第一门课会以猫作为对象识别
第二门课中,学习超参数调整、正则化、诊断偏差和方差以及一些高级优化算法,比如 Momentum 和 Adam 算法。
第三门课中,我们将使用两周时间来学习如何结构化你的机器学习工程。
第四门课程中,我们将会提到卷积神经网络(CNN(s)),它经常被用于图像领域,你将会在第四门课程中学到如何搭建这样的模型。
在第五门课中,你将会学习到序列模型,以及如何将它们应用于自然语言处理,以
及其它问题
第一周:深度学习引言(Introduction to Deep Learning)
1、RELU 激活函数
2、神经网络的一部分神奇之处在于,当你实现它之后,你要做的只是输入 x,就能得到输出 y。
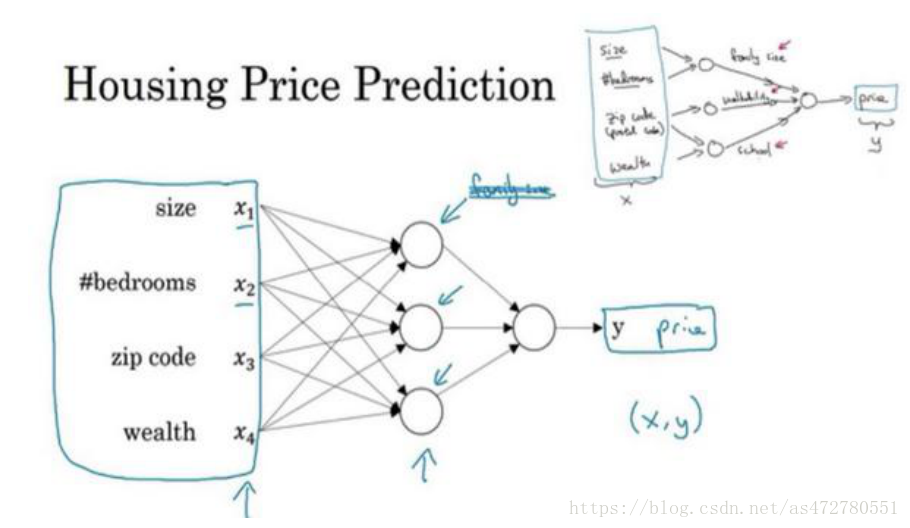
这里有四个输入的神经网络,这输入的特征可能是房屋的大小、卧室的数量、邮政编码和区域的富裕程度。
3、图像应用, 我们经常在神经网络上使用卷积(Convolutional Neural Network) , 通常缩写为 CNN。
对于序列数据, 例如音频, 有一个时间组件, 随着时间的推移, 音频被播放出来, 所以音频是最自然的表现。 作为一维时间序列(两种英文说法放出来, 所以音频是最自然的表现。
作为一维时间序列(两种英文说法 one-dimensional timeseries / temporal sequence) .对于序列数据, 经常使用 RNN, 一种递归神经网络(RecurrentNeural Network) , 语言, 英语和汉语字母表或单词都是逐个出现的, 所以语言也是最自然的序列数据。
4、卷积神经网络通常用于图像数据
5、将要讨论的许多技术都将适用, 不论是对结构化数据还是非结构化数据。 为了解释算法, 我们将在使用非结构化数据的示例中多画一点图片, 但正如你所想的, 你自己团队里通过运用神经网络, 我希望你能发现, 神经网络算法对于结构化和非结构化数据都有用处。
6、只用了一行代码。 所以, 我打算先构建一个 1*m的矩阵, 实际上它是一个行向量, 同时我准备计算z1、z2..., 所有值都是在同一时间内完成
7、Z = np.dot(w.T,X) + b
8、numpy 广播机制

9、在统计学里面, 有一个方法叫做最大似然估计, 即求出一组参数, 使这个式子取最大值,也就是说, 使得这个式子取最大值
第三周: 浅层神经网络(Shallow neural networks)
1、其中, x表示输入特征, ܽα表示每个神经元的输出, ܹw表示特征的权重, 上标表示神经网络的层数(隐藏层为 1) , 下标表示该层的第几个神经元。 这是神经网络的符号惯例, 下同。
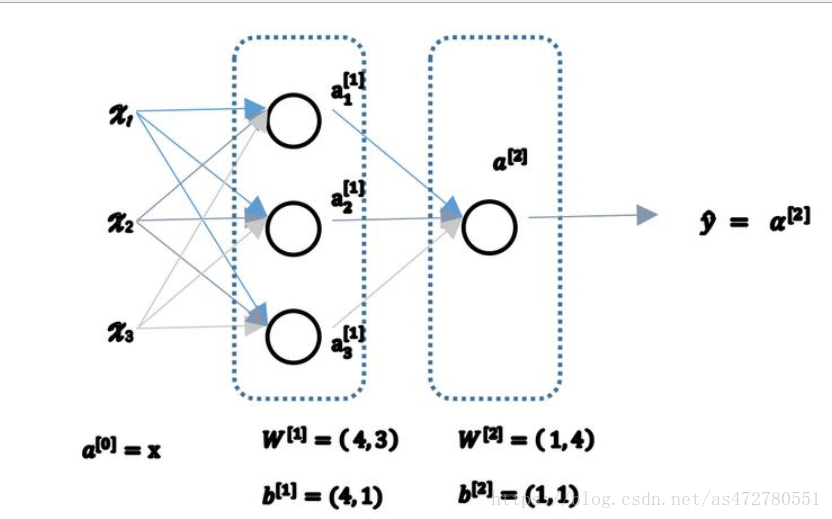
2、用向量化的方法, 可以不需要显示循环
3、随着网络的深度变大, 基本上也还是重复这两步运算, 只不过是比这里你看到的重复次数更多。 在下周的视频中将会讲解更深层次的神经网络, 随着层数的加深, 基本上也还是重复同样的运算
4、在讨论优化算法时, 有一点要说明: 我基本已经不用 sigmoid 激活函数了, tanh 函数在所有场合都优于 sigmoid 函数。
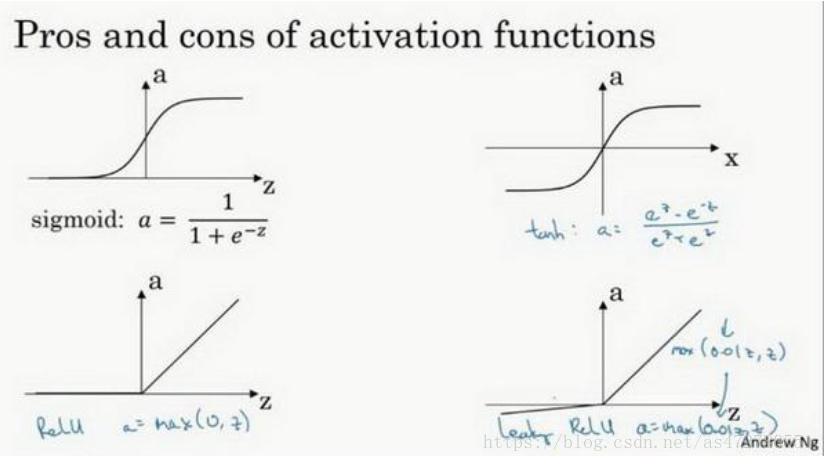
5、sigmoid 激活函数: 除了输出层是一个二分类问题基本不会用它。
tanh 激活函数: tanh 是非常优秀的, 几乎适合所有场合。
ReLu 激活函数: 最常用的默认函数, , 如果不确定用哪个激活函数, 就使用 ReLu 或者Leaky ReLu。
6、通常的建议是: 如果不确定哪一个激活函数效果更好, 可以把它们都试试, 然后在验证集或者发展集上进行评价。 然后看哪一种表现的更好, 就去使用它。
7、在选择自己神经网络的激活函数时, 有一定的直观感受, 在深度学习中的经常遇到一个问题: 在编写神经网络的时候, 会有很多选择: 隐藏层单元的个数、 激活函数的选择、 初始化权值……
8、事实证明, 如果你使用线性激活函数或者没有使用一个激活函数,那么无论你的神经网络有多少层一直在做的只是计算线性函数, 所以不如直接去掉全部隐藏层。 在我们的简明案例中, 事实证明如果你在隐藏层用线性激活函数, 在输出层用 sigmoid 函数, 那么这个模型的复杂度和没有任何隐藏层的标准 Logistic 回归是一样的
9、正向传播、反向传播
np.sum是 python的 numpy命令,axis=1表示水平相加求和
10、直观理解反向传播(Backpropagation intuition)
11、把 ܹW[1]设为np.random.randn(2,2)(生成高斯分布),通常再乘上一个小的数,比如 0.01,这样把它初始化为很小的随机数。 然后b没有这个对称的问题(叫做 symmetry breaking problem) ,所以可以把b初始化为 0,因为只要随机初始化W你就有不同的隐含单元计算不同的东西,因此不会有 symmetry breaking 问题了。相似的, 对于 ܹW[2]你可以随机初化b[2]可以初始化为 0
