文章目录
中文分词的工具有很多种,例如HanLP、jieba分词、FudanNLP、LTP、THULAC、NLPIR等,这些都是开源的分词工具,大多支持Java、C++、Python,本文对基于python的jieba分词的使用作出具体介绍。
1.特点
- jieba分词支持三种分词模式:
- 精确模式,试图将句子最精确地切开,适合文本分析;
- 全模式,把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义;
- 搜索引擎模式,在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
- 支持繁体分词
- 支持自定义词典
- MIT 授权协议
2.安装说明
代码对 Python 2/3 均兼容
- 全自动安装:
easy_install jieba或者pip install jieba/pip3 install jieba - 半自动安装:先下载 http://pypi.python.org/pypi/jieba/ ,解压后运行
python setup.py install - 手动安装:将 jieba 目录放置于当前目录或者 site-packages 目录
- 通过
import jieba来引用
安装示例
本文使用的是第二种安装方法。
下载:
链接:https://pan.baidu.com/s/1fTJ9lme11jlb9NC1zXEsbQ
提取码:4d1m
安装:
将其解压到任意目录下,然后打开命令行进入该目录,找到setup.py所在的位置,执行:python setup.py install 进行 安装
测试:
安装完成后,进入python交互环境,输入import jieba 如果没有报错,则说明安装成功。

3.算法
- 基于前缀词典实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图 (DAG)
- 采用了动态规划查找最大概率路径, 找出基于词频的最大切分组合
- 对于未登录词,采用了基于汉字成词能力的 HMM 模型,使用了 Viterbi 算法
4.主要功能
(1)分词
-
jieba.cut方法接受三个输入参数: 需要分词的字符串;cut_all 参数用来控制是否采用全模式;HMM 参数用来控制是否使用 HMM 模型 -
jieba.cut_for_search方法接受两个参数:需要分词的字符串;是否使用 HMM 模型。该方法适合用于搜索引擎构建倒排索引的分词,粒度比较细 -
待分词的字符串可以是 unicode 或 UTF-8 字符串、GBK 字符串。注意:不建议直接输入 GBK 字符串,可能无法预料地错误解码成 UTF-8
-
jieba.cut以及jieba.cut_for_search返回的结构都是一个可迭代的 generator,可以使用 for 循环来获得分词后得到的每一个词语(unicode),或者用jieba.lcut以及jieba.lcut_for_search直接返回 list -
jieba.Tokenizer(dictionary=DEFAULT_DICT)新建自定义分词器,可用于同时使用不同词典。jieba.dt为默认分词器,所有全局分词相关函数都是该分词器的映射。代码示例
# encoding=utf-8 import jieba seg_list = jieba.cut("这里是昆明理工大学外语调频台", cut_all=True) print("Full Mode: " + "/ ".join(seg_list)) # 全模式 seg_list = jieba.cut("这里是昆明理工大学外语调频台", cut_all=False) print("Default Mode: " + "/ ".join(seg_list)) # 精确模式 seg_list = jieba.cut("我是张海玲代号小饼干") # 默认是精确模式,这里的“张海玲”并没有在词典中,但是也被Viterbi算法识别出来了 print("new word:"+", ".join(seg_list)) seg_list = jieba.cut_for_search("小明硕士毕业于中国科学院计算所,后在日本京都大学深造") # 搜索引擎模式 print("Search Mode:"+", ".join(seg_list))输出结果图:

(2)添加自定义词典
载入词典
- 开发者可以指定自己自定义的词典,以便包含 jieba 词库里没有的词。虽然 jieba 有新词识别能力,但是自行添加新词可以保证更高的正确率
- 用法: jieba.load_userdict(file_name) # file_name 为文件类对象或自定义词典的路径
- 词典格式和
dict.txt一样,一个词占一行;每一行分三部分:词语、词频(可省略)、词性(可省略),用空格隔开,顺序不可颠倒。file_name若为路径或二进制方式打开的文件,则文件必须为 UTF-8 编码。 - 词频省略时使用自动计算的能保证分出该词的词频。
代码示例
#encoding=utf-8
from __future__ import print_function, unicode_literals #将模块中显式出现的所有字符串转为unicode类型
import sys
sys.path.append("../")#管理系统路径
import jieba #导入jieba包
jieba.load_userdict("userdict.txt") #获取自定义词典
import jieba.posseg as pseg #导入词性标注的包
jieba.add_word('凱特琳') #添加词
jieba.del_word('自定义词') #删除词
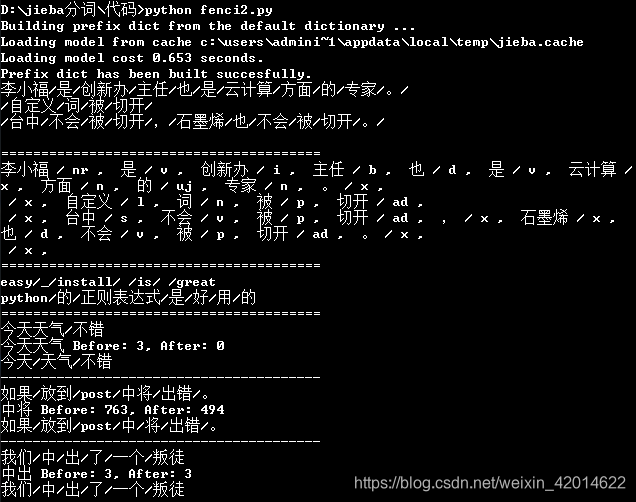
#测试句子
test_sent = (
"李小福是创新办主任也是云计算方面的专家。\n"
"自定义词被切开\n"
"台中不会被切开,石墨烯也不会被切开。\n"
)
#分词
words = jieba.cut(test_sent)
print('/'.join(words)) #用/标识分词结果
print("="*40)
#词性标注
result = pseg.cut(test_sent)
#for循环,把词与词性用/分隔,词性与下一个词用, 分隔
for w in result:
print(w.word, "/", w.flag, ", ", end=' ')
print("\n" + "="*40)
#英文分词
terms = jieba.cut('easy_install is great')
print('/'.join(terms))
#中英文分词
terms = jieba.cut('python的正则表达式是好用的')
print('/'.join(terms))
print("="*40)
# test frequency tune
testlist = [
('今天天气不错', ('今天', '天气')),
('如果放到post中将出错。', ('中', '将')),
('我们中出了一个叛徒', ('中', '出')),
]
for sent, seg in testlist:
print('/'.join(jieba.cut(sent, HMM=False)))
word = ''.join(seg)
print('%s Before: %s, After: %s' % (word, jieba.get_FREQ(word), jieba.suggest_freq(seg, True)))
print('/'.join(jieba.cut(sent, HMM=False)))
print("-"*40)
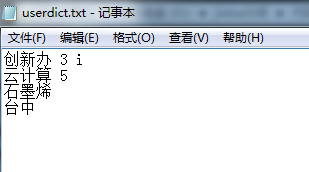
自定义词典内容如下:
输出结果图
调整词典
- 使用
add_word(word, freq=None, tag=None)和del_word(word)可在程序中动态修改词典。 - 使用
suggest_freq(segment, tune=True)可调节单个词语的词频,使其能(或不能)被分出来。 - 注意:自动计算的词频在使用 HMM 新词发现功能时可能无效。
代码示例:

(3)关键词提取
一、基于 TF-IDF 算法的关键词抽取
import jieba.analyse
- jieba.analyse.extract_tags(sentence, topK=20, withWeight=False, allowPOS=())
- sentence为待提取的文本
- topK为返回几个 TF/IDF 权重最大的关键词,默认值为 20
- withWeight为是否一并返回关键词权重值,默认值为False
- allowPOS仅包括指定词性的词,默认值为空,即不筛选
- jieba.analyse.TFIDF(idf_path=None)新建TFIDF实例,idf_path为IDF频率文件
二、基于 TextRank 算法的关键词抽取
- jieba.analyse.textrank(sentence, topK=20, withWeight=False, allowPOS=(‘ns’, ‘n’, ‘vn’, ‘v’)) 直接使用,接口相同,注意默认过滤词性。
- jieba.analyse.TextRank() 新建自定义 TextRank 实例
代码示例:
#encoding=utf-8
from __future__ import unicode_literals #将模块中显式出现的所有字符串转为unicode类型
import jieba
import jieba.analyse
print('-'*40)
print('基于 TF-IDF 算法的关键词抽取')
print('-'*40)
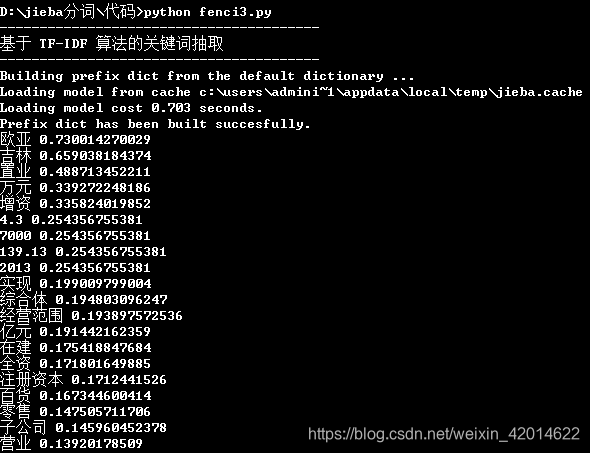
s = "此外,公司拟对全资子公司吉林欧亚置业有限公司增资4.3亿元,增资后,吉林欧亚置业注册资本由7000万元增加到5亿元。吉林欧亚置业主要经营范围为房地产开发及百货零售等业务。目前在建吉林欧亚城市商业综合体项目。2013年,实现营业收入0万元,实现净利润-139.13万元。"
for x, w in jieba.analyse.extract_tags(s, withWeight=True):
print('%s %s' % (x, w))
print('-'*40)
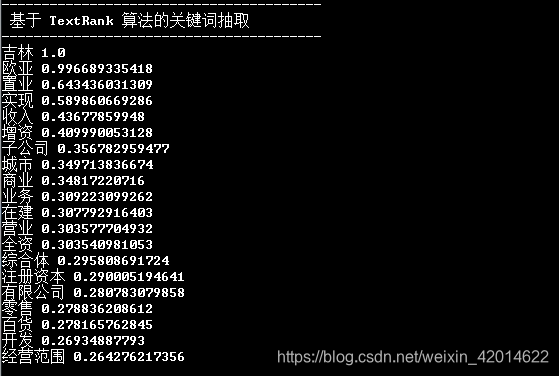
print(' 基于 TextRank 算法的关键词抽取')
print('-'*40)
for x, w in jieba.analyse.textrank(s, withWeight=True):
print('%s %s' % (x, w))
输出结果图
小应用:查看《西游记》这本书的人物关系。
代码如下:
import jieba
import jieba.analyse
path = './xiyouji.txt'
file_in = open(path)
s = file_in.read()
for x, w in jieba.analyse.extract_tags(s, topK=10, withWeight=True): #基于 TF-IDF 算法,抽取10个关键词
print('%s %s' % (x, w))
输出结果图

由上结果图可以看出:“行者”出现的频率是最高的(可以称呼他为男一号),之后是“八戒”、“师父”、“三藏”,这在一定程度上可以说明,本书是以这四位主人公来展开故事情节的。
(4)词性标注
jieba.posseg.POSTokenizer(tokenizer=None)新建自定义分词器,tokenizer参数可指定内部使用的jieba.Tokenizer分词器。jieba.posseg.dt为默认词性标注分词器。- 标注句子分词后每个词的词性,采用和 ictclas 兼容的标记法。
代码示例:
#encoding=utf-8
import jieba
import jieba.posseg
words = jieba.posseg.cut("歌手许嵩是我的偶像。")
for word, flag in words:
print('%s %s' % (word, flag))
输出结果图

(5)Tokenize:返回词语在原文的起止位置
-
注意,输入参数只接受 unicode
-
默认模式
代码示例:
#encoding=utf-8
from __future__ import unicode_literals #将模块中显式出现的所有字符串转为unicode类型
import jieba
result = jieba.tokenize('永和服装饰品有限公司') #默认模式进行分词,Tokenize: 返回词语在原文的起止位置
for tk in result:
print("word %s\t\t start: %d \t\t end:%d" % (tk[0],tk[1],tk[2]))
输出结果图

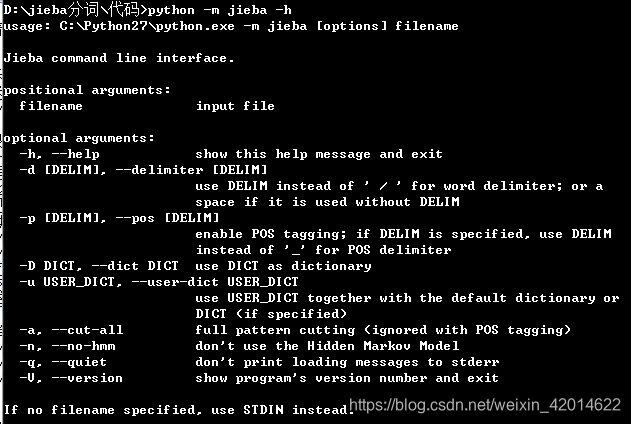
(6)命令行分词
使用示例:python -m jieba 荷塘月色.txt > cut_result荷塘月色.txt

输出结果
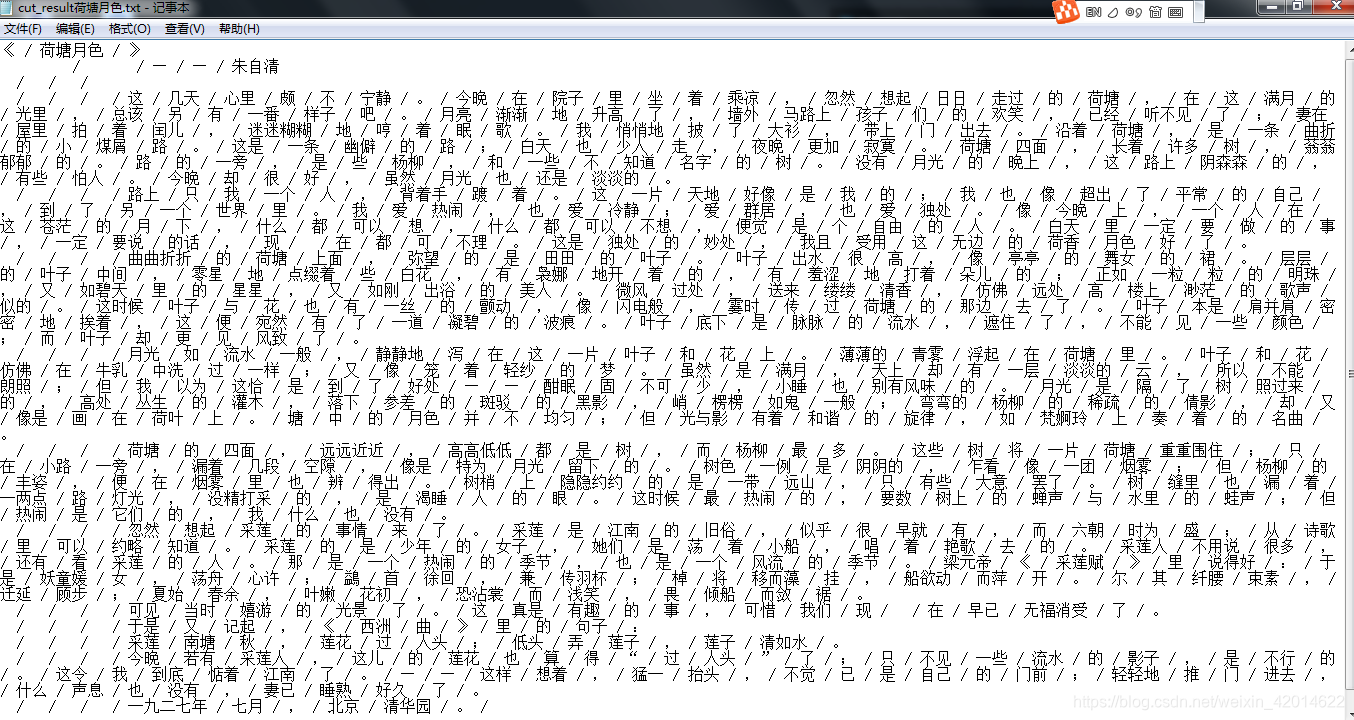
命令行选项:
使用: python -m jieba [options] filename
结巴命令行界面。
固定参数:
filename 输入文件
可选参数:
-h, --help 显示此帮助信息并退出
-d [DELIM], --delimiter [DELIM]
使用 DELIM 分隔词语,而不是用默认的' / '。
若不指定 DELIM,则使用一个空格分隔。
-p [DELIM], --pos [DELIM]
启用词性标注;如果指定 DELIM,词语和词性之间
用它分隔,否则用 _ 分隔
-D DICT, --dict DICT 使用 DICT 代替默认词典
-u USER_DICT, --user-dict USER_DICT
使用 USER_DICT 作为附加词典,与默认词典或自定义词典配合使用
-a, --cut-all 全模式分词(不支持词性标注)
-n, --no-hmm 不使用隐含马尔可夫模型
-q, --quiet 不输出载入信息到 STDERR
-V, --version 显示版本信息并退出
如果没有指定文件名,则使用标准输入。