与简单线性回归相比,多元线性回归不过是多了几个自变量x。
上篇所列的几个方程更改如下:
多元线性回归模型:
y = β0 + β1*x1 + β2*x2 + … + βn*xn + E
多元回归方程:
E(y) = β0 + β1*x1 + β2*x2 + … + βn*xn
估计多元回归方程:
y_hat = b0 + b1*x1 + b2*x2 + … + bn*xn
利用一个样本集计算出多元回归方程中β0,β1等值的估计值b0,b1等,得到估计方程。
利用样本计算出方程b0,b1等参数的方法原则依然还是
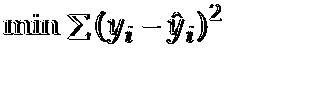
每一组x对应的y值与方程中相应x的y值之差的平方的和最小。
运算与简单线性回归类似,用到线性代数和矩阵代数。这个省略手动的推导计算过程,下面用一个例子以调用python中包的方式来实现对参数b0,b1等的求解。
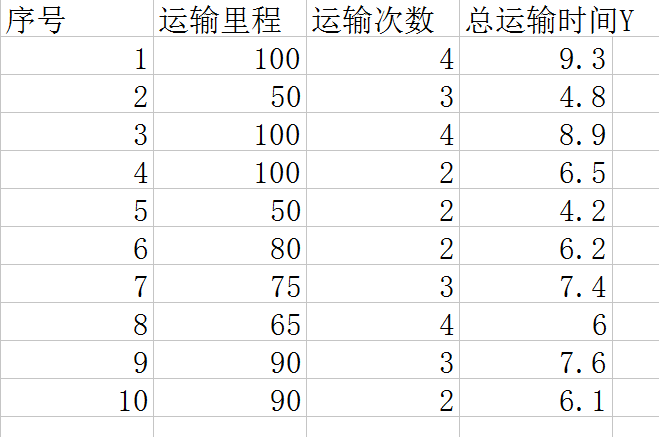
如上图,有10组数据,分别是一个运送公司关于运输里程x1,运输次数x2,以及总运输时间Y的关系。这是一个自变量数为2的一个多元线性回归,我们要根据这些样本求出估计方程: y估计 = b0 + b1*x1 + b2*x2, 也就是要求出其中的参数b0, b1, b2。为什么说是估计方程呢?因为样本只是一部分而不是全体,所以称其为估计方程。下面利用Python来求解这个问题:
from numpy import genfromtxt
import numpy as np
from sklearn import datasets, linear_model
dataPath = r"C:\Users\zelta\Desktop\Delivery.csv"
#加上r就会将后面当做一个完整的字符串,而不会认为里面有什么转义之类的。
deliveryData = genfromtxt(dataPath, delimiter = ',')
print "data"
print deliveryData
x = deliveryData[:, :-1]
y = deliveryData[:, -1]
print "x: "
print x
print "y: "
print y
regr = linear_model.LinearRegression()
regr.fit(x, y)
#打印出regr的参数
print "cofficients"
print regr.coef_
print "intercept: "
print regr.intercept_
#预测一个例子
xPred = [103, 7]
yPred = regr.predict(xPred)
print "predicted y:"
print yPred
#11.89213978
直接利用sklearn包里面线性回归的函数构造模型,把数据传入其fit函数中。有一点要注意,提取x,y数据列表的Delivery.csv就是上图表格数据去除第一行和第一列后的csv文件。
程序运行结果: 自变量参数分别为 0.0611346 0.92342537, b0为-0.868701466782,取3位小数得到最后的估计方程为:
y_hat = 0.061*x1 + 0.923*x2 - 0.869
利用这个方程就可以根据一组x预测y的值。
我们也可以根据这个方程得到其它的一些信息,比如平均运送距离每增加1公里,运输时间增加0.0611小时,平均每多运输1次,运输时间增加0.923小时。
还有一个问题,当自变量x中有分类型的变量该如何解决呢?比如x中有一个变量是车型: 3种车, 自行车,电瓶车,汽车。这也会影响最后的运输时间,给这3种车编个号0,1,2。表格变成如下图。
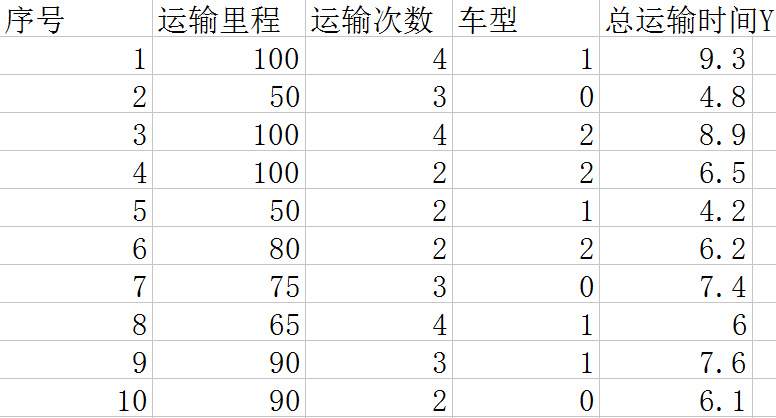
这个时候我们不能利用车型的值作为x进行运算,因为车型的值只是表示类别,没有大小关系。这里要用到前面几篇中利用到的方法,将其转化为数字型的数据进行运算。也就是如下图:
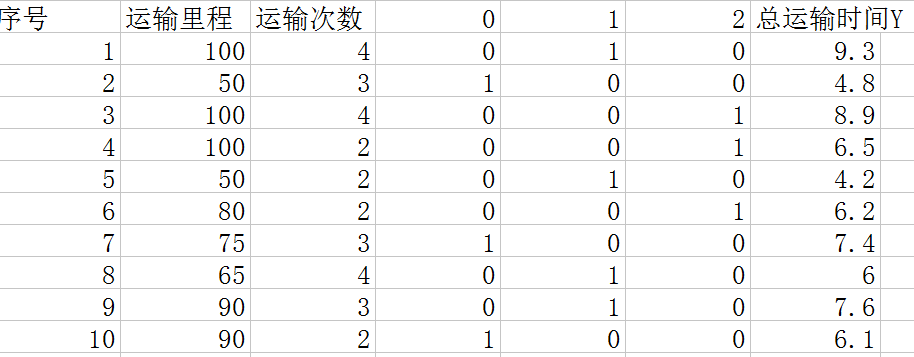
用3个x变量来表示车型。这样就可以把类型的变量转化为数据型的变量代入方程进行运算。