机器学习训练营——机器学习爱好者的自由交流空间(qq 群号:696721295)
很多应用需要能够决定一个新的观测是否同分布于存在的观测。若同分布,则称新观测inlier; 若不同,则称outlier. 需要注意两点不同:
novelty detection: 训练数据未受outliers污染,我们感兴趣的是检测新观测里的异常(anomalies).
outlier detection: 训练数据包括outliers, 我们需要拟合训练数据的中心模式,忽略异常观测。
scikit-learn提供了一套用于novelty or outliers detection的机器学习工具。执行策略是从数据无监督地学习:
estimator.fit(X_train)使用一个预测方法,新的观测能被排序为inliers or outliers:
estimator.predict(X_test)Inliers标签为1, outliers标签为-1.
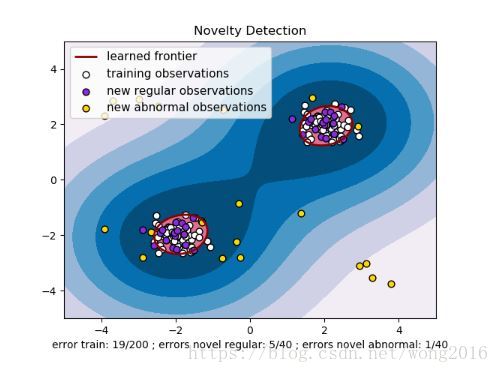
Novelty Detection
考虑 个观测组成的数据集,来自 个特征的相同分布。现在,我们增加一个新观测到这个数据集里。这个新观测与其它观测同分布吗?我们利用novelty detection工具和方法解决这个问题。
通常需要学习一个初始观测分布的等高线的边界,画在
维空间里。然后,如果进一步的观测层位于边界界定的子空间里,则将新观测视为与存在的观测同分布;否则,如果它们位于边界外,则认为是带有置信评价的异常。
Outlier Detection
Outlier detection类似与novelty detection, 它的目标是将正常的观测与outliers分隔开。
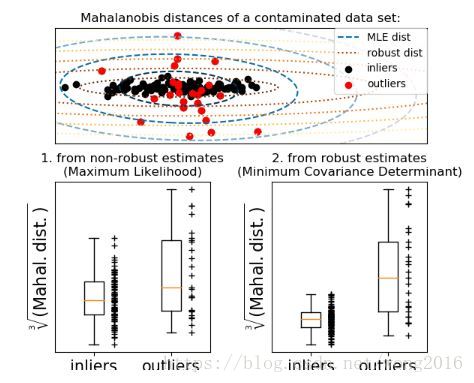
拟合一个椭圆层
一种普遍的方法是假设正常数据来自一个已知分布,比如正态分布。从这个假设出发,我们通常定义数据的“形状”,将远离该形状区域的观测定义为离群观测。scikit-learn提供一个covariance.EllipticEnvelope对象,拟合一个健壮的协方差估计。这样,拟合了一个中心数据点的椭圆,忽略中心模式之外的点。
例如,假设inlier数据是正态分布,它将以一种健壮的方式估计inlier位置和协方差,不受outliers的影响。来自估计的Mahalanobis距离被用来得出一个离群测度。该策略演示如下:
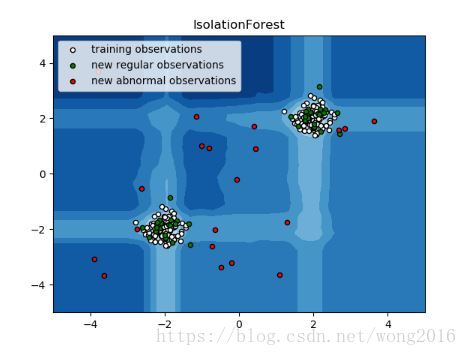
孤立森林
在高维数据集上做Outlier Detection的一个有效的方法是使用随机森林。Ensemble.IsolationForest随机选择一个特征,然后在被选特征的最大值和最小值之间随机选择一个分割值,作为孤立观测的阈值。
由于递归分割能够由一棵树结构表示,孤立一个样本所需要的分割数等于从根节点到叶子节点的路径长度。路径长度平均在这些树的森林上,是一个正常测度,作为决策函数。该策略演示如下:
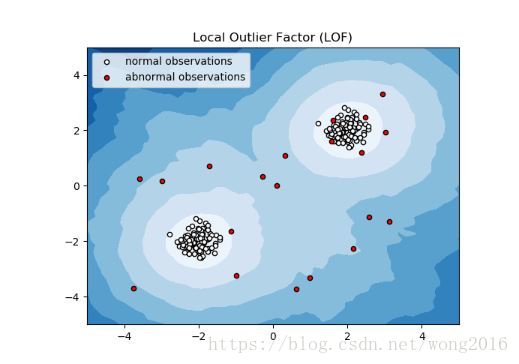
局部异常因子
另一种用在中等规模数据集上的方法是使用局部异常因子(Local Outlier Factor, LOF)算法。neighbors.LocalOutlierFactor算法计算反映异常程度的分数,称异常因子。异常因子度量一个给定的数据点与它的邻居的局部密度偏差。这个思想的实质是,检测密度低于它的邻居的样本。
实际上,局部密度从k近邻获得。一个观测的LOF分数等于它的k近邻的平均局部密度与自己的局部密度的比率。一个正常的观测的局部密度与它的邻居类似,而异常观测的局部密度相比邻居要小的多。
邻居数k的选择:
大于一个类必须包括的最小对象数。
小于有可能是局部outliers的最大对象数。
实际操作里,这些信息通常是不可利用的。根据经验,通常取n_neighbors=20.
LOF算法的优点是,它同时考虑了数据集的局部和全局属性。即使数据集的异常样本有不同的密度,它的表现也不错。问题并不是样本被如何孤立的,而是它关于周围的邻居是如何孤立的。该策略演示如下:
阅读更多精彩内容,请关注微信公众号:统计学习与大数据