第二章 C++数据结构
本章主要介绍了C++基本的数据结构,包括向量、列表、栈与队列、二叉树和图。主要的总结均来自于邓俊辉老师的《数据结构C++语言版》,在每一小节的背后,给出了一些在网上总结的面试题,以加强我们对C++数据结构的理解。并且每一小节均给出了典型的C++程序代码,理解这些代码是读懂文章的关键。
2.1 向量
2.1.1 向量的概念和接口
一、概念
向量vector就是线性数组的一种抽象与泛化,它也是具有线性次序的一组元素构成的集合 ,其中的元素分别由秩相互区分。若元素e的前驱元素共有r个,则e的秩就是r。
二、抽象数据类型(ADT)接口
insert(r,e)//e作为秩为r的元素插入,原后继元素依次后移
put(r,e)//用e替换秩为r的元素的数值
get(r)//获取秩为r的元素
remove(r)//删除秩为r的元素,返回所删除的元素的秩
……
向量接口的具体实现见:https://blog.csdn.net/qq_23912545/article/details/70216948。
2.1.2 构造与析构
由Vector类模板可知,向量结构在内部维护一个元素类型为T的私有数组_elem[],其容量由私有变量_capacity指示,向量当前的实际规模由_size指示。向量中秩为r的元素,对应于内部数组中的_elem[r],其物理地址为_elem+r。
与所有对象一样,向量在使用之前需要借助构造函数做初始化。构造方法有2种,一是默认构造方法:根据指定的初始容量创建内部私有数组_elem[],若未指定容量,则使用默认值DEFAULT_CAPACITY。二是基于复制的构造方法,以某个已有的向量为蓝本,进行局部或整体的克隆。
例 2.1.1基于复制的构造的copyFrom()方法
template <typename T>//元素类型
void vector<T>::copyFrom(T const* A, Rank lo, Rank hi)
//定义数组区间A[lo,hi]为蓝本复制向量
{
_elem =new T[_capacity=2*(hi-lo)]; _size=0;//分配空间,规模清0
while(lo<hi)
_elem[_size++]=A[lo++];//复制至_elem[0,hi]
}析构方法:~Vector():只释放用于存放元素的内部数组_elem[],将其占用的空间交还给操作系统。_capacity和_size之类的内部变量无需做任何处理。
2.1.3 动态空间管理
内部数组所占物理空间的容量,若在向量的生命周期内不允许调整,则称作静态空间管理策略。但是容量固定的话,在更多新元素到来时,会产生上溢。定义装填因子为向量实际规模与其内部数组容量的比值,即_size/_capacity。该指标可以衡量空间利用率。为使装填因子不超过1也不接近0,需要改用动态空间管理策略。动态空间管理策略有2种方法:
动态扩容算法 |
动态缩容算法 |
当空间耗尽时,就动态地扩大内部数组的容量,但不是在原有物理空间的基础上追加空间,而是另外申请一个容量更大的数组B,并将原数组A中成员集体搬迁进来。当然,原数组所占空间也需要及时释放。expand()扩容算法具体代码实现如下: |
当向量的实际规模远远小于内部数组的容量时,装填因子接近于0.当装填因子低于某一阈值时,我们称数组发生了下溢。此时应当缩减内部数组容量。shrink()动态缩容算法如下: |
template <typename T> void Vector<T>::expand() //向量空间不足时扩容 { if (_size<_capacity) return; //尚未满员时不扩容 if (_capacity <DEFAULT_CAPACITY ) _capacity=DEFAULT_CAPACITY; //容量不能低于最小容量 T* oldElem=_elem; //将原来的数据保存 _elem=new T[_capacity<<=1]; //容量加倍 for (int i=1;i<_size;i++) { _elem[i]=oldElem[i];//复制原向量内容 } delete [] oldElem; //释放原空间,delete } |
template <typename T> void Vector<T>::shrink()//装填因子过小时压缩向量所占空间 { if (_capacity<DEFAULT_CAPACITY<<1) //不至收缩到DEFAULT_CAPACITY以下 if (_size<<2> _capacity) return; //以25%为装填因子的阈值 T* oldElem=_elem; _elem=new T[_capacity>>=1];//容量减半 for (int i=0;i<_size;i++) { _elem[i]=oleElem[i]; } delete [] oldElem; } |
在调用insert()接口插入新元素之前,都要先调用该算法检查可用容量。 |
2.1.4 常规向量
一、直接引用元素
可以通过重载运算符“[ ]”,可以通过下标直接访问元素。
Eg:
template<typename T>
T&Vector<T>::operator[ ](Rank r) const //重载运算符
{return_elem[r];}二、置乱器
向量整体置乱算法permuted()用于随机向量的生成,其不仅可以枚举出同一向量的所有可能排列,而且能够保证生成的各种排列概率均等。
三、无序查找
Vector::find(e)接口的功能是查找与对象e相等的元素,即向量元素可通过相互对比判断是否相等。仅支持对比但未必支持比较的向量称作无序向量。从最后一个元素开始向前,逐一选取各个元素与目标元素e比较,直至发现与之相等者(查找成功),或者直至检查完所有元素仍未找到相等者(查找失败)。这种逐个比较的查找方式称为顺序查找。
例 2.1.2向量区间的顺序查找算法(无序向量元素查找接口find())
template <typename T>
//无序向量的顺序查找,返回最后一个元素e的位置,失败则返回lo-1
Rank Vector<T>::find(T const &e, Rank lo, Rank hi) const
{
//assert: 0<=lo<hi<=_size
while((lo<hi--)&&(e!=elem[hi])) //从后向前,顺序查找
return hi;//若hi<lo,则意味着失败
}四、插入
根据ADT定义,插入操作符insert(r,e)负责将任意给定的元素e插到指定的秩为r的单元。向量元素插入接口的insert()代码如下:
template <typename T> //将e作为秩为r的元素插入
Rank Vector<T>::insert(Rank r, T const& e)
{
//assert:0<=r<=_size
expand(); //若有必要,扩容
for (int i=_size;i>r;i--)
_elem[i]=_elem[i-1]; //自后向前,后继元素以此后移一个单元
_elem[r]=r;//置入新元素
_size++; //更新容量
return r;//返回秩
}五、删除
删除操作经过重载有2个接口,remove(lo,hi)表示删除区间[lo,hi)内的元素,remove(r)删除秩为r的单个元素。应将单元素删除视为区间删除的特例。
向量区间删除接口remove(lo,hi) |
向量单元素删除接口remove(r) |
|
利用remove(lo,hi)通用接口,通过重载即可实现另一同名接口remove(r) |
六、唯一化
向量的唯一化处理指的是删除其中重复的元素,即deduplicate()接口的功能。无序向量的唯一化算法如下template <typename T>
int Vector<T>::deduplicate()
{
int oldSize=_size;//记录原规模
Rank i=1;//从elem[1]开始
while(i<_size) //自前向后逐一考虑各元素_elem[i]
(find(_elem[i],0,i)<0)? i++:remove(i) ;
//在前缀中寻找与_elem[i]的相同者,但至多只找一个。若没有找到则继续考察后继(令i加一),否则删除相同者
return oldSize-_size;//返回被删除元素个数
}2.1.5 有序向量
若向量S[0,n]中的所有元素不仅按线性次序存放,而且其数值大小也按此次序单调分布,则称作有序向量。有序向量通常约定其中的元素自前向后构成一个非降序列,即对任意0≤i<j<n,都有S[i]<S[j]。一、有序性甄别
作为无序向量的特例,有序向量自然可以沿用无序向量的查找算法。然而得益于元素之间的有序性,有序向量的查找和唯一化等操作都可更快速地完成。因此在实施此类操作前,有必要先判断当前序列是否有序,以便确定是否采用更高效的接口。有向序列甄别算法如下:
template <typename T>
int Vector<T>::disordered() const
//返回向量中逆序相邻对的总数
{
int n=0; //计数器
for (int i=1;i<_size;i++) //逐一检查_size-1对相邻元素
if (_elem[i-1]>_elem[i]) n++; //逆序则计数
return n; //有序时返回n=0
}二、有序向量的唯一化
相对于无序向量,有序向量中清除重复元素的操作更为重要。处于效率的考虑,在清除无序向量中重复元素的时候,一般做法是先将其转化为有序向量。唯一化的实现有低效和高效2种形式。
低效版 (有序向量uniquify()接口的平凡实现) |
高效版 (有序向量uniquify()接口的高效实现) |
|
|
该算法效率与无序向量的唯一化算法是一样的,需要改进。 |
在有序向量中,每一组重复元素都必然紧邻地集中分布,因此可以以区间为单位成批的删除,并将其后继元素统一的大跨度前移。 |
三、有序向量的查找
有序向量S中的元素不再随机分布,秩r是S[r]在S中按大小的相对次位。一般的,若小于、等于S[r]的元素各有i,k个,则该元素及其相同元素应集中分布于S[i,i+k]。为区别于无序向量查找接口find(),有序向量的查找接口统一命名为search()。该接口的具体实现算法如下:
template <typename T>//在有序向量的区间[lo,hi]内,确定不大于e的最后一个节点的秩
Rank Vector<T>::search(T const& e, Rank lo, Rank hi) const
//assert:0<=lo<hi<=_size
{
return (rand()%2)? binSearch(_elem,e,lo,hi):fibSearch(_elem,e,lo,hi);
//各有一半的概率采用二分查找或Fibonacci查找
}二分查找 |
Fibonacci查找 |
使用“减而治之”的策略来实现有序向量的查找。以任意元素S[mi]为界,可将区间分为3部分,根据此时的有序性,便有: S[lo,mi]≤S[mi]≤S[mi,hi]将目标元素e与x作比较,则有三种可能的情况,直到e=x才终止查找。 |
事实上,减治策略本身并不要求子向量切割点mi必须居中,改进二分法的思路,不妨按黄金分割比来确定mi。简单起见,假设向量长度为n=fib(k)-1。 |
/ |
暂不总结 |
有多个命中元素时,不能保证返回秩最大者;查找失败时,不能指示失败的位置。 |
2.1.6 排序与下界
有序向量的诸如查找等操作,要率要远高于一般向量,因此在实际解决问题时普遍采用的做法是:将向量转化为有序向量,随后调用有序向量支持的各种高效算法。根据其处理的数据规模与存储的特点不同,可分为内部排序算法和外部排序算法;根据输入形式的不同,排序算法也可分为离线算法和在线算法。
一般地,任一问题在最坏情况下的最低计算成本称为该问题的复杂度下界。一旦某一算法的性能达到这一下界,即意味着它在最坏的情况下是最优的。
2.1.7 排序器
由于排序算法十分重要,排序操作也应当列入向量基本接口的范围,这类接口也是将无序向量转化为有序向量的基本方法和主要途径。
例 2.1.3向量排序器接口
template <typename T>
void Vector<T>::sort(Rank lo,Rank hi)
//在向量区间[lo,hi]中排序
{
switch(rand()%5) //随机选取5种排序算法中的一种
case 1: bubbleSort(lo,hi); break;//冒泡排序
case 2: selectionSort(lo,hi);break;//选择排序
case 3: mergeSort(lo,hi);break;//归并排序
case 4: heapsort(lo,hi);break;//堆排序
default: quicksort(lo,hi);break;//快速排序
}一、冒泡排序
冒泡排序的具体算法已经在第一章节中讲过了,现在只需将其集成至向量ADT中。
template <typename T>
void Vector<T>::bubbleSort(Rank lo,Rank hi) //向量的冒泡排序
{
while(!bubble(lo,hi--));
//逐趟作扫描交换,直至全序。由于每次都把最大值放在最后后,因此在每轮之后都需要hi--
}
template <typename T>
bool Vector<T>::bubble(Rank lo,Rank hi)
{
bool sorted=ture;//整体有序标志
while(++lo<hi) //自左向右,逐一检查各对相邻元素
if (_elem[lo-1]>_elem[lo]) //若逆序
{
sorted=false;//意味着尚未整体有序
swap(_elem[lo-1],_elem[lo]); //通过交换使局部有序
}
return sorted;//返回有序标志
}二、归并排序
与冒泡排序通过反复调研用单趟扫描交换类似,归并排序也可以认为是通过反复调用所谓二路归并算法实现的。所谓二路归并,就是将两个有序序列合并成为一个有序序列。二路归并属于迭代算法,,在每步迭代中,只需比较2个待归并向量的首元素,将小者取出并追加到输出向量的末尾,该元素在原向量中的后继则成为新的首元素。如此往复,直到某一向量为空。最后将另一非空向量整体接至输出向量的尾端。具体实现如图2.1。
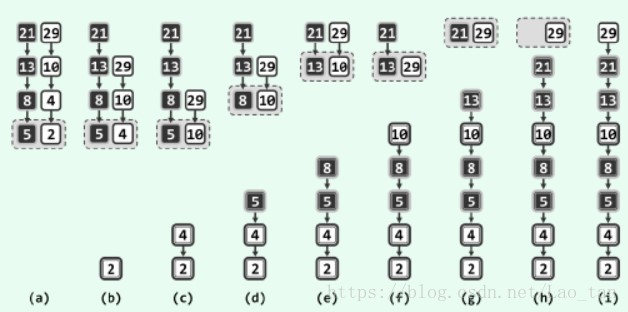
图 2.1 二路归并排序
归并排序的主体结构属于典型的分治策略,可递归地描述和实现:
template <typename T> //向量归并排序
void Vector<T>::mergeSort(Rank lo, Rank hi)
{
if (hi-lo<2) return; //单元素区间自然有序
int mi=(lo+hi)/2;
mergeSort(lo,mi);mergeSort(mi,hi);merge(lo,mi,hi);//分别对前后两段排序,然后归并
}通过对递归的不断深入,不断地均匀划分子向量,直到其规模等于1,从而抵达递归基。递归返回时,通过反复调用二路归并算法,相邻且等长的子向量不断地成对合并为规模更大的有序向量,直至得到整个有序向量。