机器学习训练营——机器学习爱好者的自由交流空间(qq 群号:696721295)
密度估计普遍用于无监督学习、特征工程和数据建模。最流行和使用的密度估计技术是混合模型,例如高斯混合模型,基于邻居的方法,例如核密度估计。密度估计的概念很简单,大多数人已经熟悉了一种常见的密度估计技术:直方图。
密度估计:直方图
一个直方图是一个简单的数据可视化方法,它定义了间隔(bins), 落入每个间隔的数据点的个数。一个直方图的例子,请看下图的左上图:
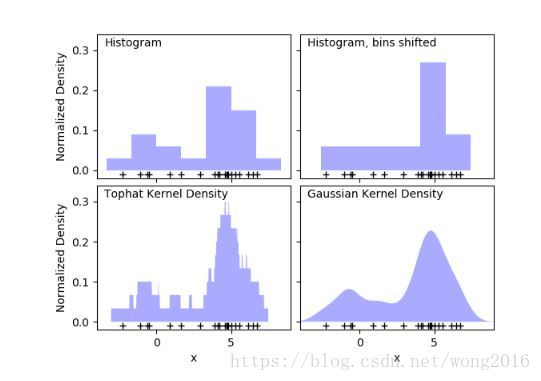
直方图的主要问题是,bins的选择对可视化结果有不相称的作用。再来看右上图,它显示的是相同数据的直方图,只是bins右移了。这两个直方图看起来很不同,可能导致对数据的不同解释。
直观上,你可能把直方图看作块堆,每个点一块。通过堆这些块在适合的网格间距里,得到了直方图。但是,如果我们中心化每一块,加和每一个位置的高度,结果如何呢?这个思想导致了左下图,它可能不如一个直方图整洁,但让我们看清了数据驱动块位置的事实,所以它是一种更好的数据可视化方法。
上图是一个核密度估计的例子。通过使用一个平滑核,我们发现了一个平滑分布。右下图显示的是一个高斯核密度估计。
核密度估计
在scikit-learn里,由sklearn.neighbors.KernelDensity执行核密度估计。尽管上图使用的是一维数据,但核密度估计能做任意维数的。在下图里,我们从二项分布抽取100个点,核密度估计来自三种核选择。
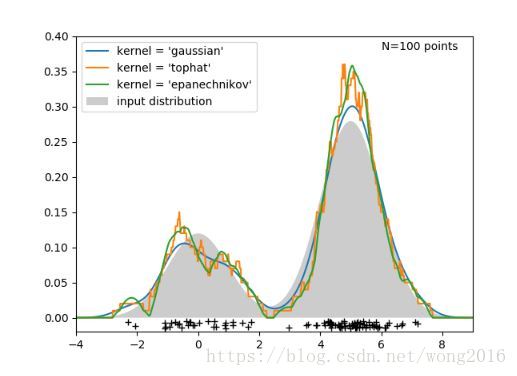
从图上可以清楚地看到核形状怎样影响结果分布的平滑性。scikit-learn核密度估计量能被如下使用:
from sklearn.neighbors.kde import KernelDensity
import numpy as np
X = np.array([[-1, -1], [-2, -1], [-3, -2], [1, 1], [2, 1], [3, 2]])
kde = KernelDensity(kernel='gaussian', bandwidth=0.2).fit(X)
kde.score_samples(X)这里,我们使用了参数kernel=’gaussian’. 数学上,核是一个受带宽
控制的正函数
. 给定核形式,在一群点
里的一个点
的密度估计
这里,带宽 作为一个平滑参数,控制结果的方差与偏差之间的平衡。一个大的带宽导致一个非常平滑,即高偏差的密度分布。一个小的带宽导致一个不平滑,即高方差的密度函数。
sklearn.neighbors.KernelDensity执行几种普遍使用的核形式,显示如下图:

核形式如下:
- Gaussian kernel (kernel = ‘gaussian’)
- Tophat kernel (kernel = ‘tophat’)
- Epanechnikov kernel (kernel = ‘epanechnikov’)
- Exponential kernel (kernel = ‘exponential’)
- Linear kernel (kernel = ‘linear’)
- Cosine kernel (kernel = ‘cosine’)
核密度估计可以用来作为任何有效的距离测度。一个特别有用的测度是Haversine距离,它测量位于球面上的点的角距离。下面是一个使用核密度估计可视化地理数据的例子,描述在南美洲的两个不同物种的观测分布。

核密度估计的另一个有用的应用是学习一个非参数集成模型,从该模型抽取新样本。下面是使用该应用产生一个新的手写数字集的例子,使用的高斯核学习自数据的PCA投影。

新数据是原始数据的线性组合,权抽取自KDE模型。
阅读更多精彩内容,请关注微信公众号:统计学习与大数据