文本分析概念
停用词
语料中大量出现, 无用数据, 如下类似的这种词语

Tf - 词频统计


TF 的计算方式有很多, 最常见的用 某词文章中出现次数 / 文章总词数
idf - 逆文档频率

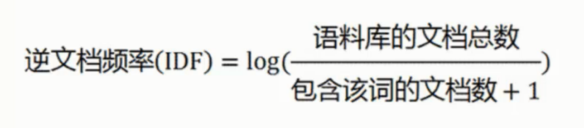
TF - idf 关键词提取

![]()
相似度

分词

语料库
![]()
词频

词频向量
![]()
整体流程
语料清洗 (去掉停用词, 去掉大量重复的非正常用语等)
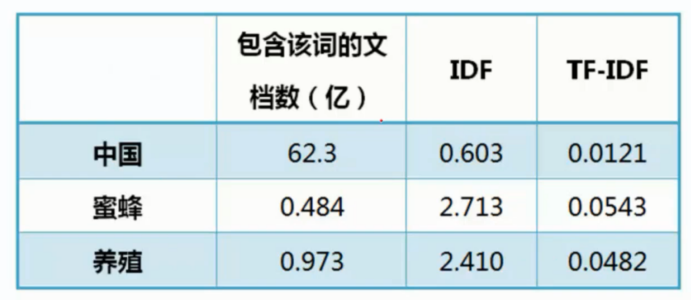
计算公式

文本分析案例 - 新闻分析
样本数据
数据来源于 搜狗实验室新闻数据
数据需要处理成 pandas 便于读取的数据才可以使用
import pandas as pd import jieba df_news = pd.read_table('./data/val.txt',names=['category','theme','URL','content'],encoding='utf-8') df_news = df_news.dropna() # 去除缺失值行 df_news.head()
样本数据结构

样本数据容量
df_news.shape #(5000, 4)
分词 - 使用结巴分词器
读取数据
结巴分词器需要传入的数据为 list , 这里进行一个转换
content = df_news.content.values.tolist() print (type(content)) # <class 'list'>
print(content[1000])
阿里巴巴集团昨日宣布,将在集团管理层面设立首席数据官岗位(Chief Data Officer),阿里巴巴B2B公司CEO陆兆禧将会出任上述职务,向集团CEO马云直接汇报。>菹ぃ和6月初的首席风险官职务任命相同,首席数据官亦为阿里巴巴集团在完成与雅虎股权谈判,推进“one company”目标后,在集团决策层面新增的管理岗位。0⒗锛团昨日表示,“变成一家真正意义上的数据公司”已是战略共识。记者刘夏
分词处理
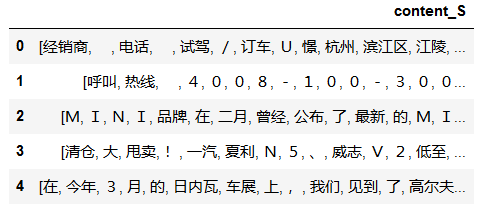
content_S = [] for line in content: current_segment = jieba.lcut(line) if len(current_segment) > 1 and current_segment != '\r\n': #换行符 content_S.append(current_segment)
content_S[1000]


['阿里巴巴', '集团', '昨日', '宣布', ',', '将', '在', '集团', '管理', '层面', '设立', '首席', '数据', '官', '岗位', '(', 'C', 'h', 'i', 'e', 'f', '\u3000', 'D', 'a', 't', 'a', '\u3000', 'O', 'f', 'f', 'i', 'c', 'e', 'r', ')', ',', '阿里巴巴', 'B', '2', 'B', '公司', 'C', 'E', 'O', '陆兆禧', '将', '会', '出任', '上述', '职务', ',', '向', '集团', 'C', 'E', 'O', '马云', '直接', '汇报', '。', '>', '菹', 'ぃ', '和', '6', '月初', '的', '首席', '风险', '官', '职务', '任命', '相同', ',', '首席', '数据', '官亦为', '阿里巴巴', '集团', '在', '完成', '与', '雅虎', '股权', '谈判', ',', '推进', '“', 'o', 'n', 'e', '\u3000', 'c', 'o', 'm', 'p', 'a', 'n', 'y', '”', '目标', '后', ',', '在', '集团', '决策', '层面', '新增', '的', '管理', '岗位', '。', '0', '⒗', '锛', '团', '昨日', '表示', ',', '“', '变成', '一家', '真正', '意义', '上', '的', '数据', '公司', '”', '已', '是', '战略', '共识', '。', '记者', '刘夏']
分词数据
df_content=pd.DataFrame({'content_S':content_S})
df_content.head()
数据清洗
停用词表
通用词表下载后直接读取进来即可
stopwords=pd.read_csv("stopwords.txt",index_col=False,sep="\t",quoting=3,names=['stopword'], encoding='utf-8') stopwords.head(5)

去除停用词
def drop_stopwords(contents,stopwords): contents_clean = [] all_words = [] for line in contents: line_clean = [] for word in line: if word in stopwords: continue line_clean.append(word) # 没过滤掉的加入到列表 all_words.append(str(word)) # 做词云用的列表 contents_clean.append(line_clean) return contents_clean,all_words #print (contents_clean) contents = df_content.content_S.values.tolist() # 分词后正文转列表 stopwords = stopwords.stopword.values.tolist() # 通用词转列表 contents_clean,all_words = drop_stopwords(contents,stopwords)
去除后停用词后的分词数据
df_content=pd.DataFrame({'contents_clean':contents_clean})
df_content.head()

可以对比之前的未去除的数据, 可以看出很多常用词都被去除了
可以看出 一些字母还是没有去除掉, 如果有需要是可以在停用词表中计入即可
词云数据
词云数据是所有出现的非停用词的一个总的统计, 这里一起转换成df结构
df_all_words=pd.DataFrame({'all_words':all_words})
df_all_words.head()

词频展示
词频计算
根据 all_words 分组后添加新一列 count 计数
然后根据 count 排序进行词频的计算
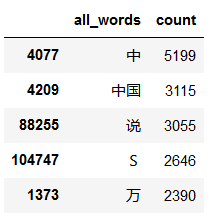
import numpy words_count=df_all_words.groupby(by=['all_words'])['all_words'].agg({"count":numpy.size}) words_count=words_count.reset_index().sort_values(by=["count"],ascending=False) words_count.head()
词云展示
from wordcloud import WordCloud import matplotlib.pyplot as plt %matplotlib inline import matplotlib matplotlib.rcParams['figure.figsize'] = (10.0, 5.0) wordcloud=WordCloud(font_path="./data/simhei.ttf",background_color="white",max_font_size=80) word_frequence = {x[0]:x[1] for x in words_count.head(100).values} # 前 100 个词进行展示 wordcloud=wordcloud.fit_words(word_frequence) plt.imshow(wordcloud)

关键词提取
jieba.analyse.extract_tags 方法可以对关键词进行提取, 指定提取数量
import jieba.analyse index = 1000 print (df_news['content'][index]) content_S_str = "".join(content_S[index]) print() print (" ".join(jieba.analyse.extract_tags(content_S_str, topK=5, withWeight=False)))
阿里巴巴集团昨日宣布,将在集团管理层面设立首席数据官岗位(Chief Data Officer),阿里巴巴B2B公司CEO陆兆禧将会出任上述职务,向集团CEO马云直接汇报。>菹ぃ和6月初的首席风险官职务任命相同,首席数据官亦为阿里巴巴集团在完成与雅虎股权谈判,推进“one company”目标后,在集团决策层面新增的管理岗位。0⒗锛团昨日表示,“变成一家真正意义上的数据公司”已是战略共识。记者刘夏
阿里巴巴 集团 首席 岗位 数据