pandas是什么?
pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。
优点
-
Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。
-
pandas提供了大量能使我们快速便捷地处理数据的函数和方法。
-
是使Python成为强大而高效的数据分析环境的重要因素之一。
查看pandas版本信息
print(pd.__version__)

pandas中常见的数据类型
常见的数据类型:
- 一维: Series
- 二维: DataFrame
- 三维: Panel ....
- 四维: Panel4D .....
- N维: PanelND ....
创建Series数据类型
1). 通过列表创建Series对象
import pandas as pd
import numpy as np
import string
array = ["Me", "You", "He"]
# 如果不指定索引, 默认从0开始;
s1=pd.Series(data=array)
print('列表创建Series对象,不指定索引\n',s1)
#指定索引,index设置索引值
ss1=pd.Series(data=array,index=['A','B','C'])
print('列表创建Series对象,指定索引\n',ss1)

通过numpy的对象Ndarray创建Series;
import pandas as pd
import numpy as np
import string
# 随机创建一个ndarray对象;
#元素为小数类型,即float类型
data=np.random.randn(5)
s2=pd.Series(data=data)
print('numpy的对象创建Series\n',s2)
# 修改元素的数据类型;
ss2=s2.astype(np.int)
print('修改元素的数据类型为int型\n',ss2)

3). 通过字典创建Series对象;
import pandas as pd
import numpy as np
import string
dict = {string.ascii_lowercase[i]:i for i in range(5)}
s3 = pd.Series(dict)
print('字典创建Series对象\n',s3)

Series基本操作
1). 修改Series索引
import pandas as pd
import numpy as np
import string
array = ["Me", "You", "He"]
s1=pd.Series(data=array)
print('原数据\n',s1)
#可以索引的范围
print('索引的范围',s1.index)
#修改索引值
s1.index = ['A', 'B', 'C']
print('修改后的数据\n',s1)

2). Series纵向拼接;
import pandas as pd
import numpy as np
import string
array = ["Me", "You", "He"]
s1=pd.Series(data=array)
print('原数据\n',s1)
#再生成一个Series对象
s2=pd.Series(data=array)
#将s2追加到s1中
s3=s1.append(s2)
print('追加后的数据\n',s3)

3). 删除指定索引对应的元素;
import pandas as pd
import numpy as np
import string
array = ["Me", "You", "He"]
s1=pd.Series(data=array)
print('原数据\n',s1)
# 删除索引为1对应的值;
s1 = s1.drop(1)
print('删除后的数据\n',s1)

4). 根据指定的索引查找元素
import pandas as pd
import numpy as np
import string
array = ["Me", "You", "He"]
s1=pd.Series(data=array,index = ['A', 'B', 'C'])
print('原数据\n',s1)
print('指定索引为B的对应元素值',s1['B'])
#指定索引为B的元素值为缺失值
s1['B']=np.nan
print('指定索引为B的元素值为缺失值\n',s1)

5). 切片操作
import pandas as pd
import numpy as np
import string
array = ["Me", "You", "He"]
s1=pd.Series(data=array,index = ['A', 'B', 'C'])
print('原数据\n',s1)
#显示前两个元素
print('前两个元素\n',s1[:2])
#显示将元素反转
print('元素反转\n',s1[::-1])
# 显示最后两个元素
print('最后两个元素\n',s1[-2:])

Series 运算
import pandas as pd
import numpy as np
import string
#创建一维数组,指定索引值
s1=pd.Series(np.arange(2),index=list(string.ascii_lowercase[:2]))
s2=pd.Series(np.arange(1,3),index=list(string.ascii_lowercase[1:3]))
print('原数据1\n',s1)
print('原数据2\n',s2)
# ****按照对应的索引进行计算, 如果索引不同,则填充为Nan;****
# 加法
print('加法\n',s1 + s2)#====s1.add(s2)
# 减法
print('减法\n',s1 - s2)#====s1.sub(s2)
# 乘法
print('乘法\n',s1 * s2)#====s1.mul(s2)
# 除法
print('除法\n',s1 / s2)#====s1.div(s2)
# 求中位数
print('中位数 ',s1.median())
# 求和
print('和 ',s1.sum())
# 最大值
print('最大值 ',s1.max())
# 最小值
print('最小值 ',s1.min())

特殊的where方法
import pandas as pd
import numpy as np
import string
# series中的where方法运行结果和numpy中完全不同;
s1 = pd.Series(np.arange(3), index=list(string.ascii_lowercase[:3]))
print('原数据\n',s1)
#如果s1中的元素值大于1,则保留,否则变为缺失值
print('如果s1中的元素值大于1,则保留,否则变为缺失值\n',s1.where(s1 >1 ))
# 对象中不大于1的元素赋值为10;
print('对象中不大于1的元素赋值为10\n',s1.where(s1 > 1, 10))
# 对象中大于1的元素赋值为100
print('对象中大于1的元素赋值为100\n',s1.mask(s1 > 1, 100))

创建DataFrame数据类型
import pandas as pd
import numpy as np
import string
# ****创建DataFrame数据类型****(二维数组)
# 方法1: 通过列表创建
li = [
[1, 2, 3, 4],
[2, 3, 4, 5]
]
# DataFRame对象里面包含两个索引, 行索引(0轴, axis=0), 列索引(1轴, axis=1)
#index:设置行索引;columns:设置列索引
d1 = pd.DataFrame(data=li, index=['A', 'B'], columns=['views', 'loves', 'comments', 'tranfers'])
print('列表创建DataFRame对象\n',d1)
# 方法2: 通过numpy对象创建
narr = np.arange(8).reshape(2, 4)
d2 = pd.DataFrame(data=narr, index=['A', 'B'], columns=['views', 'loves', 'comments', 'tranfers'])
print('numpy对象创建DataFRame对象\n',d2)
# 方法三: 通过字典的方式创建;
dict = {
'views': [1, 2 ],
'loves': [2, 3 ],
'comments': [3, 4 ],
'tranfers':[4,5]
}
d3 = pd.DataFrame(data=dict, index=['A', "B"])
print('字典的方式创建DataFRame对象\n',d3)

日期的操作:生成数据的索引
# 日期操作的特例:
# 行索引
#periods分为多少组
dates = pd.date_range(start='today', periods=6)
# 数据
data_arr = np.random.randn(6, 4)
# 列索引
columns = ['A', 'B', 'C', 'D']
d4 = pd.DataFrame(data_arr, index=dates, columns=columns)
print(d4)
# 建立一个以2019年每一天作为索引, 值为随机数;
# freq:取值频率
index_dates=pd.date_range(start='1/1/2018', end='1/1/2019',freq='D')
# 以索引值的长度取值
data=np.random.randn(len(index_dates))
s=pd.Series(data=data,index=index_dates)
print('以2019年每一天作为索引, 值为随机数\n',s)

DataFrame的基本操作
1). 查看基础属性
import pandas as pd
import numpy as np
import string
narr = np.arange(8).reshape(2, 4)
d2 = pd.DataFrame(data=narr, index=['A', 'B'], columns=['views', 'loves', 'comments', 'tranfers'])
print('原数据\n',d2)
# 获取行数和列数;
print('行数和列数',d2.shape)
# 列数据类型
print('列数据类型\n',d2.dtypes)
# 获取数据的维度
print('数据的维度',d2.ndim)
# 行索引
print('行索引',d2.index)
# 列索引
print('列索引',d2.columns)
# 对象的值, 二维ndarray数组
print('对象的值, 二维ndarray数组\n',d2.values, type(d2.values))

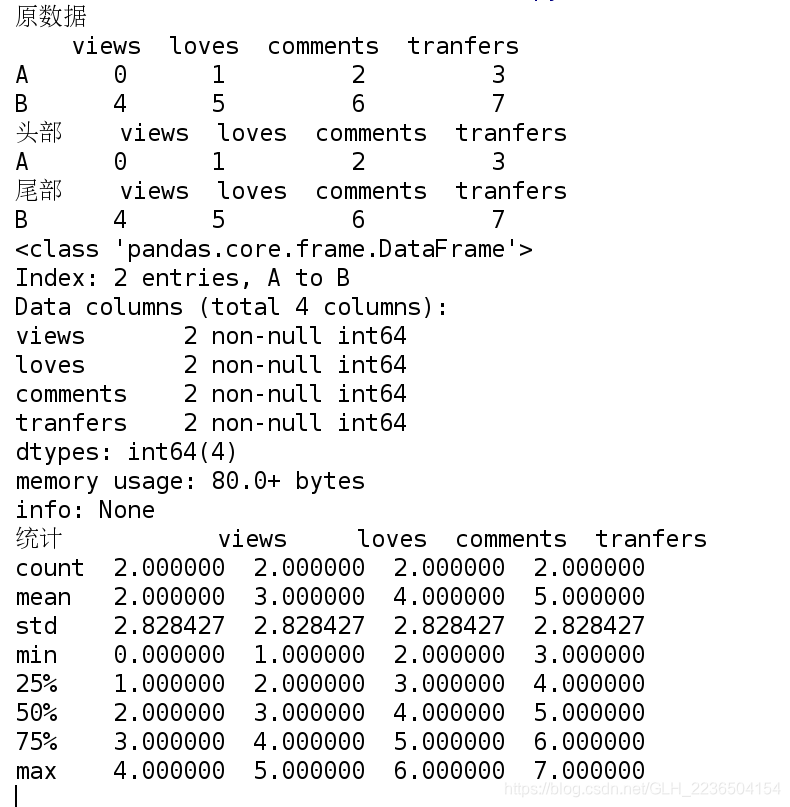
2). 数据整体状况的查询
import pandas as pd
import numpy as np
import string
narr = np.arange(8).reshape(2, 4)
d2 = pd.DataFrame(data=narr, index=['A', 'B'], columns=['views', 'loves', 'comments', 'tranfers'])
print('原数据\n',d2)
# 显示头部的几行, 默认5行
print('头部',d2.head(1))
# 显示尾部的尾行, 默认5行
print('尾部',d2.tail(1))
# 相关信息的预览: 行数, 列数, 列类型, 内存占用
print("info:", d2.info())
# 快速综合用计结果: 计数, 均值, 标准差, 最小值, 1/4位数, 中位数, 3/4位数, 最大值;
print("统计",d2.describe())
DataFrame 数据的排序,转置和切片
import pandas as pd
import numpy as np
import string
narr = np.arange(8).reshape(2, 4)
d2 = pd.DataFrame(data=narr, index=['A', 'B'], columns=['views', 'loves', 'comments', 'tranfers'])
print('原数据\n',d2)
# 1). 转置操作
print('转置\n',d2.T)
# 2). 按列进行排序
# 按照指定列进行排序, 默认是升序, 如果需要降序显示,设置ascending=False;
print('按列views进行降序\n',d2.sort_values(by="views", ascending=False))
# 3).切片及查询
# 可以实现切片, 但是不能索引;
# 第一行的所有列
print('切片\n',d2[:1])
# 通过标签查询, 获取单列信息
print('1:\n', d2['views']) #==== print('2:\n', d2.views)
# 通过标签查询多列信息
print(d2[['views', 'comments']])

查询以及更改pandas的值
import pandas as pd
import numpy as np
import string
narr = np.arange(8).reshape(2, 4)
d2 = pd.DataFrame(data=narr, index=['A', 'B'], columns=['views', 'loves', 'comments', 'tranfers'])
print('原数据\n',d2)
# 1). 通过类似索引的方式查询;
# - iloc(通过位置进行行数据的获取),
# - loc(通过标签(就是行索引)索引行数据)
#获取索引值‘A’的行数据
print('索引值‘A’的行数据\n',d2.loc['A'])
#获取那一行的行数据
print('最后一行的行数据\n',d2.iloc[-1:])
# 7). 更改pandas的值;
#将索引值为A的行数据都改为缺失值
d2.loc['A'] = np.nan
print('更改pandas的值\n',d2)

pandas从文件中读取数据
1.csv文件
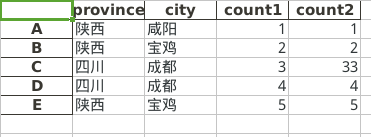
import pandas as pd
import numpy as np
import string
# 1). csv文件的写入
df = pd.DataFrame(
{'province': ['陕西', '陕西', '四川', '四川', '陕西'],
'city': ['咸阳', '宝鸡', '成都', '成都', '宝鸡'],
'count1': [1, 2, 3, 4, 5],
'count2': [1, 2, 33, 4, 5]
} ,index=['A','B','C','D','E']
)
#csv文件保存
df.to_csv('doc/csvfile.csv')
# 2). csv文件的读取
df2 = pd.read_csv('doc/csvfile.csv')
print('csv文件\n',df2)

excel文件
import pandas as pd
import numpy as np
import string
df = pd.DataFrame(
{'province': ['陕西', '陕西', '四川', '四川', '陕西'],
'city': ['咸阳', '宝鸡', '成都', '成都', '宝鸡'],
'count1': [1, 2, 3, 4, 5],
'count2': [1, 2, 33, 4, 5]
} ,index=['A','B','C','D','E']
)
# 1). excel文件的写入
df.to_excel("/tmp/excelFile.xlsx", sheet_name="省份统计")
groupby功能
介绍
pandas提供了一个灵活高效的groupby功能,
1). 它使你能以一种自然的方式对数据集进行切片、切块、摘要等操作。
2). 根据一个或多个键(可以是函数、数组或DataFrame列>名)拆分pandas对象。
3). 计算分组摘要统计,如计数、平均值、标准差,或用户自定义函数。
基本功能
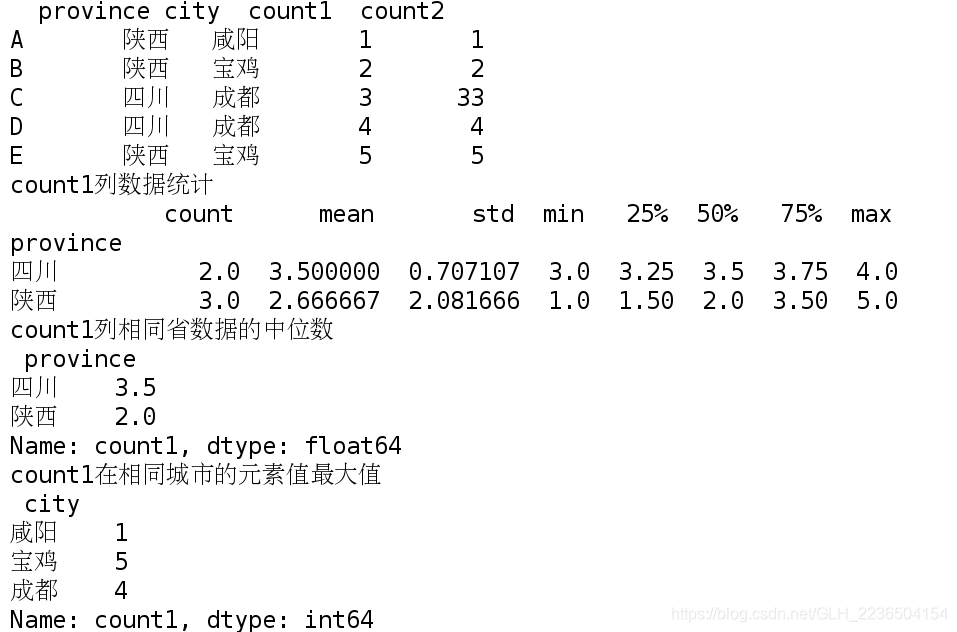
import pandas as pd
import numpy as np
import string
df = pd.DataFrame(
{'province': ['陕西', '陕西', '四川', '四川', '陕西'],
'city': ['咸阳', '宝鸡', '成都', '成都', '宝鸡'],
'count1': [1, 2, 3, 4, 5],
'count2': [1, 2, 33, 4, 5]
} ,index=['A','B','C','D','E']
)
print(df)
# 根据某一列的key值进行统计分析;
#根据province分组(相同province放在一起)进行统计,主要计算的是count1的数据
grouped=df['count1'].groupby(df['province'])
print('count1列数据统计\n',grouped.describe())
print('count1列相同省数据的中位数\n',grouped.median())
# 根据城市统计分析cpunt1的信息;
grouped = df['count1'].groupby(df['city'])
# 计算count1在城市列信息统计最大值
print('count1在相同城市的元素值最大值\n',grouped.max())
# 指定多个key值进行分类聚合;
#count1在省份,城市下的统计,
grouped = df['count1'].groupby([df['province'], df['city']])
#count1的元素值的最大值,分别在城市和省份的分类下
print('城市和省份的分类下count1的元素值的最大值\n',grouped.max())
#分别在城市和省份的分类下,count1出现的次数
print('分别在城市和省份的分类下,count1出现的次数\n',grouped.count())

案例分析
文件描述: 每列数据分别代表如下: 订单编号, 订单数量, 商品名称, 商品详细选择项, 商品总价格
需求1:
1). 从文件中读取所有的数据;
2). 获取数据中所有的商品名称;
3). 跟据商品的价格进行排序, 降序,
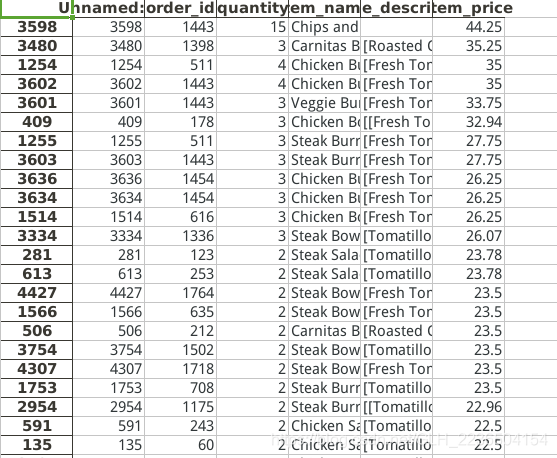
将价格最高的20件产品信息写入price_sorted.xlsx文件中;
import pandas as pd
import numpy as np
import string
# 1). 从文件中读取所有的数据;
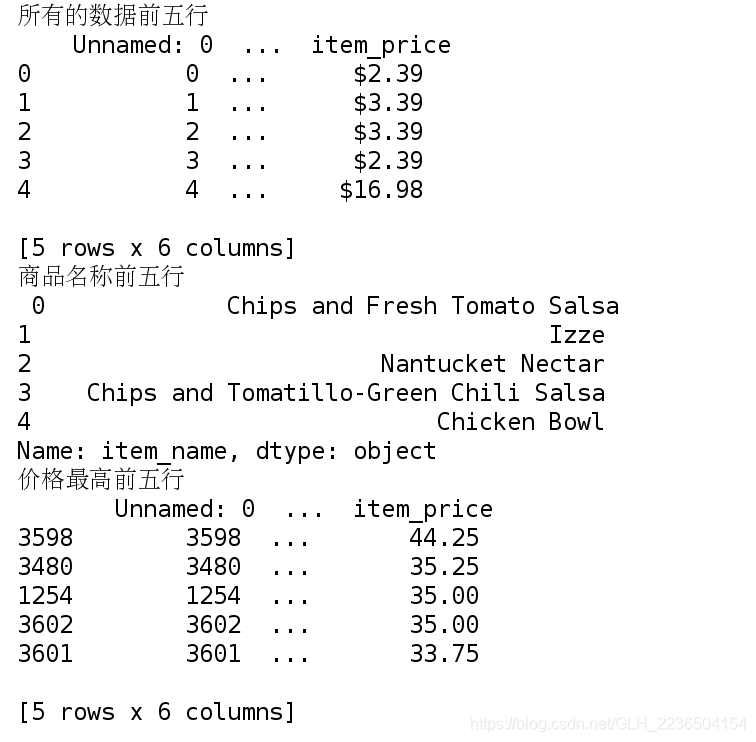
goodinfo=pd.read_csv('doc/chipo.csv')
#取前五行
print('所有的数据前五行\n',goodinfo[:5])
# 2). 获取数据中所有的商品名称
name=goodinfo.item_name
#取前五行
print('商品名称前五行\n',name[:5])
# 3). 跟据商品的价格进行排序, 降序,
# 将价格最高的20件产品信息写入mosthighPrice.xlsx文件中;
#因为item_price列是字符串,所以要去掉$符号,变为数字类型才能比较大小,所以得重新赋值
goodinfo.item_price=goodinfo.item_price.str.strip('$').astype(np.float)
#排序
highprice=goodinfo.sort_values('item_price',ascending=False)
print('价格最高前五行\n',highprice[:5])
#写入excel文件
highprice.to_excel('/tmp/price_sorted.xlsx')
需求2:
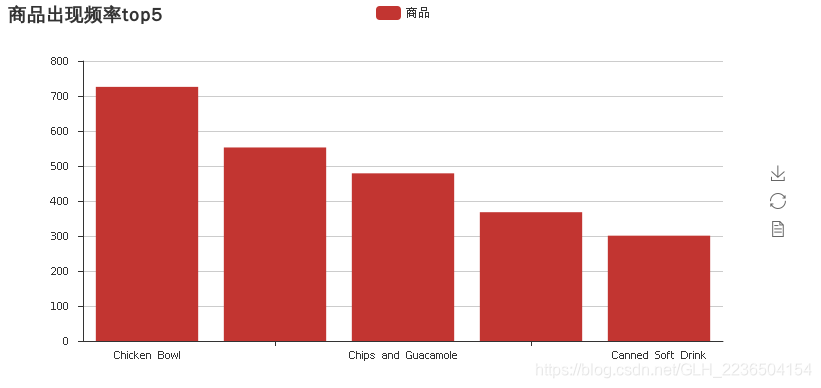
1). 统计列[item_name]中每种商品出现的频率,绘制柱状图
(购买次数最多的商品排名-绘制前5条记录)
# 1). 从文件中读取所有的数据;
goodinfo=pd.read_csv('doc/chipo.csv')
# 根据名称进行价格分组,
grouped=goodinfo.groupby('item_name')
# 计算在同一个名称下出现其他列的次数
count=grouped.count()
#以某一列出现的次数进行排序,即名字出现的次数排序,values值则为该列出现的次数
message=count.sort_values('item_price',ascending=False)['item_price']
print(message)
from pyecharts import Bar
bar=Bar('商品出现频率top5')
bar.add("商品",message.index[:5],message.values[:5])
bar.render()
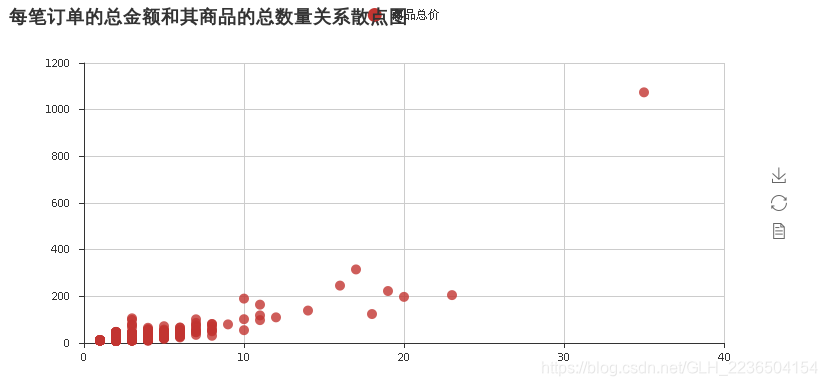
2). 根据列 [odrder_id] 分组,求出每个订单花费的总金额。
3). 根据每笔订单的总金额和其商品的总数量画出散点图。
import pandas as pd
import numpy as np
import string
# 1). 从文件中读取所有的数据;
goodinfo=pd.read_csv('doc/chipo.csv')
#因为item_price列是字符串,所以要去掉$符号,变为数字类型才能比较大小,所以得重新赋值
goodinfo.item_price=goodinfo.item_price.str.strip('$').astype(np.float)
#重新赋值商品总价,因为同一个订单的同一个商品可能买了不止一件,
# 所以赋值商品总价为这个订单内该商品一共花了多少钱 即单价与数额相乘
goodinfo.item_price=goodinfo.item_price * goodinfo.quantity
# 每个订单的每个商品花费的总金额=goodinfo.item_price
#每个订单花费的总金额
grouped1=goodinfo['item_price'].groupby(goodinfo['order_id'])
price=grouped1.sum()
# 每笔订单商品的总数量
grouped2=goodinfo['quantity'].groupby(goodinfo['order_id'])
count=grouped2.sum()
from pyecharts import Scatter
sca=Scatter('每笔订单的总金额和其商品的总数量关系散点图')
sca.add('商品总价',count.values,price.values)
sca.render()
字符串操作
import pandas as pd
import numpy as np
import string
series1= pd.Series(['A:1', 'B:2', 'c:3', np.nan, '$cat:3'])
print(series1)
# 将所有的字母转换为小写字母, 除了缺失值
print(series1.str.lower())
# 将所有的字母转换为大写字母, 除了缺失值
print(series1.str.upper())
# 分离
print(series1.str.split(":"))
# 去掉左右两端的某个字符
print(series1.str.strip('$'))

案例2
文件内容: 总消费金额, 小费金额, 性别, 是否抽烟, 日期, 时间, 星期
需求1:
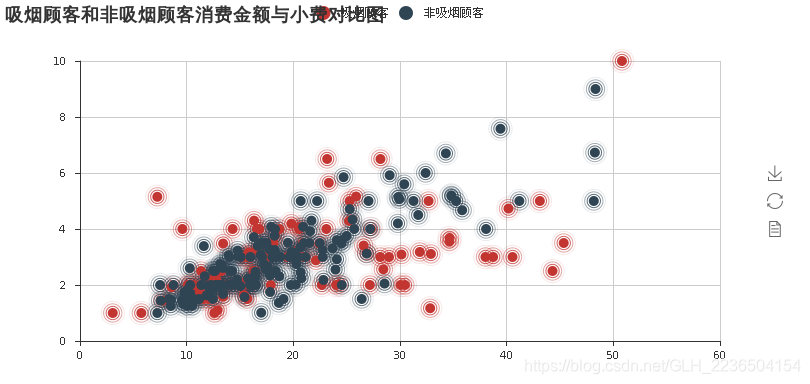
- 分别吸烟顾客与不吸烟顾客的消费金额与小费之间的散点图;
import pandas as pd
import numpy as np
import string
filename = 'doc/tips.csv'
data = pd.read_csv(filename)
#吸烟顾客分为一组
smoker=data[data.smoker=='Yes']
#非吸烟顾客分为一组
unsmoker=data[data.smoker=='No']
from pyecharts import EffectScatter
sca=EffectScatter('吸烟顾客和非吸烟顾客消费金额与小费对比图')
sca.add("吸烟顾客",smoker.total_bill.values,smoker.tip.values)
sca.add("非吸烟顾客",unsmoker.total_bill.values,unsmoker.tip.values)
sca.render()
需求2:
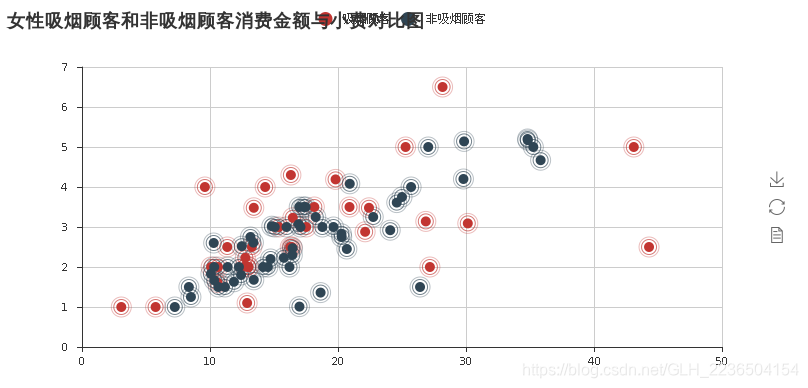
- 女性与男性中吸烟与不吸烟顾客的消费金额与小费之间的散点图关系;
import pandas as pd
import numpy as np
import string
filename = 'doc/tips.csv'
file= pd.read_csv(filename)
#女生为一组
file_f=file[file.sex=='Female']
#男生为一组
file_m=file[file.sex=='Male']
#女生里抽烟的为一组
file_f_somker=file_f[file_f.smoker=='Yes']
#女生里不抽烟的为一组
file_f_nosomker=file_f[file_f.smoker=='No']
#男生里抽烟的为一组
file_m_somker=file_m[file_m.smoker=='Yes']
#男生里不抽烟的为一组
file_m_nosomker=file_m[file_m.smoker=='No']
from pyecharts import EffectScatter
sca_f=EffectScatter('女性吸烟顾客和非吸烟顾客消费金额与小费对比图')
sca_f.add("吸烟顾客",file_f_somker.total_bill.values,file_f_somker.tip.values)
sca_f.add("非吸烟顾客",file_f_nosomker.total_bill.values,file_f_nosomker.tip.values)
sca_m=EffectScatter('男性吸烟顾客和非吸烟顾客消费金额与小费对比图')
sca_m.add("吸烟顾客",file_m_somker.total_bill.values,file_m_somker.tip.values)
sca_m.add("非吸烟顾客",file_m_nosomker.total_bill.values,file_m_nosomker.tip.values)
#指定生成的html文件路径以及名称
sca_f.render(path='Famale.html')
sca_m.render(path='Male.html')

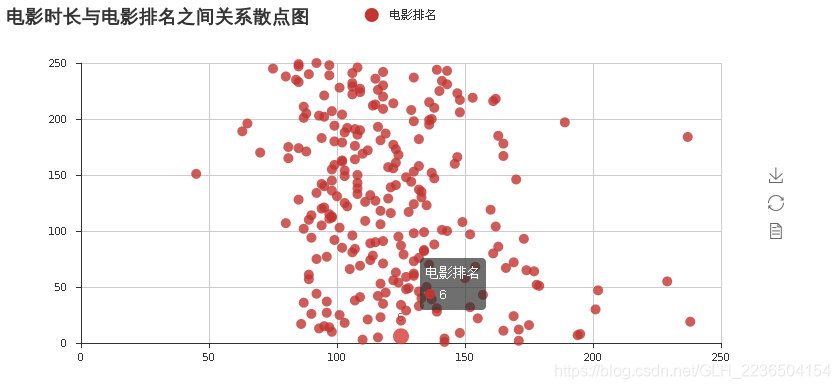
绘制电影时长和电影排名之间的关系
import pandas as pd
import numpy as np
import string
filename = 'doc/special_top250.csv'
data = pd.read_csv(filename)
# 获取电影时长
x_series = data.movie_duration
# 获取电影排名
y_series = data.num
from pyecharts import Scatter
scatter = Scatter("电影时长与电影排名之间关系散点图")
scatter.add("电影排名", x_series, y_series)
scatter.render()