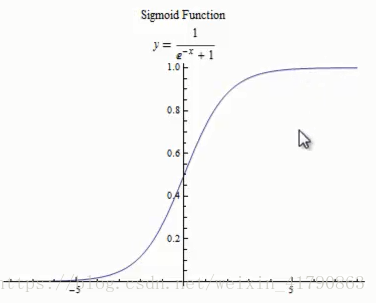
sigmoid 函数是一个s型函数,sigmoid 函数的数学公式为:
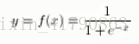
双曲函数: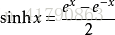
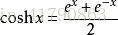

双曲函数的导数:
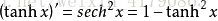
图像:

逻辑函数:
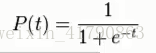
逻辑函数的导数:

图像:

2.实现一个简单的神经网络算法
NeuralNetwork.py:
# coding=utf-8
import numpy as np
def tanh(x):
return np.tanh(x)
def tanh_deriv(x):
return 1.0 - np.tanh(x) * np.tanh(x) # tanh函数的导数
def logistic(x):
return 1 / (1 + np.exp(-x)) # 逻辑函数
def logistic_derivative(x):
return logistic(x) * (1 - logistic(x)) # 逻辑函数的导数,用来计算权重的更新
class NeuralNetwork:
def __init__(self, layers, activation='tanh'): # 构造函数,self相当于指针
'''
:param layers: 列表,包含了每一层的神经元个数
:param activation: 激活函数的选择
'''
if activation == 'logistic':
self.activation = logistic
self.activation_deriv = logistic_derivative
elif activation == 'tanh':
self.activation = tanh
self.activation_deriv = tanh_deriv
self.weights = []
for i in range(1, len(layers) - 1): # 从第一层到最后的输出的前一层,都要赋予一个初始权重
self.weights.append(
(2 * np.random.random((layers[i - 1] + 1, layers[i] + 1)) - 1) * 0.25) # 对i层与i-1层之间的权重进行随机的赋值
self.weights.append(
(2 * np.random.random((layers[i] + 1, layers[i + 1])) - 1) * 0.25) # 对i层与i+1层之间的权重进行随机的赋值 -0.25到0.25之间
def fit(self, X, y, learning_rate=0.2, epochs=10000):
'''
:param X: 二维矩阵,每一行对应一个实例,列数代表了特征数
:param y: 标签
:param learning_rate:
:param epochs: 达到预设的循环次数,最多循环10000次
:return:
'''
X = np.atleast_2d(X) # 确认x的维度最少为2维数组
temp = np.ones([X.shape[0], X.shape[1] + 1]) # 初始化矩阵全是1(行数,列数+1是为了有偏置b)
temp[:, 0:-1] = X # 行全选,第一列到倒数第二列
X = temp # 主要是偏置的赋值
y = np.array(y) # 转化为数组的形式,数据结构转换
for k in range(epochs):
i = np.random.randint(X.shape[0]) # 随机抽取一行
a = [X[i]]
for l in range(len(self.weights)):
a.append(self.activation(np.dot(a[l], self.weights[l]))) # 内积实现加权求和,activation实现非线性转换
# 向前传播,得到每个节点的输出结果
error = y[i] - a[-1]
deltas = [error * self.activation_deriv(a[-1])] # 输出层的误差
for l in range(len(a) - 2, 0, -1):
deltas.append(deltas[-1].dot(self.weights[l].T) * self.activation_deriv(a[l])) # 隐含层误差
deltas.reverse() # 对误差进行顺序颠倒
for i in range(len(self.weights)):
layer = np.atleast_2d(a[i])
delta = np.atleast_2d(deltas[i])
self.weights[i] += learning_rate * layer.T.dot(delta) # 更新权重 w=w+(l)*E*a ,l为学习率,E为误差,o为输入
def predict(self, x):
x = np.array(x)
temp = np.ones(x.shape[0] + 1) # 偏置的加入
temp[0:-1] = x
a = temp
for l in range(0, len(self.weights)):
a = self.activation(np.dot(a, self.weights[l])) # 预测时不需要保存a中间量的值
return a