原文地址:https://blog.csdn.net/elaine_bao/article/details/50458463
文章地址:
A CONVNET FOR NON-MAXIMUM SUPPRESSION (2016 ICLR Under Review)
A brief introduction of NMS for object detection
NMS,即Non-maximum suppression,非极大值抑制,在object dection中应用非常广泛,简单地说,他就是对一些region proposals(物体的候选框)进行筛选,得到最佳的物体检测位置。

如上图所示,在做人脸检测时我们可能会得到多个人脸的候选框,但是其实这些框完全可以进行“合并”,得到一个人脸的框框。这个“合并”的策略就是NMS。NMS主要有两个指标来进行合并:
1.score:对于每一个proposal,分类器会给出一个score来表示当前候选框的置信度,尽量保留置信度较高的候选框
2.IoU(Intersection-over Union):重叠面积,位置邻近的候选框重叠面积大于一定阈值的话则进行合并
所以NMS的实现是:
1. NMS计算出每一个bounding box的面积,然后根据score进行排序。
2. 计算其余bounding box与当前最大score的box的IoU,去除IoU大于设定的阈值的bounding box。
3. 重复上面的过程,直至候选bounding box为空。
需要注意的是:NMS一次处理一个类别,如果有N个类别,NMS就需要执行N次。
NMS的缺点:
NMS的合并策略是一种较贪婪的方法,在平衡精度和召回率时会有问题。例如出现两个人脸靠得很近的情况,我们首先得到了许多红色的region proposal,然后用NMS来筛选候选框。
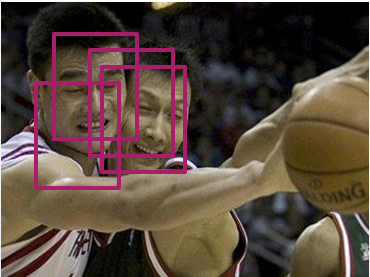
假设我们能设置一个合适的阈值,那么两个人脸可以被两个框分别框住。
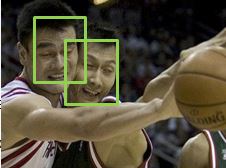
如果我们将IoU阈值设定得高一些,也就是说合并相对困难,则会出现下图(a)的筛选结果,说明非极大值抑制得不够充分;那么我们将IoU阈值设定得低一些,合并相对容易,就会得到下图(b)的结果,也就是说多个ture positive被merge到了一起。

Convnet for NMS
2.1 Overview
传统的NMS在判决融合的时候,只利用到了2个信息:Score 和 IOU ,即每个框的得分和框与框之间的重叠比例。
文章用神经网络去实现NMS,所利用的同样也是这2个信息。如下图的整个流程图:
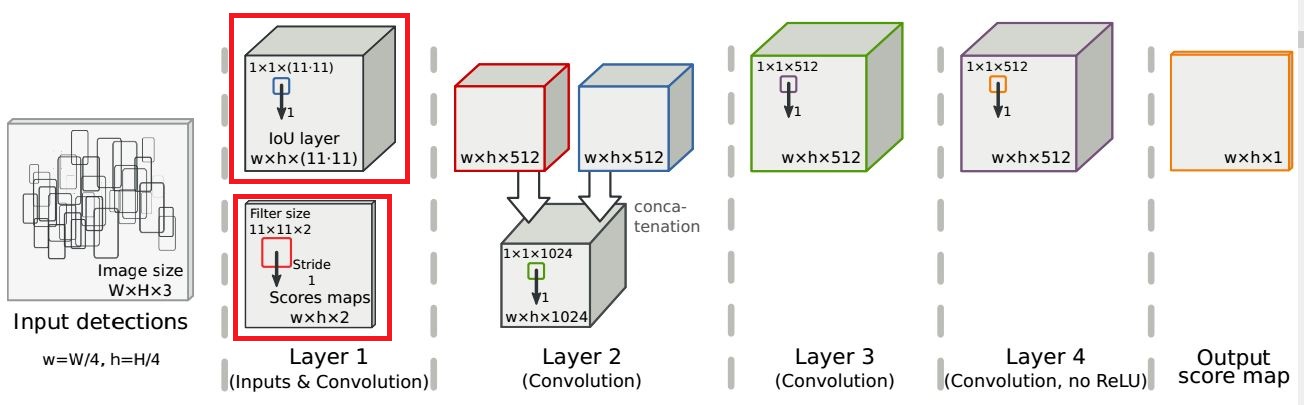
2.2 Score map的生成
假设我们的图片是W*H的,在这里我们以16*16大小的图片为例,我们对他生成w*h大小的score map,其中w=W/4,h=H/4,也就是说score map上的一个点对应原图中4*4的区域。然后假设我们得到了一个物体的bounding box,其置信度为0.8,我们将其中心点的位置记录在score map中,因为他的中心点落在第(3,2)个score map区域中,因此该区域置信度为0.8;接着我们又得到一个新的bounding box,其置信度为0.9,且中心点也落在了(3,2)的区域,根据NMS保留大置信度的特点,我们对该区域的置信度进行更新,也就是说(3,2)这个区域的置信度变成了0.9。注意在更新置信度的时候,我们也保留了原始bounding box的原始位置信息,以便最终的索引。

到此,我们已经得到了w×h×1的score map.
文章提到,卷积神经网络的线性操作和relu无法模仿NMS中对score进行排序的操作, 因此,文章先用传统的NMS处理一遍bounding boxes, 然后再生成一张同样大小的score map,记作S(T),T为NMS的阈值。
最终,我们得到了w×h×2的score map. 记作S(1,T)
2.3 IoU layer
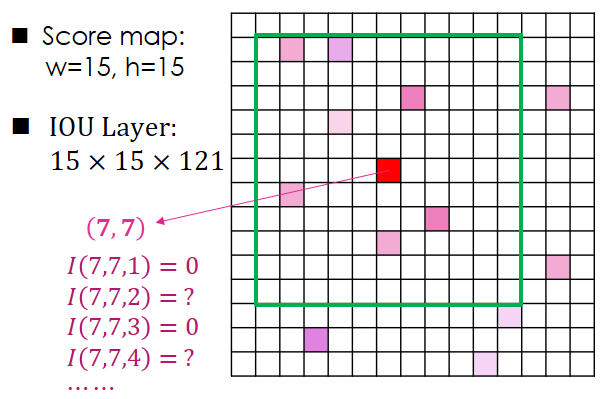
NMS的另一个重要概念是通过重叠面积来筛选候选框。这一步在convnet中是这么做的:对于score map上的每个点,我们已经记录了其是否包含bounding box以及该box的置信度。那么我们以每个点为中心,选取其11*11的领域,计算这121个点保存的bounding box与中心点的IoU,然后保存成121维的向量用于描述该点的IoU特性。例如,以下图这个15*15的score map为例,对于(7,7)这个点来说,我们取其11*11的邻域,然后计算邻域中每个点所包含的bounding box和(7,7)的bounding box的IoU,比如领域中左上角第一个点不包含bounding box,则特征I(7,7,1)=0,第二个点包含了bounding box(图中有颜色的小方格代表包含bounding box,白色的则没有包含),则我们计算该点的bounding box和(7,7)的bounding box的IoU,并存入到I(7,7,2)中。以此类推,每个点都有121维的特征,则整个score map输出的特征为15*15*121.
以下部分内容来自于:http://blog.csdn.net/shuzfan/article/details/50371990
2.4 网络解析
我们再来看一下网络结构,注意2点:
IOU层的kernel size 为1,stride也为1。
Score map层的kernel size 为11×11,这是为了呼应IOU层;stride 为1 ,pad 为5,这是为了获得和输入同样尺寸的输出:
Layer 2将之前的2个输出拼接,之后所有的卷积都是1×1。最终的输出仍然是一个尺寸一致的score map。
2.5 输出及Loss
理想的输出是一个同输入尺寸完全一致的score map 图,在该图中,每一个目标只拥有一个score,相应地也只对应了一个bounding box。
因此训练的目标就是保留一个,抑制其它。如下图:
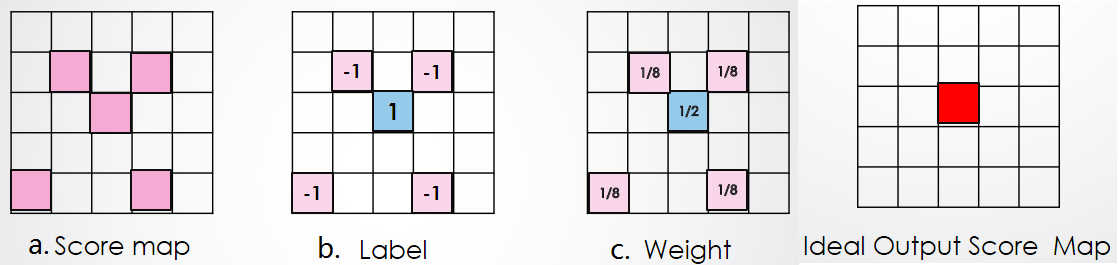
(1)上图a的score map 是我们的输入,由图易知,这里面一共有5个有效的score,则也对应着5个bounding box。
(2)假设5个bounding box都是同一个目标的检测结果。则我们的训练目的则是保留最好的一个,抑制其余4个。
为此,我们首先分配标签:5个bounding box 中满足与ground truth 的IOU大于0.5且得分最高的box作为正样本,其余均为负样本,如上图b所示。
(3)显然正负样本的数量严重不均衡,因此计算loss之前,我们要分配一下权重用于权衡这种失衡。权重的分配很简单,如图c所示,正样本的权重总和与负样本的权重总和相等。
(4)上右侧的图为理想的输出。综上,我们的Loss Function就可以很容易得出了(类似于pixel级别的分类):
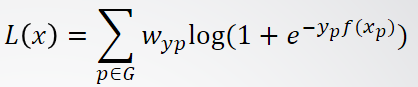
其中,p属于G,表示score map 中有值的点。
Discuss
这篇文章最大的selling point在于它解决了NMS设置阈值难的问题。传统的NMS是hard-pruning decision,而在NMS convnet中,作者通过学习的方法来获得最佳的输出。如果真能做到的话,以后NMS都替换成NMS convnet,那么各种检测问题的精度又可以上一个台阶了。
文章地址:
A CONVNET FOR NON-MAXIMUM SUPPRESSION (2016 ICLR Under Review)
A brief introduction of NMS for object detection
NMS,即Non-maximum suppression,非极大值抑制,在object dection中应用非常广泛,简单地说,他就是对一些region proposals(物体的候选框)进行筛选,得到最佳的物体检测位置。
如上图所示,在做人脸检测时我们可能会得到多个人脸的候选框,但是其实这些框完全可以进行“合并”,得到一个人脸的框框。这个“合并”的策略就是NMS。NMS主要有两个指标来进行合并:
1.score:对于每一个proposal,分类器会给出一个score来表示当前候选框的置信度,尽量保留置信度较高的候选框
2.IoU(Intersection-over Union):重叠面积,位置邻近的候选框重叠面积大于一定阈值的话则进行合并
所以NMS的实现是:
1. NMS计算出每一个bounding box的面积,然后根据score进行排序。
2. 计算其余bounding box与当前最大score的box的IoU,去除IoU大于设定的阈值的bounding box。
3. 重复上面的过程,直至候选bounding box为空。
需要注意的是:NMS一次处理一个类别,如果有N个类别,NMS就需要执行N次。
NMS的缺点:
NMS的合并策略是一种较贪婪的方法,在平衡精度和召回率时会有问题。例如出现两个人脸靠得很近的情况,我们首先得到了许多红色的region proposal,然后用NMS来筛选候选框。
假设我们能设置一个合适的阈值,那么两个人脸可以被两个框分别框住。
如果我们将IoU阈值设定得高一些,也就是说合并相对困难,则会出现下图(a)的筛选结果,说明非极大值抑制得不够充分;那么我们将IoU阈值设定得低一些,合并相对容易,就会得到下图(b)的结果,也就是说多个ture positive被merge到了一起。
Convnet for NMS
2.1 Overview
传统的NMS在判决融合的时候,只利用到了2个信息:Score 和 IOU ,即每个框的得分和框与框之间的重叠比例。
文章用神经网络去实现NMS,所利用的同样也是这2个信息。如下图的整个流程图:
2.2 Score map的生成
假设我们的图片是W*H的,在这里我们以16*16大小的图片为例,我们对他生成w*h大小的score map,其中w=W/4,h=H/4,也就是说score map上的一个点对应原图中4*4的区域。然后假设我们得到了一个物体的bounding box,其置信度为0.8,我们将其中心点的位置记录在score map中,因为他的中心点落在第(3,2)个score map区域中,因此该区域置信度为0.8;接着我们又得到一个新的bounding box,其置信度为0.9,且中心点也落在了(3,2)的区域,根据NMS保留大置信度的特点,我们对该区域的置信度进行更新,也就是说(3,2)这个区域的置信度变成了0.9。注意在更新置信度的时候,我们也保留了原始bounding box的原始位置信息,以便最终的索引。
到此,我们已经得到了w×h×1的score map.
文章提到,卷积神经网络的线性操作和relu无法模仿NMS中对score进行排序的操作, 因此,文章先用传统的NMS处理一遍bounding boxes, 然后再生成一张同样大小的score map,记作S(T),T为NMS的阈值。
最终,我们得到了w×h×2的score map. 记作S(1,T)
2.3 IoU layer
NMS的另一个重要概念是通过重叠面积来筛选候选框。这一步在convnet中是这么做的:对于score map上的每个点,我们已经记录了其是否包含bounding box以及该box的置信度。那么我们以每个点为中心,选取其11*11的领域,计算这121个点保存的bounding box与中心点的IoU,然后保存成121维的向量用于描述该点的IoU特性。例如,以下图这个15*15的score map为例,对于(7,7)这个点来说,我们取其11*11的邻域,然后计算邻域中每个点所包含的bounding box和(7,7)的bounding box的IoU,比如领域中左上角第一个点不包含bounding box,则特征I(7,7,1)=0,第二个点包含了bounding box(图中有颜色的小方格代表包含bounding box,白色的则没有包含),则我们计算该点的bounding box和(7,7)的bounding box的IoU,并存入到I(7,7,2)中。以此类推,每个点都有121维的特征,则整个score map输出的特征为15*15*121.
以下部分内容来自于:http://blog.csdn.net/shuzfan/article/details/50371990
2.4 网络解析
我们再来看一下网络结构,注意2点:
IOU层的kernel size 为1,stride也为1。
Score map层的kernel size 为11×11,这是为了呼应IOU层;stride 为1 ,pad 为5,这是为了获得和输入同样尺寸的输出:
Layer 2将之前的2个输出拼接,之后所有的卷积都是1×1。最终的输出仍然是一个尺寸一致的score map。
2.5 输出及Loss
理想的输出是一个同输入尺寸完全一致的score map 图,在该图中,每一个目标只拥有一个score,相应地也只对应了一个bounding box。
因此训练的目标就是保留一个,抑制其它。如下图:
(1)上图a的score map 是我们的输入,由图易知,这里面一共有5个有效的score,则也对应着5个bounding box。
(2)假设5个bounding box都是同一个目标的检测结果。则我们的训练目的则是保留最好的一个,抑制其余4个。
为此,我们首先分配标签:5个bounding box 中满足与ground truth 的IOU大于0.5且得分最高的box作为正样本,其余均为负样本,如上图b所示。
(3)显然正负样本的数量严重不均衡,因此计算loss之前,我们要分配一下权重用于权衡这种失衡。权重的分配很简单,如图c所示,正样本的权重总和与负样本的权重总和相等。
(4)上右侧的图为理想的输出。综上,我们的Loss Function就可以很容易得出了(类似于pixel级别的分类):
其中,p属于G,表示score map 中有值的点。
Discuss
这篇文章最大的selling point在于它解决了NMS设置阈值难的问题。传统的NMS是hard-pruning decision,而在NMS convnet中,作者通过学习的方法来获得最佳的输出。如果真能做到的话,以后NMS都替换成NMS convnet,那么各种检测问题的精度又可以上一个台阶了。