前言:基于人大的《数据科学概论》第七章。主要内容为文本分析的意义、文本分析的任务与方法、文本分析可视化、文本分析工具。
文章目录
一、文本分析的意义
根据估算,各类组织(包括企业、政府)拥有的数据里,80%是非结构化的数据,其中大部分是文本的形式。
- 非结构化的文本数据,包括电子邮件、博客、微博、客户反馈、医疗记录、合同文本等。
- 这些文本里面,隐藏着潜在的价值。只有通过适当的分析方法,才能从中提取这些有价值的信息。
二、文本分析的任务与方法
1、文本分析的主要任务
包括文本索引与检索、文本分类、文本聚类、文档摘要、主题提取、命名实体识别/概念抽取/关系建模、情感分析等。
文本分析的过程包括几个主要的步骤:
- 采集文本数据集
- 运用文本分析方法分析文本
- 对分析结果进行可视化以及解释和评估分析结果等
2、句子切分、分词、词性标注、语法分析
(1)句子切分和分词
为了对文本进行分析,首先需要把文本切分成一个个句子。接着,需要对句子进行分词。、
(2)词性标注
词性标注(简称POS Tagger)软件,分析某种语言的文本,然后针对每个词赋予POS标记,比如名词、动词
形容词等。
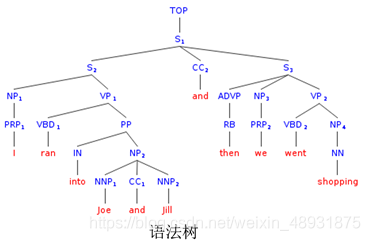
(3)语法树
Parser(语法解析器)首先对句子的文本进行分词,然后进行POS标注,根据POS标注结果以及句子成分信息,找出单词/短语之间的依赖关系,最后构建句子的语法解析树,结果以有向图、或者树的形式展示。
3、文本索引和检索
信息(这里主要指文本)检索,是针对用户提出的信息需求,一般是以关键字表达的查询,从文档集中查找和查询相关度高的文档或者文档片段,返回给用户。
信息检索系统,一般包括四个主要部分,分别是数据预处理、索引生成、检索、结果排序等。
4、文本分类(classification)
文本分类,是把文档集合中的每个文档,划分到一个预先定义的一个主题类别。
- 文本分类是文本分析和挖掘的一项重要工作。把电子邮箱收到的邮件,适当进行分类,分为正常邮件和垃圾邮件,就是文本分类的一个应用实例。
- 文本分类是典型的有监督学习的例子,训练集由已经明确分好类别的文档组成,文档就是输入,对应的类别就是输出。
(1)文本分类系统的主要功能模块
- 预处理器。把文档集合中的文档格式化为某种模式,方便后续处理
- 统计。进行词频统计,词项与分类的相关概率的统计
- 特征抽取。从文档中抽取反映文档主题的特征。
- 分类器的训练。利用文档集部分文档的特征,对分类器进行训练。
- 进行预测。利用分类器确定其他文档额的类别。
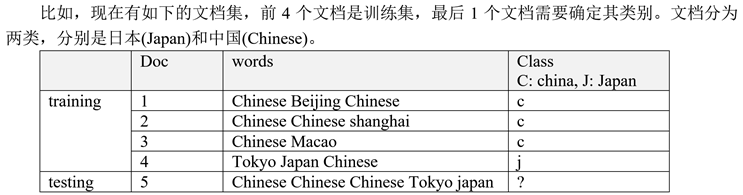
(2)使用朴素贝叶斯算法实现文本分类


(3)文本聚类
文本聚类,是把相似度大的文档放在同一类簇(为了和分类任务Classification中的类别Category分开,在这里Cluster称为类簇)中,相似度小的文档放在另外的类簇中,它是一种无监督的机器学习(没有训练集)方法。
- 文档聚类,应用于需要对文本信息进行有效组织(Organization)、浏览(Browsing)、和摘要(Summarization)的场合。
(4)文档摘要
文档摘要是为文档抽取或者生成一个简洁的版本。
(5)主题抽取
文档的主题,是文档所描述的事物、概念等。比如一篇文档是关于美国大选的,另外一篇文档是关于欧洲冠军杯的,我们可以把这两篇文档归入政治和体育两个大的主题中。
(6)命名实体识别、概念抽取和关系抽取、事实抽取
命名实体识别的目的是发现文档里的各种实体。概念抽取和关系抽取事实抽取
(7)情感分析
情感分析的应用很广泛,包括对问卷调查(Survey)、产品的用户评论(Review)、新闻(News)、博客(Blog)、论坛(Forum)、呼叫中心日志记录(Call Center Logs)等进行情感分析。
情感分析包括情感信息抽取、情感信息分类、以及情感信息的检索及归纳三个层次的任务。
三、文本分析可视化
四、文本分析工具
- NLTK
- OPEN NLP
- Stanford NLP
- Lingpipe
- Gate
- UIMA
- Netlytic