递进神经网络

Abstract
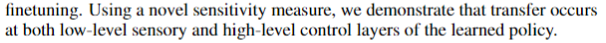
利用一种新的敏感度测量方法,我们证明了转移发生在学习策略的低层感觉层和高层控制层。
1 Introduction
finetune缺点:不适合跨多个任务的转移:如果我们希望利用从一系列经验中获得的知识,我们应该使用哪个模型来初始化后续的模型?这似乎不仅需要一种学习方法来支持迁移学习而不造成灾难性的遗忘,而且还需要对任务相似性的预见。
微调网络只在初始化时吸收了之前的知识,而渐进网络在整个训练过程中保留了一组预先训练好的模型,并从中学习横向连接,从而为新的任务提取有用的特征。通过这种方式结合以前学习过的特征,渐进网络实现了更丰富的组合性,先验知识不再是暂态的,可以集成到特征层次的每一层。此外,除了预先训练过的网络之外,新能力的增加给这些模型提供了灵活性,既可以重用旧计算,也可以学习新计算。正如我们将要展示的那样,进步网络会自然地积累经验,并通过设计对灾难性遗忘具有免疫力,这使它们成为解决长期存在的持续或终生学习问题的理想跳板。特别地,我们证明了渐进式网络提供了与传统finetuning相当(如果不是稍微好一点的话)的转移性能,但没有破坏性的后果。最后,我们开发了一种基于费雪信息和扰动的新分析,它允许我们详细分析任务间的转移是如何发生的以及在哪里发生的。
2 Progressive Networks
持续学习是机器学习的一个长期目标,在机器学习中,智能体不仅学习(和记忆)一系列按顺序经历的任务,而且还具有从先前任务转移知识的能力,以提高收敛速度[20]。渐进式网络将这些需求直接集成到模型体系结构中:通过为每个正在解决的任务实例化一个新的神经网络(acolumn)来防止灾难性遗忘,同时通过横向连接到先前学习的列的特征来实现转换。此方法的可伸缩性将在本节末尾讨论。

这些建模决策是由我们的愿望决定的
(1)在训练结束时解决K个独立任务;
(2)尽可能通过迁移加速学习;
(3)避免灾难性遗忘
在标准的预训练和微调范式中,经常隐含着任务之间重叠的假设。在这个设置中,Finetuning是有效的,因为只需要稍微调整参数到目标域,并且通常只对最顶层进行[23]的再训练。相反,我们没有对任务之间的关系做任何假设,这些假设在实践中可能是正交的甚至是对立的。虽然“微调”阶段可能会忘记这些特征,但这可能被证明是困难的。渐进网络通过为每个新任务分配一个新列来回避这个问题,该列的权值是随机初始化的。与训练前与任务相关的初始化相比,渐进网络中的列可以通过横向连接自由地重用、修改或忽略之前学习到的特征。

应用于强化学习
虽然渐进网络应用广泛,但本文主要研究其在深度强化学习中的应用。在这种情况下,每一列都是为了解决一个特定的马尔可夫决策过程(MDP)

适配器
在实践中,我们用我们称之为适配器的非线性网络连接来增加方程2的渐进网络层。它们既能改善初始条件作用,又能降低维度。

局限性
渐进式网络是实现全面持续学习的垫脚石探员:里面有依次学习多个任务所必需的要素,同时能够进行迁移并对灾难性遗忘免疫。这种方法的缺点是随着任务数量的增加而增加的参数数量。附录2的分析显示,实际上只有一小部分新容量得到了利用,而且随着列数的增加,这种趋势也在增加。这表明生长可以被解决,例如通过增加更少的层或更少的容量,通过修剪[9],或在学习期间通过在线压缩[17]。此外,虽然渐进网络保留了在测试时解决所有任务的能力,但选择用于推理的列需要tasklabel的知识。这些问题留作以后的工作。
3 Transfer Analysis
与微调不同,渐进网不会破坏在之前的任务中学到的特性。这使我们能够详细研究哪些特征以及深度转移实际发生在哪些位置。我们探索了两种相关的方法:一种基于扰动分析的直观但缓慢的方法,另一种是基于费雪信息的更快的分析方法。
Average Perturbation Sensitivity (APS)
为了评估源列对目标任务的贡献程度,我们可以在架构中的孤立点(例如单个列的一层)注入高斯噪声,并测量这种扰动对性能的影响。性能的显著下降表明最终的预测严重依赖于特征映射层。我们发现,这种方法产生的结果与下面介绍的更快的基于fisher的方法相似。因此,我们将扰动分析的细节和结果放在附录中。

Average Fisher Sensitivity (AFS)
利用费雪信息矩阵[2],我们可以得到扰动敏感性的局部逼近。


AFS和APS可以估计网络在多大程度上依赖于层中的每个特性或列来计算其输出。
4 Related Literature
迁移和多任务强化学习存在许多不同的范式,因为它们长期以来被认为是人工智能研究中的关键挑战[15,19,20]。许多迁移学习方法依赖于线性和其他简单模型(如[18]),这是它们适用性的一个限制因素。最近,出现了多任务或深度RL迁移学习的新方法:[22,17,14]。在这项工作中,我们提出了一个深度强化学习的架构,在有序的任务体制中,使学习不会忘记,同时支持个体特征从以前学习的任务转移。
[7]中提出了预训练和微调,并将其应用于[4,11]中的迁移学习,一般是在无监督到有监督或有监督到有监督的环境中。演员模拟法[14]通过对newAtari游戏上的DQN多任务网络进行微调,将这些原则应用到强化学习中,并显示一些反应更快,而其他人则没有。渐进式网络与精细调整方向有很大的不同,因为随着新任务的学习而增加容量。
渐进式网络与神经网络文献中提出的增量式和建设性结构有关。级联相关体系结构的设计目的是在增加和细化特性提取器[6]的同时消除遗忘。像[24]这样的自动编码器使用增量特性增强来跟踪概念漂移,而像[16]这样的深层架构已经被设计出来专门支持特性转移。最近,在[1]中,列分别训练单个噪声类型,然后线性组合,而[5]使用列进行图像分类。[21]的块模块化架构与我们的方法有许多相似之处,但侧重于视觉识别任务。相比之下,渐进式网络方法使用横向连接来接近之前学习的特征,以达到深度组合。它可以用于任何顺序学习设置,但在RL特别有价值。
5 Experiments
Detailed Analysis
乍一看,这个结果似乎并不直观:如果一个渐进式网络从一个源任务中找到了一个有价值的特征集,我们不应该期望一个高度的转移吗?我们提出两个假设。
首先,这可能只是反映了一个优化的困难,源特性提供了快速收敛到一个局部极小值。这是迁移学习中的一个已知挑战[20]:学习源任务会产生一种诱导性偏差,这种偏差在不同的情况下可以帮助或阻碍。其次,这可能反映了一个探索的问题,即转移的表示对于一个函数来说“足够好”,但不是最优策略。
简单讲,finetune是否有效取决于目标域和源域的特征相似性。可能随机初始化都会比在一个和目标域差异较大的base上finetune的要好。