专栏目录:pytorch(图像分割UNet)快速入门与实战——零、前言
pytorch快速入门与实战——一、知识准备(要素简介)
pytorch快速入门与实战——二、深度学习经典网络发展
pytorch快速入门与实战——三、Unet实现
pytorch快速入门与实战——四、网络训练与测试
续上文pytorch快速入门与实战——一、知识准备(要素简介)2.4章节
由于如果给网络内分模块的话,四级结构太过于庞大,而且本身篇幅太长,不便编写与阅读。
教程模块间独立性较高,任何地方均可跳跃性阅读,别管是不同文章之间,还是文章的不同模块。
怎么开心怎么来。反正都是从“这都是啥”到”呵呵就这“
部分列举的不详细是因为可以跳过,哪怕不懂。
可以只看ResNet和Unet。
也可以只看Unet。
深度学习经典网络发展
参考:晓强DL 专栏文章汇总
通过以下参考跳过机器学习对计算机视觉方面进行了解(我做图像处理肯定只关注CV啦!)
下面会描述一些比较重要的论文:AlexNet,VGG,GoogLe-1:Going Deeper with Convolutions, GoogLe-2:Batch Normalization,GoogLeNet-3,ResNet,FCN,UNet
(建议先上手网络再回来看这些比较好懂一些,比如我就是直接杀到ResNet再复现一个UNet的结构直接跑通然后再回来看这个发展历程的)反正就是卷积(邻近像素值分布)提取图像特征嘛。
1 AlexNet
1.1 意义
里程碑。拉开卷积神经网络统治计算机视觉的序幕 也加速计算机视觉应用落地。
1.2 结构
5个卷积层+3个全连接层
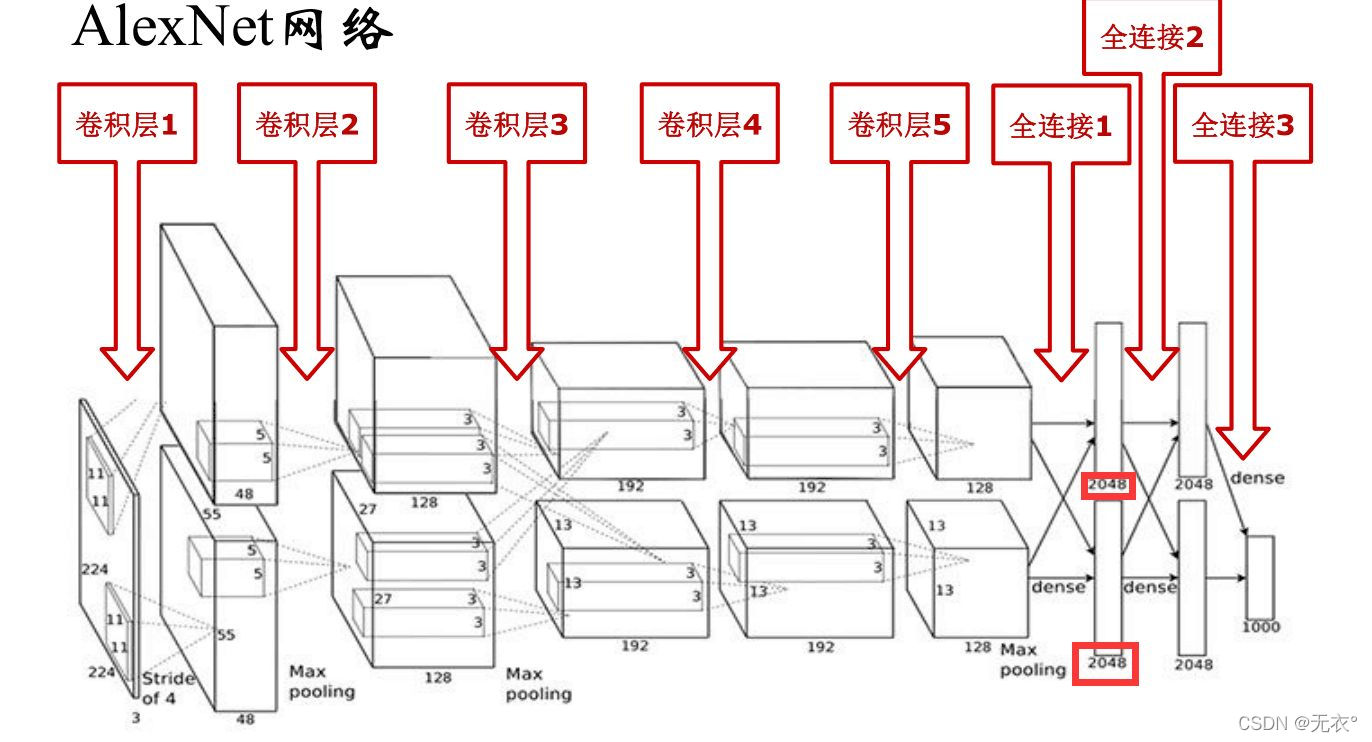
便于实现的网络图在VGG章节一同展示。
参考:必读论文AlexNet
2 VGG
2.1 意义
开启小卷积核时代。3*3卷积核成为主流模型。作为各类图像任务的骨干网络结构。
2.2 结构:
将5*5卷积层换成3*3卷积层
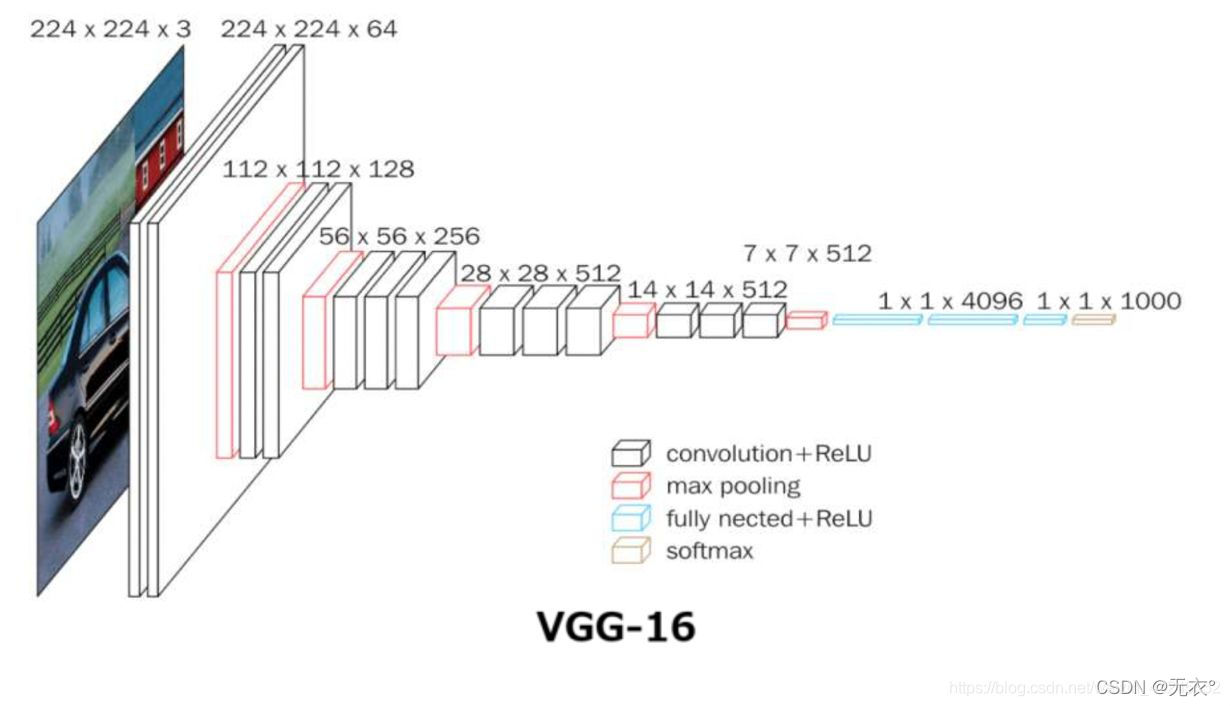
2.3 演变过程:
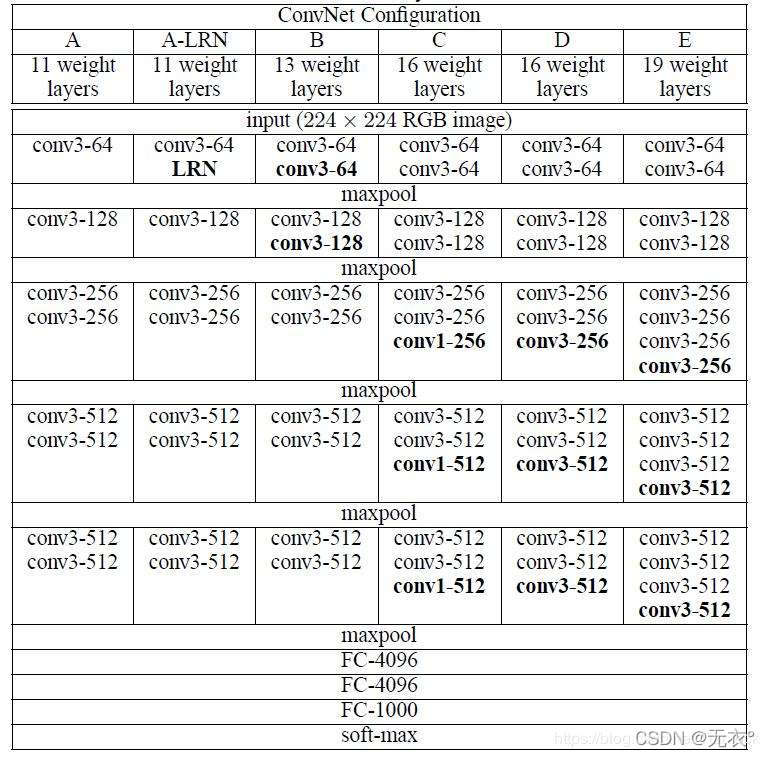
A:11层卷积
A-LRN:基于A增加一个LRN
B:第1,2个block中增加1个卷积3*3卷积
C:第3,4,5个block分别增加1个1*1卷积,表明增加非线性有益于指标提升
D:第3,4,5个block的1*1卷积替换为3*3,
E:第3,4,5个block再分别增加1个3*3卷积
其中AlexNet与VGG16和19的实现网络图(从下往上看):
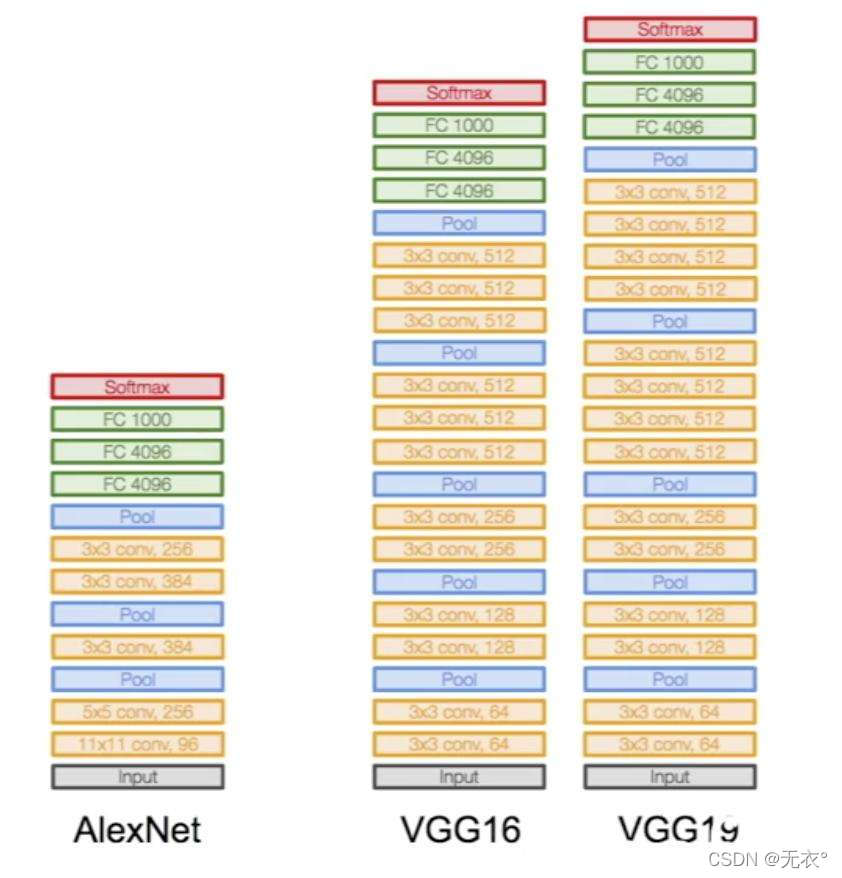
2.4 特点
增大感受野,2个3*3堆叠等价于1个5*5,3个3*3堆叠等价于1个7*7。
等价的原因自己推导或者参考上述文章
参考:必读论文VGG
3 GoogleNet
同为2014年与VGG齐头并进,联手冠亚。
- 使用1x1的卷积来进行升降维;
首个采用1*1卷积的卷积神经网络,舍弃全连接层,大大减少网络参数。拉开1*1卷积广泛应用序幕。- 在多个尺寸上同时进行卷积再聚合。开启多尺度卷积时代。
参考:
Going Deeper with Convolutions
深入理解GoogLeNet结构
4 GoogLe Net 2(BN网络层)
就是上一篇文章提到过的BN层。
4.1 意义
- 加快了深度学习的发展
- 开启神经网络设计新时代,标准化层已经成为深度神经网络标配
4.2 优点
- 可以用更大学习率,加速模型收敛
- 可以不用精心设计权值初始化
- 可以不用dropout或较小的dropout
- 可以不用L2或者较小的weight decay
- 可以不用LRN(local response normalization)
(1)你可以选择比较大的初始学习率,让你的训练速度飙涨。以前还需要慢慢调整学习率,甚至在网络训练到一半的时候,还需要想着学习率进一步调小的比例选择多少比较合适,现在我们可以采用初始很大的学习率,然后学习率的衰减速度也很大,因为这个算法收敛很快。当然这个算法即使你选择了较小的学习率,也比以前的收敛速度快,因为它具有快速训练收敛的特性;
(2)你再也不用去理会过拟合中drop out、L2正则项参数的选择问题,采用BN算法后,你可以移除这两项了参数,或者可以选择更小的L2正则约束参数了,因为BN具有提高网络泛化能力的特性;
(3)再也不需要使用使用局部响应归一化层了(局部响应归一化是Alexnet网络用到的方法,搞视觉的估计比较熟悉),因为BN本身就是一个归一化网络层;
(4)可以把训练数据彻底打乱(防止每批训练的时候,某一个样本都经常被挑选到,文献说这个可以提高1%的精度,这句话我也是百思不得其解啊)。
参考:
Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
5 GoogleNet-V3
这个我没细看,只是搬运过来
Rethinking the Inception Architecture for Computer Vision
5.1 简介VGG和GoogleV1和V2
VGG网络模型大,参数多,计算量大,不适用于真实场景。
GoogLeNet –V1 采用多尺度卷积核,1*1卷积操作。
GoogLeNet-V2 基础上加入BN层,并将5*5卷积全面替换为2个3*3卷积堆叠的形式,进一步提高模型性能。
5.2 对比V2
- 采用RMSProp优化方法
- 采用Label Smoothing正则化方法
- 采用非对称卷积提取17*17特征图
- 采用带BN的辅助分类
5.3 创新点
关键点&创新点
• 非对称卷积分解:减少参数计算量,为卷积结构设计提供新思路
• 高效特征图下降策略:利用stride=2的卷积与池化,避免信息表征瓶颈
• 标签平滑:避免网络过度自信,减轻过拟合
6 ResNet
终于到了ResNet,其实本人学习截止目前只看了ResNet和UNet。前面那些网络我也是写文章的时候才看的。
6.1 意义
近代卷积神经网络发展史的又一里程碑,突破千层网络,跳层连接成为标配。
个人理解:拐杖!
能够撑起所有网络一样的拐杖,让深度学习名副其实
和BN层一样,能够加强其他网络的效果,个人理解BN层是一种拨乱反正,训练着训练着分布歪了可怎么办,标准化矫正过来。
6.2 背景
在CNN网络中,我们输入的是图片的矩阵,也是最基本的特征,整个CNN网络就是一个信息提取的过程,从底层的特征逐渐抽取到高度抽象的特征,网络的层数越多也就意味这能够提取到的不同级别的抽象特征更加丰富,并且越深的网络提取的特征越抽象,就越具有语义信息。
所以一般我们会倾向于使用更深层次的网络结构,以便取得更高层次的特征。
6.3 问题与分析
但更深的网络并不总能带来好的结果。
网络深度增加时,网络准确度出现饱和,甚至出现下降。56层的网络比20层网络效果还要差。这不会是过拟合问题,因为56层网络的训练误差同样高。
而且过拟合有很多种解决方法,比如:数据增强,dropout(剪枝),正则等。
除了过拟合之外,深度网络还会带来梯度消失和梯度爆炸问题,但是这个问题也可以通过BN层来解决。而且若使用常用的激活函数ReLu的话,导数部分在正数是恒等于1,即梯度不变,所以不会导致梯度消失和爆炸。
即使加入了BN层,由于非线性激活函数Relu的存在,每次输入到输出的过程都几乎是不可逆的,这也造成了许多不可逆的信息损失,深度网络依然会出现退化问题(Degradation problem)。
导致这个原因也可能是因为随机梯度下降的策略,往往解到的并不是全局最优解,而是局部最优解,由于深层网络的结构更加复杂,所以梯度下降算法得到局部最优解的可能性就会更大。
6.4 解决思路
为了解决退化问题:我们需要在加深网络的同时,至少能保证深层网络的表现至少和浅层网络持平。也就是恒等映射:
有一个浅层网络,想通过向上堆积新层来建立深层网络,一个极端情况是这些增加的层什么也不学习,仅仅复制浅层网络的特征,即这样新层是恒等映射(Identity mapping)。在这种情况下,深层网络应该至少和浅层网络性能一样,也不应该出现退化现象。
6.5 解决方案
基于此,何博士提出残差学习的思想:
如果将深层网络的后面若干层学习成恒等映射h(x)=x,那么模型就退化成浅层网络。但是直接去学习这个恒等映射是很困难的,那么就换一种方式,把网络设计成:
H(x)=F(x)+x => F(x)=H(x)-x
只要 F(x)=0 就构成了一个恒等映射H(x) = x,这里 F(x) 为残差。
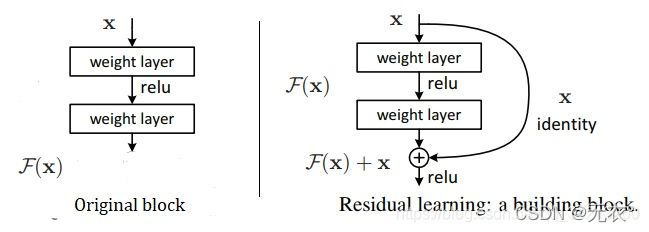
Resnet提供了两种方式来解决退化问题:identity mapping以及residual mapping。identity mapping指的是图中“弯线”部分,residual mapping指的是非“弯线”的剩余部分。F(x) 是求和前网络映射, H(x) 是输入到求和后的网络映射。
其实相比原图就是加了个恒等映射。
博客中作者举了这样一个例子:假设有个网络参数映射:g(x)和 h(x),这里想把5映射成5.1,那么 g(5)=5.1,引入残差的映射H(5)=5.1 = F(5)+5 => F(5)=0.1 。引入残差的映射对输出的变化更加敏感,比如从输出的5.1再变化到5.2时,映射 g(x) 的输出增加了1/51=2%。而残差结构输出的话,映射 F(x) 从0.1到0.2,增加了100%。明显后者的输出变化对权重的调整作用更大,所以效果更好。
这种残差学习结构通过前向神经网络+shortcut链接实现,其中shortcut连接相当于简单执行了同等映射,不会产生额外的参数,也不会增加计算复杂度。整个网络依旧可以通过端到端的反向传播训练。
引入shortcut connection,让网络信息有效传播,梯度反传顺畅,使得数千层卷积神经网络都可以收敛。

如图:残差网络可以表示成H(x)=F(x)+x,这就说明了在求输出H(x)对输入x的倒数(梯度),也就是在反向传播的时候,H’(x)=F’(x)+1,残差结构的这个常数1也能保证在求梯度的时候梯度不会消失。
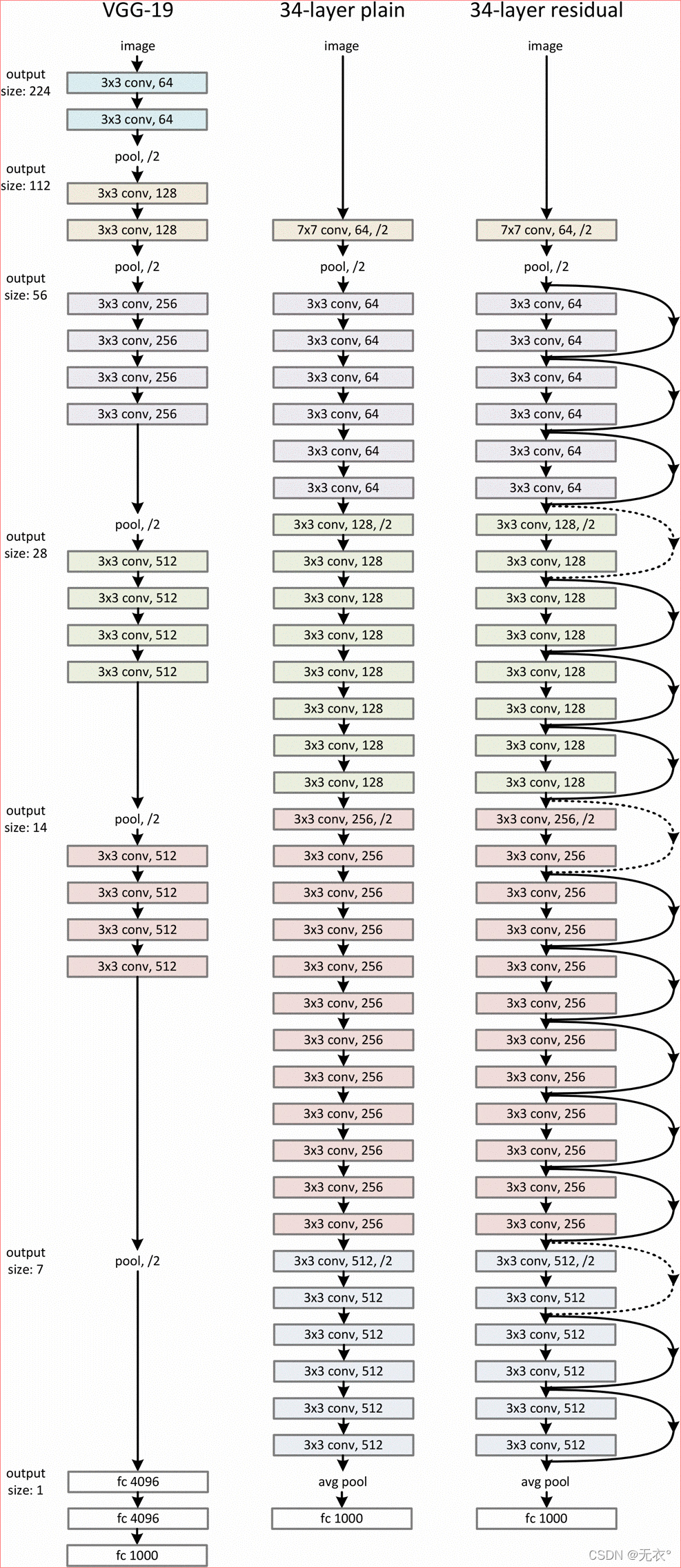
6.6 网络结构:
我认为的残差就是输入与输出的再结合,让输出不要太过于偏离输入。get到这个思想其实也就可以了。
6.7 实现细节
在ResNet中有的跳接线是实线,有的跳接线是虚线。
虚线的代表这些模块前后的维度不一致,因为去掉残差结构的Plain网络还是和VGG一样,也就是每隔n层进行下采样但深度翻倍(VGG通过池化层下采样ResNet通过卷积)。
深度上不一致时,有两种解决方法,一种是在跳接过程中加一个1×1的卷积层进行升维,另一种则是直接补零(先做下采样)
针对比较深的神经网络,考虑到计算量,会先用1×1的卷积将输入的256维降到64维,然后通过1×1恢复。这样做的目的是减少参数量和计算量。
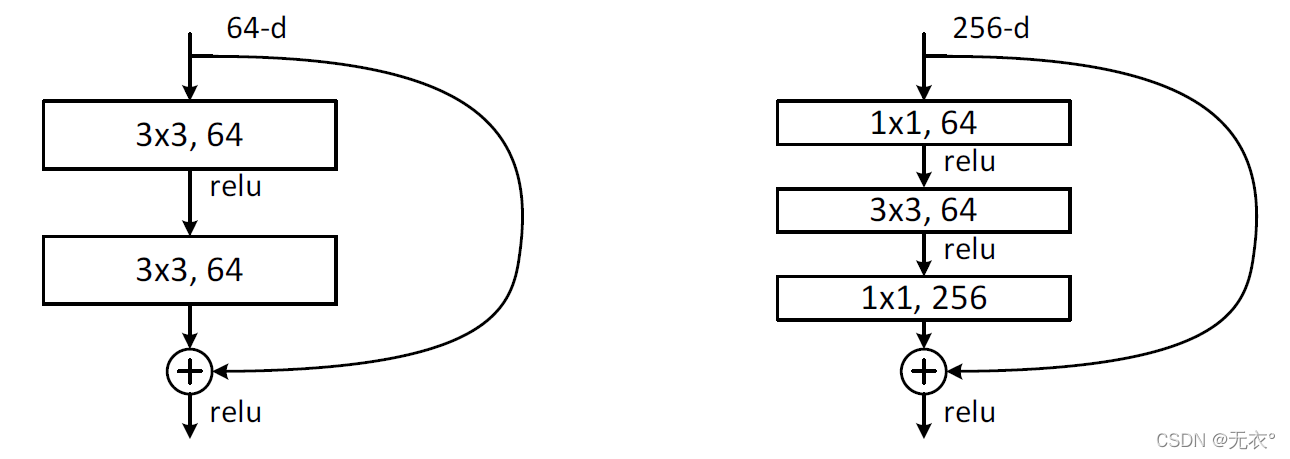
两种结构分别针对ResNet34(左图)和ResNet50/101/152(右图),其目的主要就是为了降低参数的数目。
左图是两个3x3x256的卷积,参数数目: 3x3x256x256x2 = 1179648,
右图是第一个1x1的卷积把256维通道降到64维,然后在最后通过1x1卷积恢复,整体上用的参数数目:1x1x256x64 + 3x3x64x64 + 1x1x64x256 = 69632,
右图的参数数量比左图减少了16.94倍,因此,右图的主要目的就是为了减少参数量,从而减少计算量。
注意计算左图参数的时候是假设通道数为256的所以是乘256而不是64,因为低通道用左,高通道用右
你必须要知道CNN模型:ResNet
图像处理必读论文之六 ResNet
深度学习之16——残差网络(ResNet)
CVPR2016:ResNet 从根本上解决深度网络退化问题
7 FCN
(不要问为什么不放网络结构图,这玩意不就是给UNet铺路)看Unet就行了
CNN是图像级的识别,也就是从图像到结果。
而FCN是像素级的识别,标注出输入图像上的每一个像素最可能属于哪一类别
7.1 背景
从AlexNet开始的CNN卷积网络在图像的分类和定位任务中都有不错的成绩,基本都是在李飞飞等人于2010年创办的ImageNet Large Scale Visual Recognition Challenge (ILSVRC:大规模图像识别挑战赛)的背景下。
比赛项目涵盖:图像分类(Classification)、目标定位(Object localization)、目标检测(Object detection)、视频目标检测(Object detection from video)、场景分类(Scene classification)、场景解析(Scene parsing)
但随着深度学习的应用拓展,无论是NLP(自然语言理解)领域的语义分割还是CV(计算机视觉)领域图像分割,原始的CNN都无法解决。对于一般的分类CNN网络,如VGG和Resnet,都会在网络的最后加入一些全连接层,经过softmax后就可以获得类别概率信息。但是这个概率信息是1维的,即只能标识整个图片的类别,不能标识每个像素点的类别,所以这种全连接方法不适用于图像分割。
而全卷积网络(Fully Convolution Network, FCN)提出可以把后面几个全连接都换成卷积,这样就可以获得一张2维的feature map,后接softmax获得每个像素点的分类信息进行像素级的预测(pixelwise prediction),从而解决了分割问题。
7.2 技术实现:
关于这三点(或者对于某些概念和原因),如果不太懂的话建议看完Unet再回来看这一点,Unet已经完美体现了这些。如果在这里解释显得太过冗余和乱。
- 全卷积化(Fully Convolutional)
不含全连接层(fc)的全卷积(fully conv)网络。
把传统CNN最后的全连接层换成了卷积层。
- 可适应任意尺寸输入和输出(通过修改卷积的kernel,padding和stride能改变size和channels)
- 反卷积(Deconvolution)
没有沿用以往的插值上采样(Interpolation),而是提出了新的上采样方法,即反卷积(Deconvolution)。反卷积可以理解为卷积操作的逆运算,反卷积并不能复原因卷积操作造成的值的损失,它仅仅是将卷积过程中的步骤反向变换一次,因此它还可以被称为转置卷积。
- 利用反卷积能够输出精细的结果(卷积的权重可都是参与反向传播的!)
个人觉得:反卷积这名字取的就不太好,但是转置卷积就很合适,为什么呢?其实转置卷积还是一种卷积,只是一种参数不同的卷积罢了。所以在pytorch里面函数名也是transposed2d。
让我想想怎么描述这个不同:stride (反卷积的步长永恒为1,其参数stride不表示步长)
一般卷积的参数stride=n表示步长为n,
转置卷积的参数stride=n表示每两个像素点中间插n-1个,那其步长呢?永远是1。OK,看例子:
当参数stride=1时,反卷积与卷积无异。
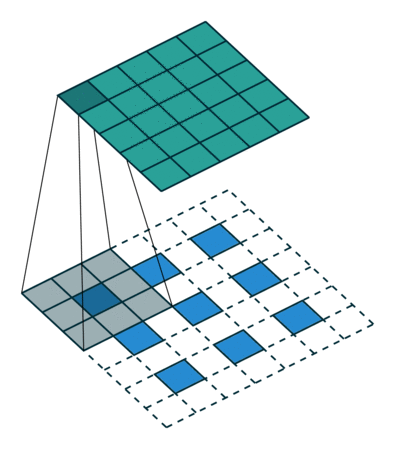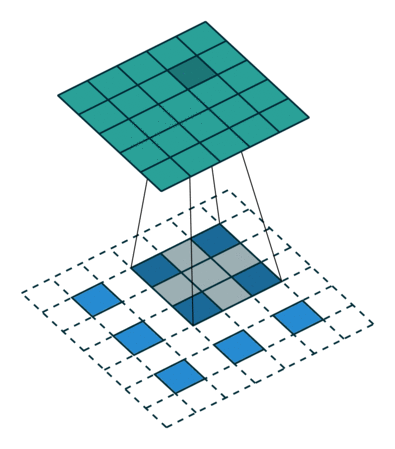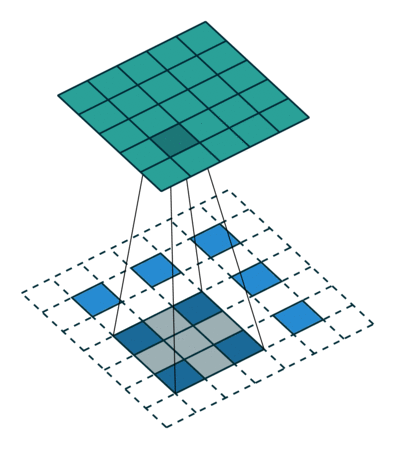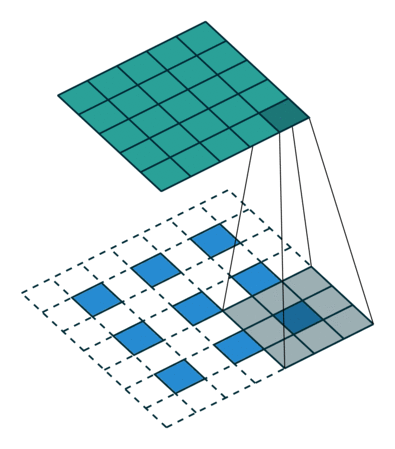
如下图反卷积:蓝色input=2x2,移动的灰色kernels_size=3x3,边缘白色padding=2,stride=1,此时绿色output为4x4.
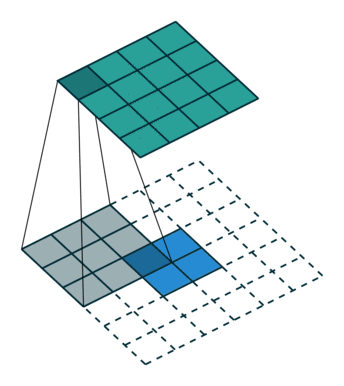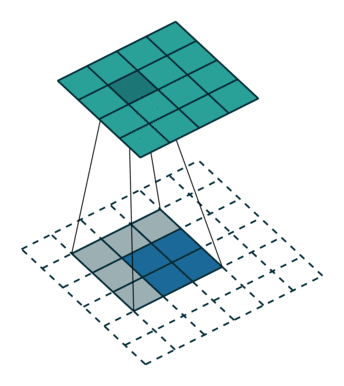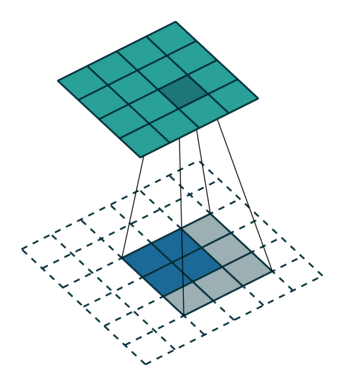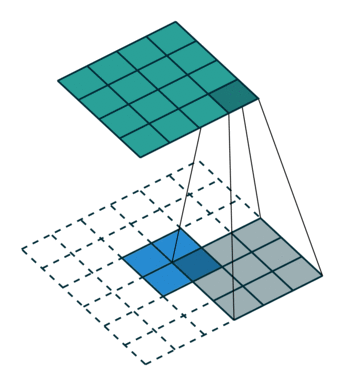
那参数stride!=1的时候呢?如上所说,表示中间插几个。
如下图反卷积:input=3x3,kernels_size=3x3,padding=1,stride=?,绿色output=5x5
答案是2,如图所示蓝色input每两个像素点中间都插入了1个白色像素,所以参数stride=1+1=2.
kernel移动的步长永恒是1.
- 跃层结构(Skip Layer)
不同深度特征的结合,是对前后特征图的补偿。
(本人理解:时刻提醒网络向实际靠拢,不要跑偏)和残差类似,现阶段不要过多想。
- 能够增强网络的鲁棒性和准确性。
参考:
图像分割:语义分割中的全卷积网络(FCN)
FCN的学习及理解
全卷积网络(FCN)详解
7.3 历史意义:
• 语义分割领域的开山之作
• 端到端训练为后续语义分割算法的发展铺平了道路
7.4 其他相关概念
7.4.1 局部信息
- 提取位置:浅层网络中提取局部信息
- 特点:物体的几何信息比较丰富,对应的感受野较小
- 目的:有助于分割尺寸较小的目标,有利于提高分割的精确程度
7.4.2 全局信息
- 提取位置:深层网络中提取全局信息
- 特点:物体的空间信息比较丰富,对应的感受野较大
- 目的:有助于分割尺寸较大的目标,有利于提高分割的精度
7.4.3 感受野
在卷积神经网络中,决定某一层输出结果中一个元素所对应的输入层的区域大小,被称作感受野。
通常来说,大感受野的效果要比小感受野的效果更好。
由公式可见,stride越大,感受野越大。但是过大的stride会使feature map保留的信息变少。
因此,在减小stride的情况下,如何增大感受野或使其保持不变,称为了分割中的一大问题。
7.4.4 端到端
在计算机视觉领域,端到端可以简单地理解为,输入是原始图像,输出是预测图像,中间的具体过程依赖于算法本身的学习能力。
通过网络内部结构,对原始图像进行降维和特征提取,并在后续过程中将尺寸较小的特征图逐渐恢复成与原图尺寸相同的预测图。
特征提取的好坏将直接影响最后的预测结果,端到端网络的最主要特点就是根据设计好的算法自己学习特征,而不需要人为干预。
降维和特征提取过程就是下采样,恢复尺寸的过程就是上采样。
看Unet就懂了。
8 UNet
8.1 研究成果及意义:
- 速度快,对一个512*512的图像,使用一块GPU只需要不到一秒的时间
- 成为大多做医疗影像语义分割任务的baseline,也启发了大量研究者去思考U型语义分割网络
- U-Net结合了低分辨率信息(提供物体类别识别依据)和高分辨率信息(提供精准分割定位依据),完美适用于医学图像分割。
基本上所有的分割问题,都可以拿U-Net先看一下基本的结果,然后进行“魔改”。
8.2 网络结构
先放结构图:百度找到的图,感觉比官方图更香,主要是有个与分类的对比,对于萌新更友好一些。
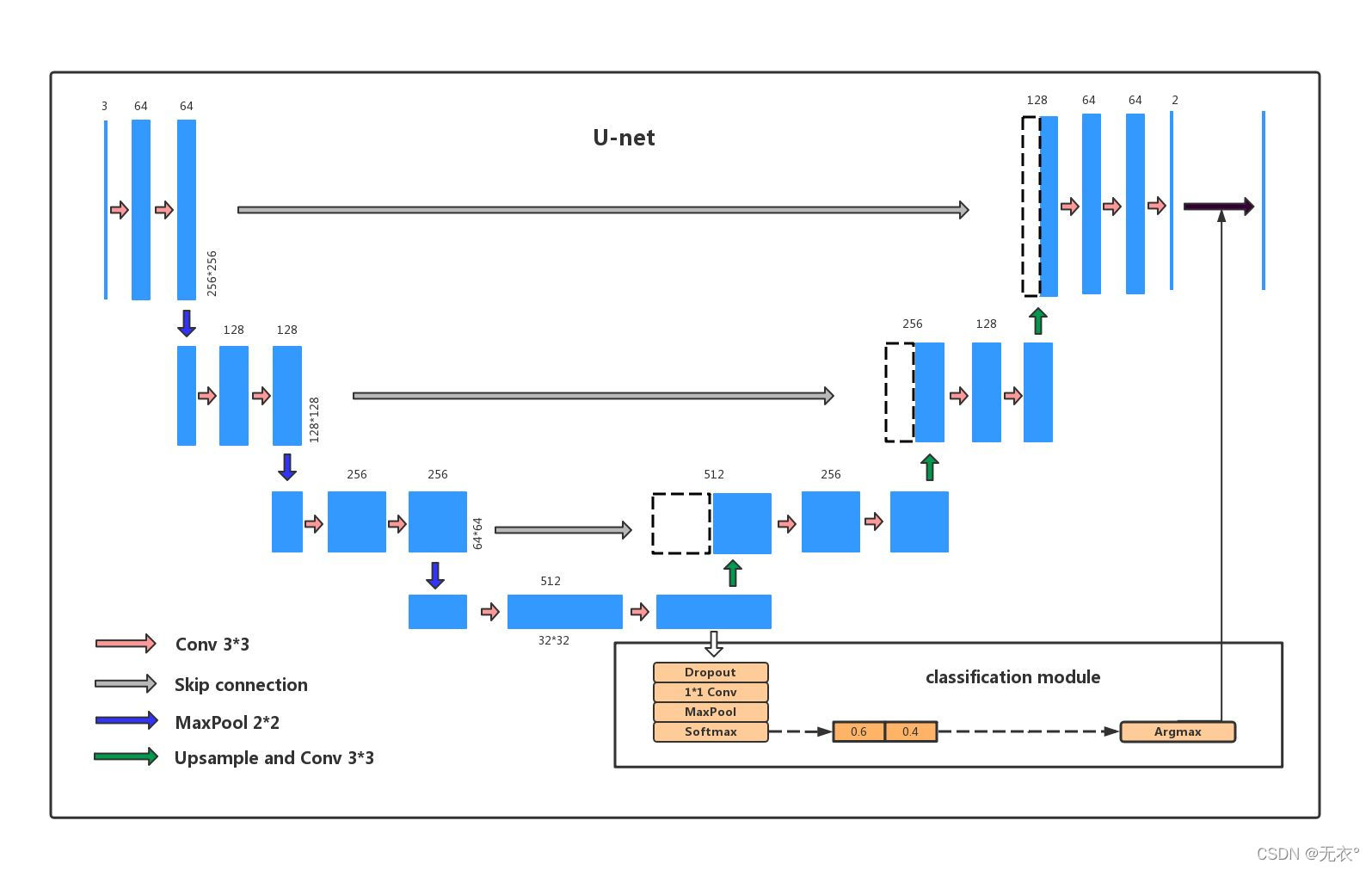
说一下这个图,右下角那个框里的部分是分类模型的结构图,U-net是不包括这部分的,放出来只是体现出一个区别出来。
先借用知乎@陈亦新的说法,简单说下这个图:
左半部分Encoder:
由两个3x3的卷积层(RELU)再加上一个2x2的maxpooling层组成一个下采样的模块(后面代码可以看出);
右半部分Decoder:
由一个上采样的卷积层(去卷积层)+特征拼接concat+两个3x3的卷积层(ReLU)反复构成;
OK,开始解析。
- 首先整体来看,是一个U型对称结构。拆开之后是与FCN相同的结构思路:
左边是下采样(编码Encoder),右边是上采样(解码Decoder)。
在拆解看之前,我们将3*3卷积层Conv+激活函数ReLu+Bn层作为一个整体,称为block
- 从最顶层开始分层看,左边蓝色矩形是输入,经过两个block得到一个输出(channel=64的矩形),接下来往下走,看到是一个2*2的最大池化maxpool(就是把2*2矩形内的最大值挑出来,这样2*2就变成了1个数,size的长和宽都变成一半),然后进行下一层的block+maxpool。
【上图是3次下采样,一共4层。Unet原文是4次下采样一共5层,但这个没有定数,无伤大雅。】 - 循环到最底层之后下采样结束,准备上采样。
- 上采样如图结构是block+反卷积(反卷积过程在FCN里说了,上采样是反卷积替代了最大池化)。
3次上采样回去,得到与原输入size一样的输出。 - 结束!
- 值得注意的是,左边与右边是通过一个灰色的线连接起来的,这个线是Skip connection,原Unet论文中叫做copy and crop。其实就是个残差思想:将左边的输出与下边的输出拼接起来作为右边这一层的输入。
补充一点更细节的东西:
FCN的decoder相对简单,只用了一个deconvolution的操作,之后并没有跟上卷积结构。
对于skip connection,FCN用的是加操作(summation),U-Net用的是叠操作(concatenation)。
关于add 和concat操作可以参考:深度特征融合—理解add和concat之多层特征融合这篇文章来了解。
8.3 模块作用
- 卷积(Conv)用于特征提取;
- 池化(maxpool)用于降低维度;
- 拼接(skip-connection)用于特征融合;【所以通道就是特征】
- 上采样(Upsample)用于恢复维度;
从更大的角度来看:
- 下采样(编码Encoder):使得模型理解了图像的内容,但是丢弃了图像的位置信息。
- 上采样(解码Decoder):使模型结合Encoder对图像内容的理解,恢复图像的位置信息。
那么我们就知道不同层的区别:
- 浅层主要是几何信息,图像内容是什么,看到的是小视野的东西(就是你放大能看到啥,比如猫的眼睛啥颜色)
- 深层主要是位置信息,图像位置有什么,看到的是大视野的东西(就是你缩小能看到啥,比如猫在图片的什么位置)
8.4 代码实现
嘿嘿,终于到了这一步,虽然……但是,其实还是有很多细节的。单开一篇,一起加油吧。
pytorch快速入门与实战——三、Unet实现