一、统计学习方法概论
统计学习方法是基于数据构建统计从而进行预测和分析。
方法: 监督学习、非监督学习、半监督学习和强化学习。
统计学习方法的三要素:假设空间、模型选择的准则和模型学习的算法。 (模型、策略、算法)
1.1、基本概念
- 1、输入空间、特征空间和输出空间
-
将输入和输出的所有可能的取值的集合分别成为输入空间(input space)和输出空间(output space)。
输入的实例,通常由特征向量表示,所有特征向量存在的空间成为特征空间,特征空间的每一维对应一个特征。 - 2、联合概率分布
- 监督学习:假设输入与输出的随机变量 遵循联合概率分布 。则 为分布函数 (密度函数)。
- 3、假设空间
- 监督学习目的在于:学习一个由输入与输出的映射形成的这一模型。输入空间与输出空间的映射集合,就是假设空间
1.2、问题的形式化
监督学习利用训练数据集学习一个模型,再用模型对测试样本集进行预测(prediction),
监督学习分为学习和预测两个过程,由学习系统和预测系统完成。
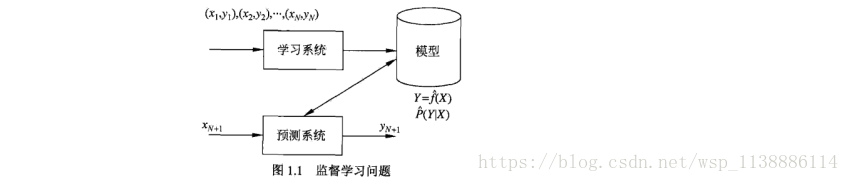
1.3、统计学习三要素

1.3.1、常用的几种损失函数(loss function)

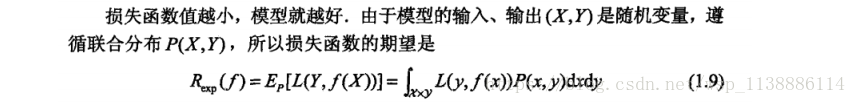
1.3.2、经验风险最小化与结构风险最小化

1.4、模型评估和选择
1.4.1、训练误差与测试误差

1.4.2、过拟合和模型的选择
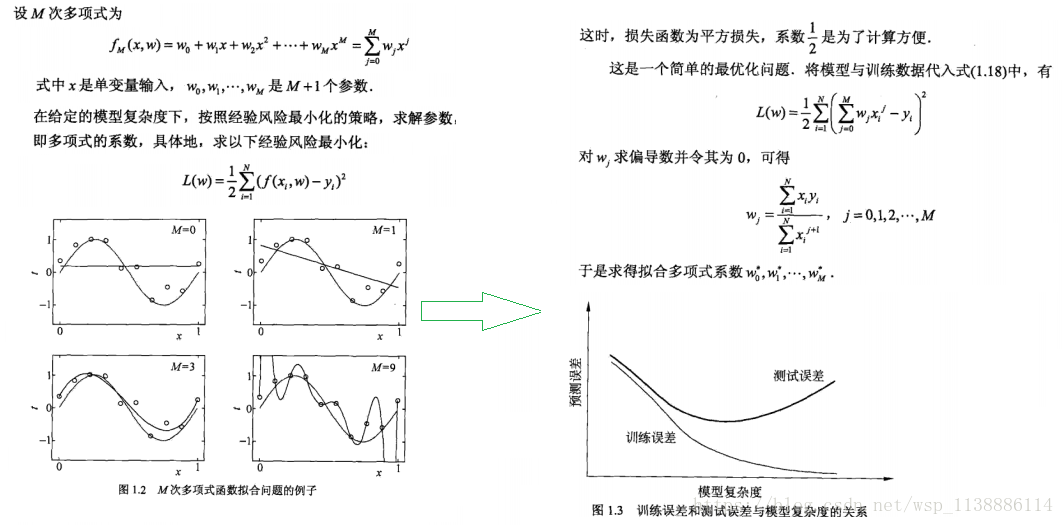
1.5、正则化和交叉验证


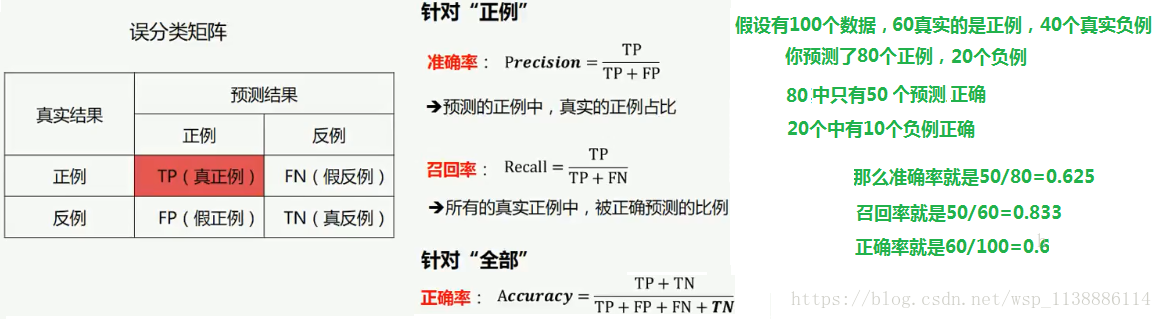
1.6、分类问题
二、感知机
2.1、感知机模型
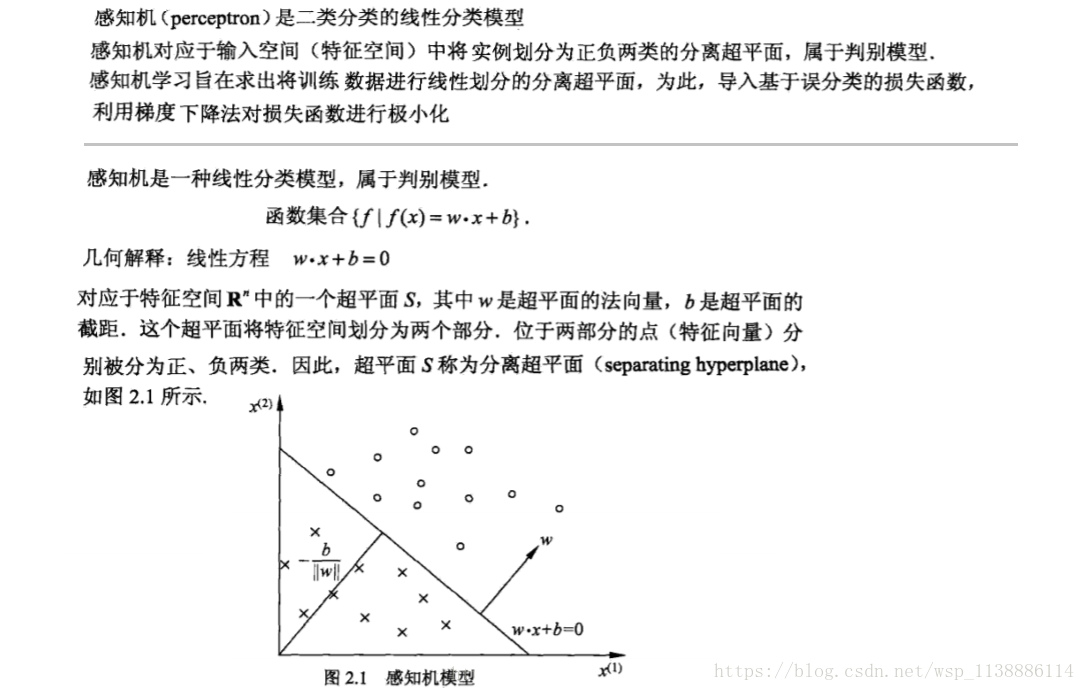
2.2、算法的收敛性

三、K近邻法
3.1、K近邻属性
K近邻是不具有显式的学习过程,当K=1的时候,成为最近邻算法。
K最近邻(k-Nearest Neighbour,KNN)分类算法,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一。
该方法的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。
用官方的话来说,所谓K近邻算法,即是给定一个训练数据集,对新的输入实例,
在训练数据集中找到与该实例最邻近的K个实例(也就是上面所说的K个邻居),
这K个实例的多数属于某个类,就把该输入实例分类到这个类中。

3.2、距离度量
- 特征空间中两个实例点的距离:
- 是两个实例点相似程度的反映,k近邻模型的特征空间一般是 n 维特征向量的 ,使用的距离是欧式距离,也可以使用其他的距离,如下:

3.3、k值的选择

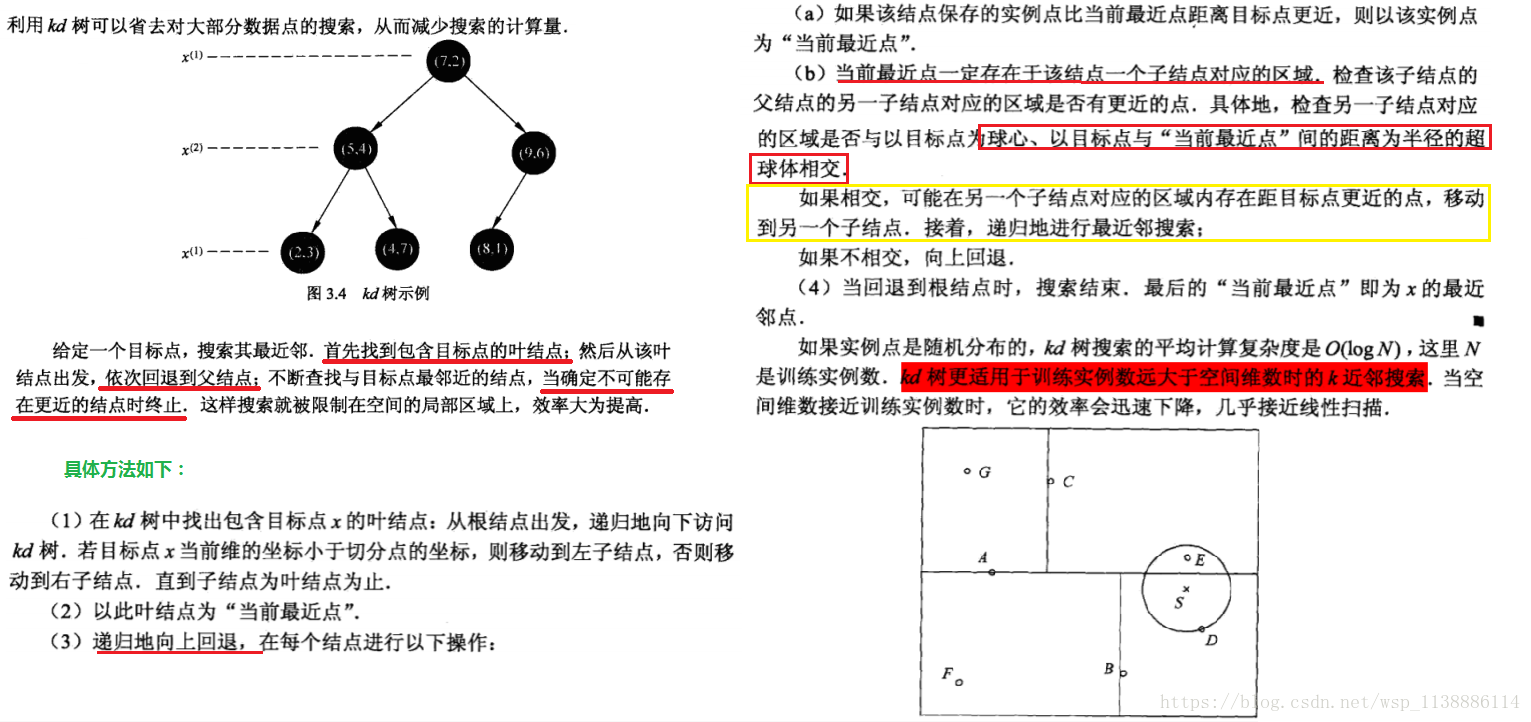
3.4、K近邻搜索:kd树
K近邻法最简单的实现方法是线性扫描

3.5、搜索方法
四、朴素贝叶斯
4.1、原理
朴素贝叶斯分类是一种十分简单的分类算法,叫它朴素贝叶斯分类是因为这种方法的思想真的很朴素。
朴素贝叶斯的思想基础是这样的:
对于给出的待分类项,求解在此项出现的条件下各个类别出现的概率,哪个最大,就认为此待分类项属于哪个类别。
通俗来说,就好比这么个道理,你在街上看到一个黑人,我问你你猜这哥们哪里来的,你十有八九猜非洲。
为什么呢?因为黑人中非洲人的比率最高,当然人家也可能是美洲人或亚洲人,但在没有其它可用信息下,
我们会选择条件概率最大的类别,这就是朴素贝叶斯的思想基础
