前面已经介绍了tokenizer和filter。tokenizer用来产生token流,而filter负责对token流进行过滤。除了这两个外,其实还有一个charfilter。它的作用是在tokenizer之前对文本进行预处理。而且charfilter可以如同filter一样多个连接使用。
solr定义好的charfilter如下:
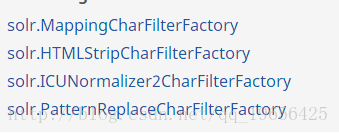
下面来简单介绍一下这几个charfilter:
MappingCharFilterFactory:
使用方式:<charFilter class="solr.MappingCharFilterFactory" mapping="mapping-FoldToASCII.txt"/>
参数:
mapping:指定一个映射文件
规则:按照映射文件的映射规则将一个字符串替换成另一个字符串
映射文件的格式有以下要求:
1.注释以#开头
2.映射格式为"原字符"[空格可有可无]=>[空格可有可无]"目标字符"
3.原字符不可为空,目标字母可为空
除了上述要求外,还有默认的转义字符识别,比如:"\\" => "/"
HTMLStripCharFilterFactory:
使用方式:<charFilter class="solr.HTMLStripCharFilterFactory"/>
规则:移除文本中的html/xml相关内容,
移除的具体规则点这里
ICUNormalizer2CharFilterFactory:
规则:执行预处理的Unicode规范化
大概是根据Unicode规范替换文本。还不大理解,具体的可以点这里
PatternReplaceCharFilterFactory:
使用方式: <charFilter class="solr.PatternReplaceCharFilterFactory"
pattern="··" replacement="··"/>
参数:
pattern:正则表达式
replacement:替换的文本
规则:根据定义的正则表达式和替换文本替换原始文本
例子:
eg1:pattern (\w+)(ing);replacement $1
see-ing looking
=>see-ing look
这里正则表达式匹配到的为"looking",而"$1"表示用正则表达式的第一组匹配的文本替换所有匹配文本,所以"ing"被去掉了其它地方不变。
eg2:pattern (\w+)=(\d+)=(\d+);replacement $3-$1-$2
abc=1234=5678
=>5678-abc-1234
这里将正则表达式的三个组匹配的文本换了先后顺序并将"="换为"-"
以上就是charfilter的简单介绍,点这里查看更多