1. RNN之所以叫做循环神经网络是因为一个序列当前的输出与前面的输出也有关。
2. LSTM可以在更长的时间范围来分析时序数据。
3. LSTM关键在于神经细胞状态,LSTM通过门结构来去除或增加信息到细胞状态的能力(Sigmoid)。
4. 双向循环网络的基本思想是,提出每一个训练序列向前和向后分别是两个循环神经网络,而且这两个都连接着一个输出层。这个结构提供给输出层输入序列中每一个点的完整的过去和未来的上下文信息。
5. 利用循环神经网络解决分类的问题的基本过程是通过分析一段输入序列,通过LSTM分析判断得到对应的分类结果。
6. RNN本质上只能理解数字序列。
7. 自然语言分析技术大致分为3个层面:词法分析,句法分析和语义分析。
8. 语义角色标注(Semantic Role labeling, SRL)以句子的谓语中心,不对句子所包含的语义信息进行深入分析,只分析句子中各成分与谓词之间的关系,并用语义角色来描述这些结构关系。
9. 使用神经网络模型解决问题的思路通常是,前层网络学习输入的特征表示,网络的最后一层在特征基础上完成最终的任务。
10. 在SRL任务中,跟谓词搭配的名词称为论元,语义角色是指论元在动词所指事件中担任的角色。主要有:施事者(Agent)、受事者(Patient)、客体(Theme)、经验者(Experiencer)、受益者(Beneficiary)、工具(Instrument)、处所(Location)、目标(Goal)和来源(Source)等。深度LSTM网络学习输入的特征表示,条件随机场在特征的基础上完成序列标注,处于整个网络的末端。CRF是一种概率化结构,可以看作是一个概率无向图模型,节点表示随机变量,边表示随机变量之间的概率依赖关系。
11.
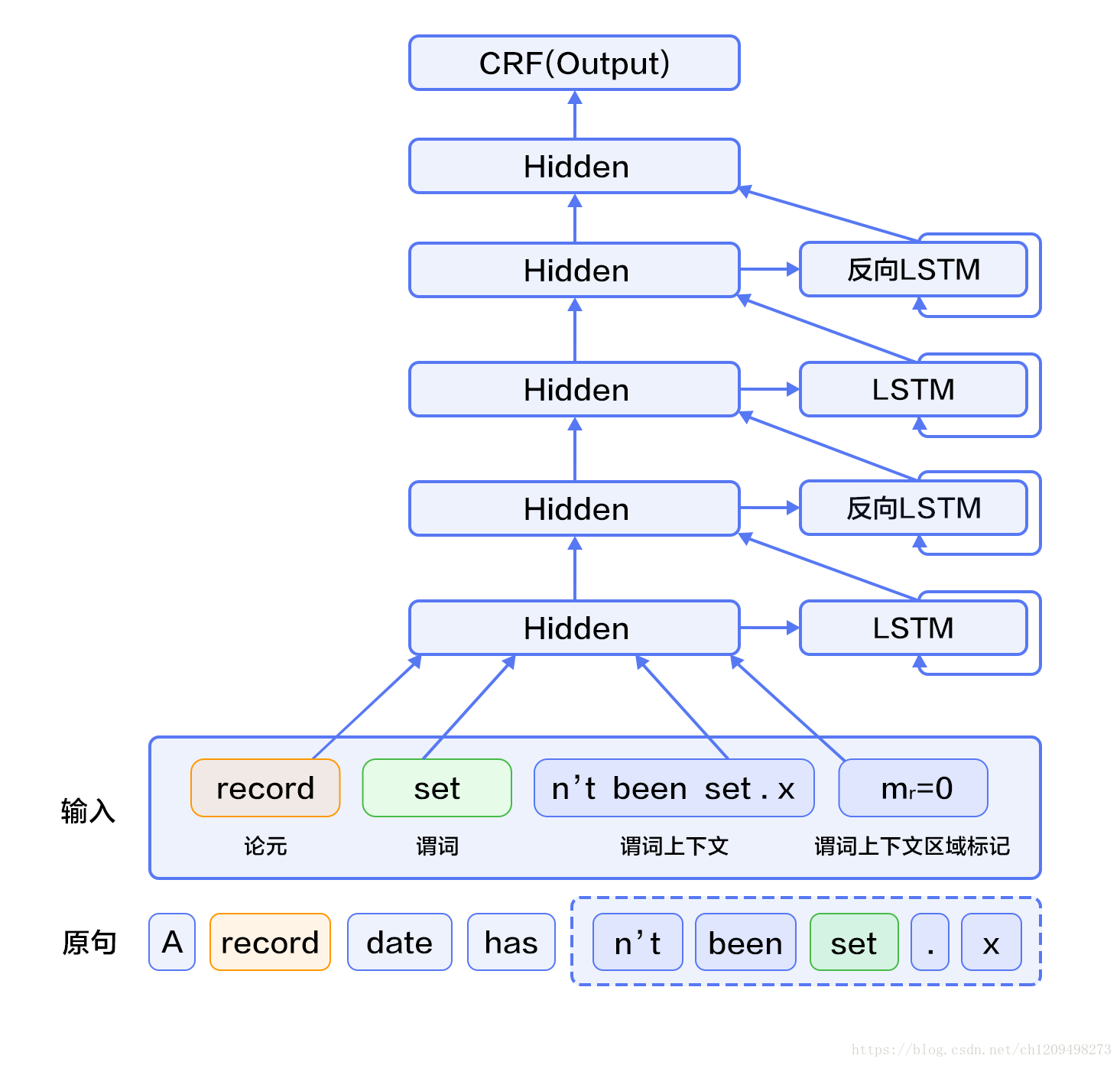
· 构造输入
· 输入1是句子序列,输入2是谓词序列,输入3是谓词上下文,从句子中抽取这个谓词前后各n个词,构成谓词上下文,用one-hot方式表示,输入4是谓词上下文区域标记,标记了句子中每一个词是否在谓词上下文中;
· 将输入2~3均扩展为和输入1一样长的序列;
· 输入1~4均通过词表取词向量转换为实向量表示的词向量序列;其中输入1、3共享同一个词表,输入2和4各自独有词表;
· 第2步的4个词向量序列作为双向LSTM模型的输入;LSTM模型学习输入序列的特征表示,得到新的特性表示序列;
· CRF以第3步中LSTM学习到的特征为输入,以标记序列为监督信号,完成序列标注;
12.
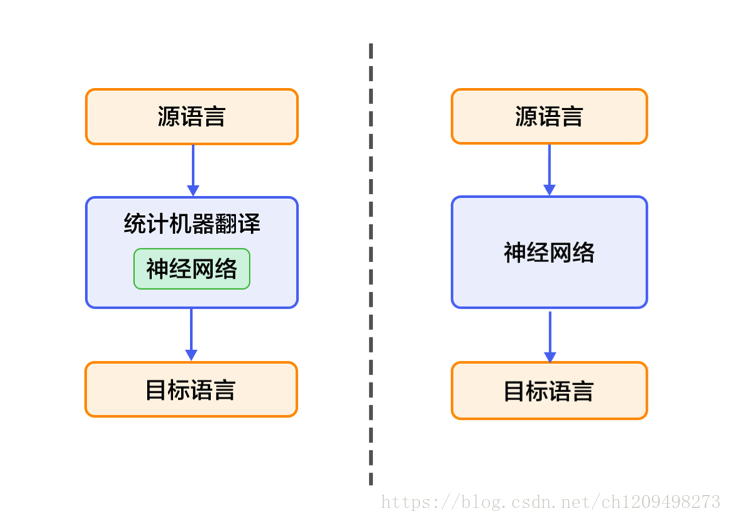
13. 左边的是仍以统计机器学习为框架,知识利用神经网络来改进其中的关键模块,如语言模型、调序模型等。
14. 右边的是不以统计机器学习为框架,直接用神经网络将源语言映射到目标语言,简称NMT(端到端的神经网络机器翻译)
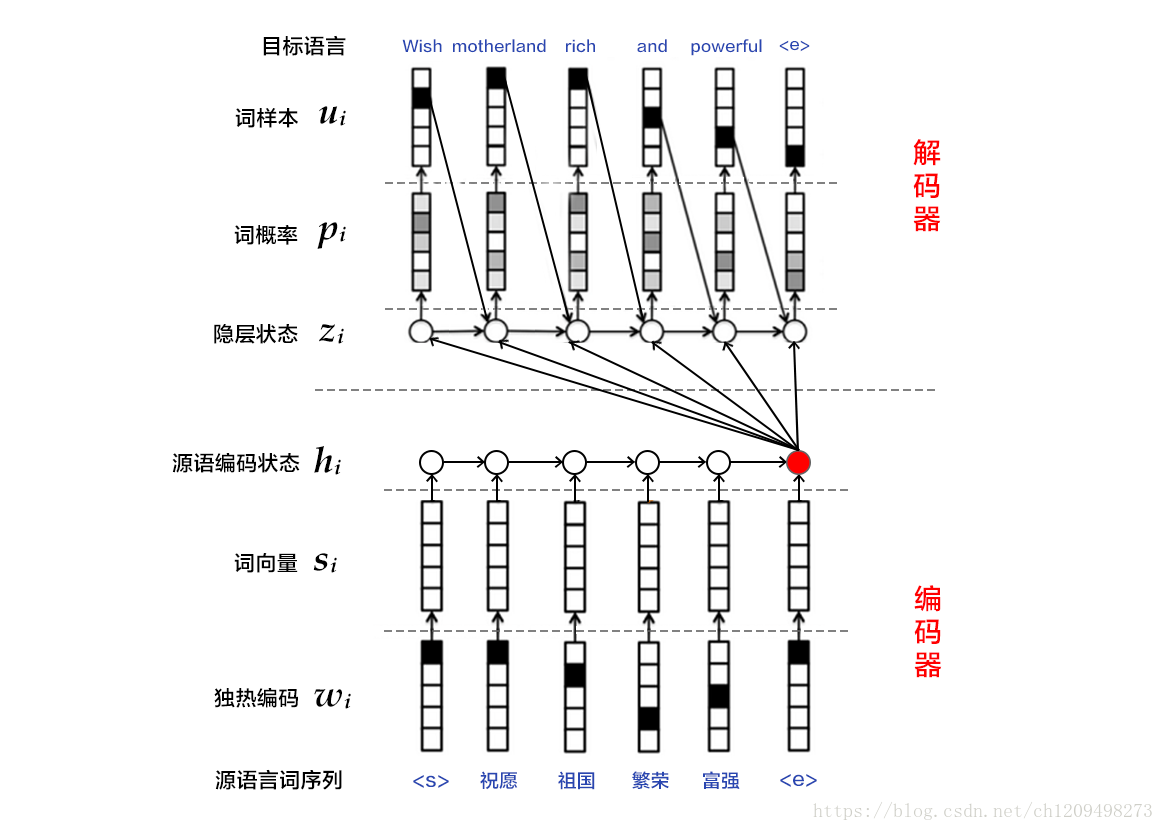
15. NMT用于解决由一个任意长度的源序列到另一个任意长度的目标序列的变换问题。即在编码阶段将整个源序列编码成一个向量,在解码阶段通过最大化预测序列概率,从中解码出整个目标序列。编码和解码的过程通常都使用RNN来实现机器翻译的NMT模型。
16.