深度学习之目标检测之RCNN ------2014.10
1.1 R-CNN物体识别
三个核心模块:1.类别独立region proposal;2.从各个region中提取固定长度特征向量的CNN;3.特定分类linear SVM

1.1.1 region proposal
方法包括objectness, selective search, category-independent object proposal, constrained parametricmin-cuts (CPMC), multi-scale combinational grouping, Ciresan
文中使用selective search(结合了exhaustive search和segmentation,随机生成一系列大小比例不同的box,根据box之间的相似性合并然后用SVM分类合并同类box)。由于selective search耗时很长,已经不常使用故在此不再介绍。
1.1.2 特征提取
将获取的region边界超各方向外延16pixel,然后resize成227 pixel x 227 pixel,并且每个pixel减去这个region的pixel均值(centering data,方便share weights),用ImageNet 5层卷积层+2层全连接层(如下)提取4096维特征向量。
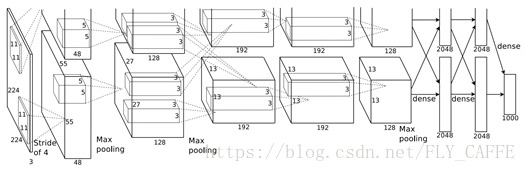
注:object proposaltransformation的方法有两种:第一种是tight-squarewith context,即用最小的方框在原图框出object后按固定比例scale(有一种变体是tight-squarewithout context,就是直接用objectproposal按固定比例进行scale);第二种就是对objectproposal进行全向scale。在上述方法中如果选择框超过了原图的大小,缺失的数据用图片的pixel均值代替(可能复制的效果会更好)。此外,通过测试发现在objectproposal外加一层padding(n=16)在进行transformation能够提高mAP 3-5个点。

1.2 测试实时检测 (test time detection)
测试时用SS提取约2k region proposal,然后计算特征向量然后用一系列类别特异SVM计算该类别的分值,用greedynon-maximum suppression 将那些与最高分值region的IoU超过阈值的region去掉。
从运行时间分析来看,由于所有CNN参数在所有类别中都是共享的,并且获取的特征向量与之前方法(比如spatialpyramids with bag-of-visual-word-encoding,360k)相比相当低维,所以计算regionproposal和特征向量的时间仅需13s/image(GPU)或53s/image(CPU)。而之后的SVM计算各类的分值则是类特异的(计算特征向量与SVM weights的点积和之后的non-maximumsuppression,而在实际操作中,点积一般是batch为矩阵x矩阵的乘积,比如2000个region为一个batch构成2000 x 4096的特征矩阵)。但是即使是100k类别的linear predictor,所需的矩阵乘法消耗的计算资源也仅需1.5G,不需要诸如hashing之类的approximation technique。
1.3 Training
Supervisedpre-training: 用ILSVRC2012分类数据集进行image-levelannotation的pre-training(无bounding box)
Domain-specificfine-tuning: 将ImageNet网络最后一层的1000-class分类层用N+1替换(N为检测的类别书,1为背景),然后用处理后的regionproposal 用SGD继续训练网络参数。region proposal与某个类别的ground-truthbox的IoU > 0.5则被当作该class的正例,其余的region proposal则是该class的负例。SGD开始的lr为0.001(在pre-training的时候是0.01),每次iteration中,以128个region proposal(所有class)作为一个batch,其中32个为正例,96个为负例。
Objectcategory classifier: 在验证集上regionproposal与ground-truthbounding box的IoU在0.3以上(从0-0.5实验后得)则作为该类别的正例,反之为负例。当拿到了特征向量以及label(region class)之后,对每个class训练一个linear SVM。实际操作中用standardhard-negative mining method来加快收敛。
注:fine-tuning和SVM训练时所用的IoU标准不同的原因是前者用的是region proposal中与ground-truth bounding box IoU大于0.5的作为正例,其余regionproposal作为负例;而后者用的正例直接是ground-truthbounding box,与class所有实例的IoU小于0.3的region proposal作为负例(而与其他class的IoU超过0.3的region proposal则被忽略)。一句话来说就是根据训练结果反馈后确定的。
至于为什么不直接用CNN网络最后一层(softmaxregression classifier)直接作为objectdetector,而是从头训练了SVM,因为这样做会降mAP,原因可能是网络的fine-tuning对获取精确的region proposal没有帮助,以及正如前面描述的那样两者用的负例的严谨性的差异。
1.2 visualizelearned feature
第一层filter提取的特征为orient edge和opponent colors。后面几层的可视化通过ZF方法进行(思路是大致如下:网络中某一unit(特征)直接作为分类检测器,然后用大量region proposal(~10M)作为输入计算这个unit的activation,根据activation从高到低对proposal排序,进过non-maximumsuppression,前几位就是这个unit(feature)所展示的形态)。

(pool5:6 x 6 x 256; initial: 227 x 227 x 1; receptive fields (195 x 195),stride (32 x 32))
1.3bounding box regression
为了减少定位误差,文中用pool5层的提取的feature训练了一个class-specific线性回归模型来生成新的region proposal。训练集是{Pi, Gi}对,其中Pi=(Px,Py, Pw, Ph),Gi=(Gx,Gy, Gw, Gh),P为proposal box,G为ground-truth box,x为box center横坐标,y为box center纵坐标,w为box width,h为box height。

dxP就是P的pool5提取的特征(Φ5P)构建的线性方程,故dxP = WxTΦ5P。W可以通过regularized least squares objective学习得到。


在实际计算中,regularization很重要,在验证集上λ设为了1000。此外训练集的选择也很重要。Regionproposal与ground-truthbox之间的IoU大于0.6的才选作训练样本。
1.4 ILSVRC2013数据集测试
1.4.1 数据集概况
training sample: 395918 (not exhaustively annotated),validation sample: 20121, test sample: 40152, class: 200。由于训练集不是完全标注的,所以不能用来hard negativemining。本实验使用一半验证集val1(剩下的一半val2还是作为验证集)+部分训练集数据作为正例样本,但是由于很多class在验证集中样本数很少(一半少于110),所以分割的时候需要先进行class-balancespartition(通过用class数作为特征对验证集图片进行聚类然后用randomized localsearch进行分割,最大的relativeimbalance (|a - b|/(a + b)) 为11%,中值为4%)。
1.4.2 regionproposal
首先将数据集中的图片resize到500x500(大小差异很大),然后SS处理val1,val2,test集中的图片(不处理train集)获得2403个region proposal(91.6%的召回率,IoU >0.5,远低于PASCAL数据集上的98%)(SS生成region proposal数量与图片分辨率有关)。
1.4.3training data
val1中获得的regionproposal和ground-truthbounding box + train集N个ground-truth bounding box(val1+trainN)。用val1+trainN数据集对ImageNet CNN进行fine-tuning。在训练SVM detector时,用val1+trainN的ground-truth bounding box作为正例,然后在val1集进行hard negative mining随机选出5000张图作为负例(本来是剩下的全部作为负例,结果发现mAP只提升了0.5%,但是耗时多了一倍)。用val1集作为bounding-box regressor的训练集。
1.4.4validation and evaluation
用val2数据进行validation。包括SVM C hyperparameters, region包装时所用的padding,NMS阈值,bounding box regression hyperparameter在内的超参数都与PASCAL的保持一致。