文章目录
- 第四周:深层神经网络(Deep Neural Networks)
- 4.1 深层神经网络(Deep L-layer neural network)
- 4.2 前向传播和反向传播(Forward and backward propagation)
- 4.3 深层网络中的前向传播(Forward propagation in a Deep Network)
- 4.4 核对矩阵的维数(Getting your matrix dimensions right)
- 4.5 为什么使用深层表示?(Why deep representations?)
- 4.6 搭建神经网络块(Building blocks of deep neural networks)
- 4.7 参数VS超参数(Parameters vs Hyperparameters)
- 4.8 深度学习和大脑的关联性(What does this have to do with the brain?)
注:图片来源于网络
第四周:深层神经网络(Deep Neural Networks)
4.1 深层神经网络(Deep L-layer neural network)
逻辑回归(左)和神经网络(右)结构图

隐藏层数量

符号定义:

上图是一个四层的神经网络,有三个隐藏层。
第一层有5个神经元数目,第二层5个,第三层3个。
我们用L表示层数,上图:L=4,输入层的索引为“0”,第一个隐藏层n[1]=5,表示有5个隐藏神经元,同理n[2]=5,n[3]=3,n[4]=n[L]=1(输出单元为1)。而输入层,n[0]=nx=3。
4.2 前向传播和反向传播(Forward and backward propagation)
前向传播:
输入a[l-1],输出是a[l],缓存为z[l];从实现的角度来说我们可以缓存下w[l]和b[l],这样更容易在不同的环节中调用函数。

反向传播:
输入为da[l],输出为da[l-1],dw[l],db[l]


4.3 深层网络中的前向传播(Forward propagation in a Deep Network)

这里只能用一个显式for循环,l从1到L,然后一层接着一层去计算
4.4 核对矩阵的维数(Getting your matrix dimensions right)
当实现深度神经网络的时候,检查一遍算法中矩阵的维数
W的维度是(下一层的维数,前一层的维数),即:W[l] (n[l],n[l-1]);
b的维度是(下一层的维数,1),即:b[l]:(n[l],1);
z[l],a[l] : (n[l],1);
m个样本向量化后:

4.5 为什么使用深层表示?(Why deep representations?)
深度神经网络的隐藏层中,前几层能学习一些低层次的简单特征,后几层能把简单的特征结合起来,去探测更加复杂的东西。
深层的网络隐藏单元数量相对较少,隐藏层数目较多,如果浅层的网络想要达到同样的计算结果则需要指数级增长的单元数量才能达到。
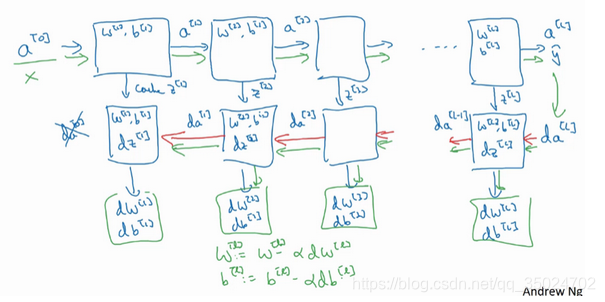
4.6 搭建神经网络块(Building blocks of deep neural networks)
正向传播的步骤:
把输入特征a[0],放入第一层并计算第一层的激活函数,用表示a[1],你需要W[1]和b[1]来计算,之后也缓存z[1]值,之后喂到第二层。
第二层里,需要用到W[2]和b[2],你会需要计算第二层的激活函数a[2]。
后面几层以此类推,直到最后你算出了a[L],第L层的最终输出值y’。
在这些过程里我们缓存了所有的值。
反向传播的步骤:
我们需要算一系列的反向迭代,就是这样反向计算梯度。
你需要把da[L]的值放在这里,然后这个方块会给我们da[L-1]的值,以此类推,直到我们得到da[2]和da[1]。反向传播步骤中也会输出dW[l]和db[l]。
dw[l]和b[l]用于参数更新:
4.7 参数VS超参数(Parameters vs Hyperparameters)
算法中的learning rate a(学习率)、iterations(梯度下降法循环的数量)、L(隐藏层数目)、n[l](隐藏层单元数目)、choice of activation function(激活函数的选择)都需要你来设置,这些数字实际上控制了最后的参数W和b的值,所以它们被称作超参数。
实际上深度学习有很多不同的超参数,如momentum、mini batch size、regularization parameters等等。
寻找超参数的最优值:
走Idea—Code—Experiment—Idea这个循环,尝试各种不同的参数,实现模型并观察是否成功,然后再迭代。
4.8 深度学习和大脑的关联性(What does this have to do with the brain?)

