一个唯一的因变量和多个自变量 之间的关系
这里自变量在处理之前不仅仅是数值型
上图:
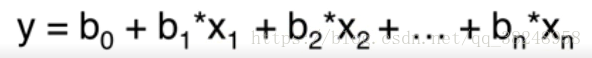
我们要做的也就是,寻找到最佳的b0、b1、…….bn
这里有关于50个公司的数据:
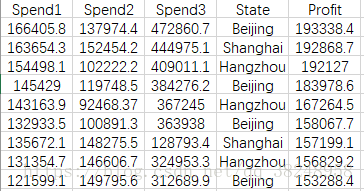
spend1、2、3代表了公司在某三个方面的花销,state是公司的的地址,profit则是公司去年的收入。现在要选择目标公司,要求绩效最好,也就是利用前四列的数据预测profit。
但是我们发现,y=b0+b1*x1+b2*x2+b3*x3+b4*h 当中的h一定是个数值的,就是state不同引起h的不同,将state分成三列,每一列对应一个地址,将这三列的数据转化成虚拟变量
就是说beijing是0时,上海便是1,hangzhou我们是完全可以忽略的,因为两列数据确定数值以后,对应的第三列的数据便知道了
最终呢,我们只是将这个一列包含三种地址的数据,转换成了两列,每一列只有0或1的数据
到上一部的数据处理 加上测试集与测试集的操作
dataset = pd.read_csv('COM.csv')
X = dataset.iloc[:, :-1].values
y = dataset.iloc[:, 4].values
labelencoder_X = LabelEncoder()
X[:, 3] = labelencoder_X.fit_transform(X[:, 3])
onehotencoder = OneHotEncoder(categorical_features = [3])
X = onehotencoder.fit_transform(X).toarray()
float_formatter= lambda X:"%.2f" % X
np.set_printoptions(formatter={'float_kind':float_formatter})
X = X[:, 1:] #删除第0列
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 0)拟合回归器
regressor = LinearRegression() #回归器的对象
regressor.fit(X_train, y_train) #拟合
# Predicting the Test set results
y_pred = regressor.predict(X_test) #包含了的预测结果的向量这一部分与简单线性回归的道理是一样的,可参考:简单线性回归
反向淘汰,选择重要的指标和可以剔除的指标
先加上b0的对应的自变量,也就是该列全部都是1
X_train = np.append(arr = np.ones((40, 1)).astype(int), values = X_train, axis = 1)反向传播一般分五个步骤
- 选取显著性指标 一般为0.05、每一列的p值大于指标的时候,可以认为是能够删除的,反之则认为对目标值的影响是不可以忽略的
- 输入所有的训练进行拟合
- 选出p值最大的那一列
- 如果第三步的p值大于显著性指标,则删除这一列
- 对剩余的训训练值重复第三步,直到p值小于显著性指标
Ximo = X_train
regressor_OLS = sm.OLS(endog = y_train, exog = Ximo).fit()
#endog 因变量 exog 自变量
print(regressor_OLS.summary())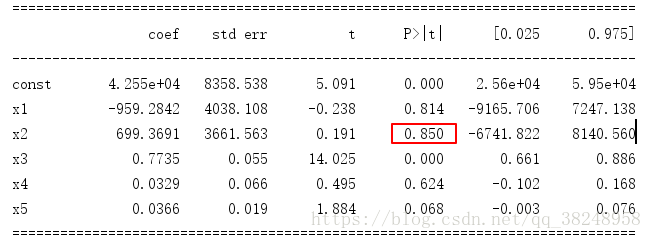
第一次的summary结果显示,X2的p值最大,而且大于显著性指标
按照这个步骤一次进行判断……….