本博文是我学习《Hadoop权威指南》第5章的笔记,主要是里面范例程序的实现,部分实现有修改
1 Mapper测试
需要使用mrunit这个jar包,在pom.xml添加dependency的时候,要添加classifier属性不然下载不了jar包,根据自己hadoop-core的版本来确定
<dependency>
<groupId>org.apache.mrunit</groupId>
<artifactId>mrunit</artifactId>
<version>1.1.0</version>
<classifier>hadoop2</classifier>
<scope>test</scope>
</dependency>编写测试类,测试,一切从简,你也可以严格按照书上的来,注意引用MapDriver的时候有两个引用,一个是mapreduce一个是mapred,根据自己的Mapper类是哪个版本来,mapred是老版本
package com.tuan.hadoopLearn.io.com.tuan.hadoopLearn.mapreduce;
import com.tuan.hadoopLearn.mapreduce.MaxTemperatureMapper;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mrunit.mapreduce.MapDriver;
import org.junit.jupiter.api.Test;
import java.io.IOException;
public class MaxTemperatureTest {
@Test
public void mapperTest() {
Text input = new Text("1993 38");
try {
new MapDriver<LongWritable, Text, Text, IntWritable>()
.withMapper(new MaxTemperatureMapper())
.withInput(new LongWritable(), input)
.withOutput(new Text("1993"), new IntWritable(38))
.runTest();
} catch (IOException e) {
e.printStackTrace();
}
}
}
2 Reducer测试
在上面的类里面再写一个Reducer测试
@Test
public void reducerTest() {
try {
new ReduceDriver<Text, IntWritable, Text, IntWritable>()
.withReducer(new MaxTemperatureReducer())
.withInput(new Pair<>(new Text("1993"), Arrays.asList(new IntWritable(10), new IntWritable(5))))
.withOutput(new Text("1993"), new IntWritable(10))
.runTest();
} catch (IOException e) {
e.printStackTrace();
}
}3 作业调试
例如,在处理最高气温的程序中,插入计数器以检测过大的异常输入,在Mapper类中插入几行代码,注意这里书上有一行代码的括号有误,我还奇怪枚举项怎么increment
package com.tuan.hadoopLearn.mapreduce;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class MaxTemperatureMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
private static final int MISSING = 9999;
enum Temperature {
OVER_100
}
@Override
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] line = value.toString().split(" ");
int temperature = Integer.parseInt(line[1]);
if (temperature > 100) {
context.setStatus("Detected possible corrupt input");
context.getCounter(Temperature.OVER_100).increment(1); //这里书上有错
}
context.write(new Text(line[0]), new IntWritable(temperature));
}
}
把input.txt后面加一条“1992 520”的异常记录,运行一下这个MapReduce程序,还是熟悉的命令
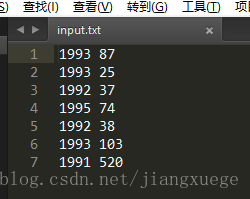
hadoop jar hadoopLearn-0.0.1-SNAPSHOT.jar com.tuan.hadoopLearn.mapreduce.MaxTemperature /mapreduce/input.txt /mapreduce/output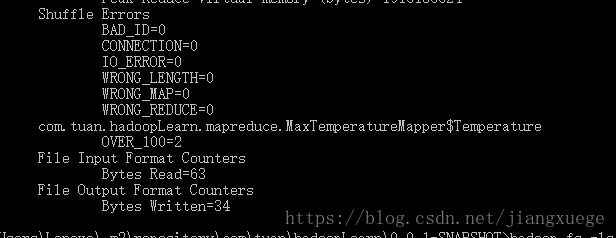
在作业结束后,可以看到定义的OVER_100计数器的计数值为2,证明有两个超过了100的异常输入
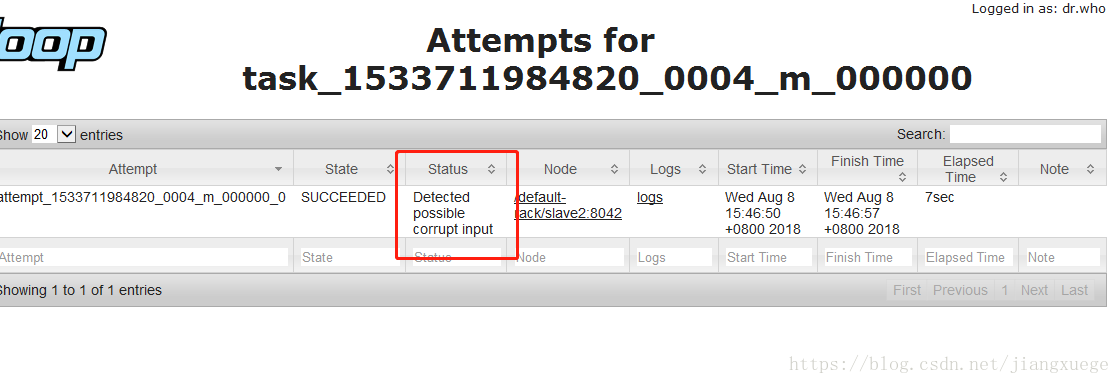
在web端查看一下historyserver,从下图这个红框的地方点进去,到了task界面找到mapper继续点

最后来到一个界面,可以看到Status已经变成了检测到异常输入
还可以查看Counter
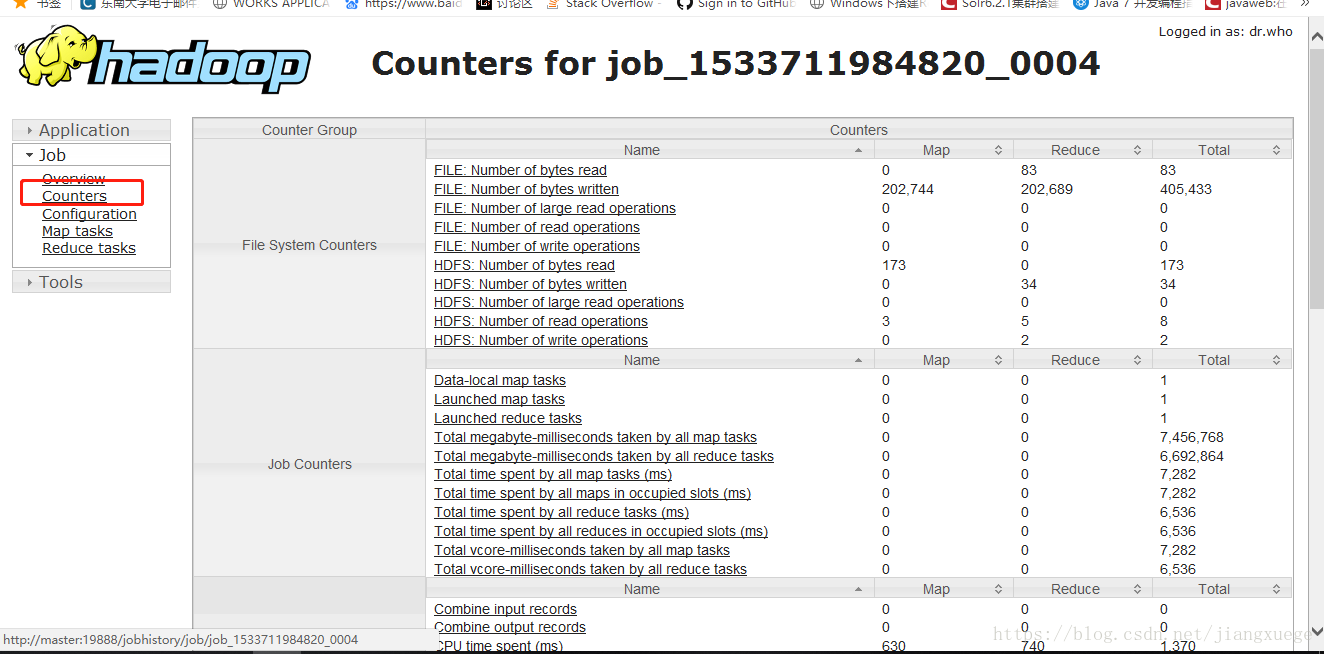
4 性能调优
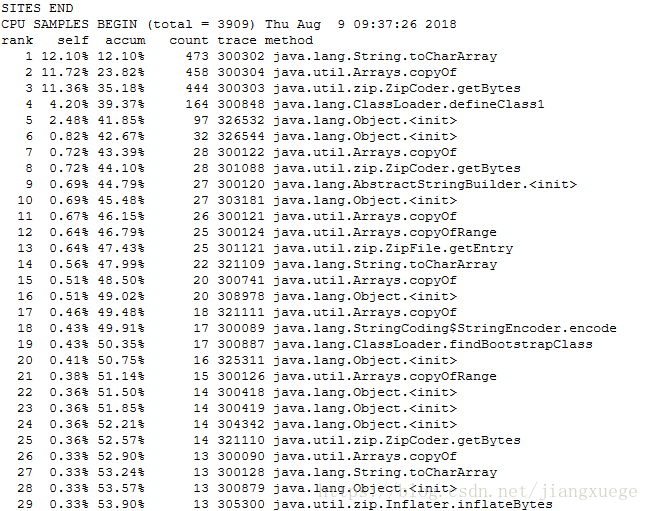
用Java提供的Hprof工具获取运行过程中的性能参数
重新写一个MaxTemperatureDriver,比之前的MaxTemperature多了一些Hprof的配置语句。一开始我的profile.out文件除了说明信息其他都是空的,最后发现是"mapreduce.task.profile.params"写成了"mapreduce.task,profile.params",也是醉了
package com.tuan.hadoopLearn.mapreduce;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class MaxTemperatureDriver extends Configured implements Tool {
@Override
public int run(String[] strings) throws Exception {
if (strings.length != 2) {
System.err.printf("Usage: %s [generic options] <input> <output>\n", getClass().getSimpleName());
ToolRunner.printGenericCommandUsage(System.err);
return -1;
}
Configuration conf = getConf();
conf.setBoolean("mapreduce.task.profile", true); //启用分析工具
conf.set("mapreduce.task.profile.params", "-agentlib:hprof=cpu=samples,heap=sites,depth=6," +
"force=n,thread=y,verbose=n,file=%s"); //JVM的分析参数配置
conf.set("mapreduce.task.profile.maps", "0-2"); //分析的map任务id范围
conf.set("mapreduce.task.profile.reduces", "0-2"); //分析的reduce任务id范围
Job job = new Job(conf, "Max Temperature");
job.setJarByClass(getClass());
FileInputFormat.addInputPath(job, new Path(strings[0]));
FileOutputFormat.setOutputPath(job, new Path(strings[1]));
job.setMapperClass(MaxTemperatureMapper.class);
job.setReducerClass(MaxTemperatureReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
return job.waitForCompletion(true) ? 0 : 1;
}
public static void main(String[] args) throws Exception {
System.exit(ToolRunner.run(new MaxTemperatureDriver(), args));
}
}
用熟悉的语句执行
hadoop jar hadoopLearn-0.0.1-SNAPSHOT.jar com.tua
n.hadoopLearn.mapreduce.MaxTemperatureDriver /mapreduce/input.txt /mapreduce/output进Web端,如下地方点击查看profile.out文件

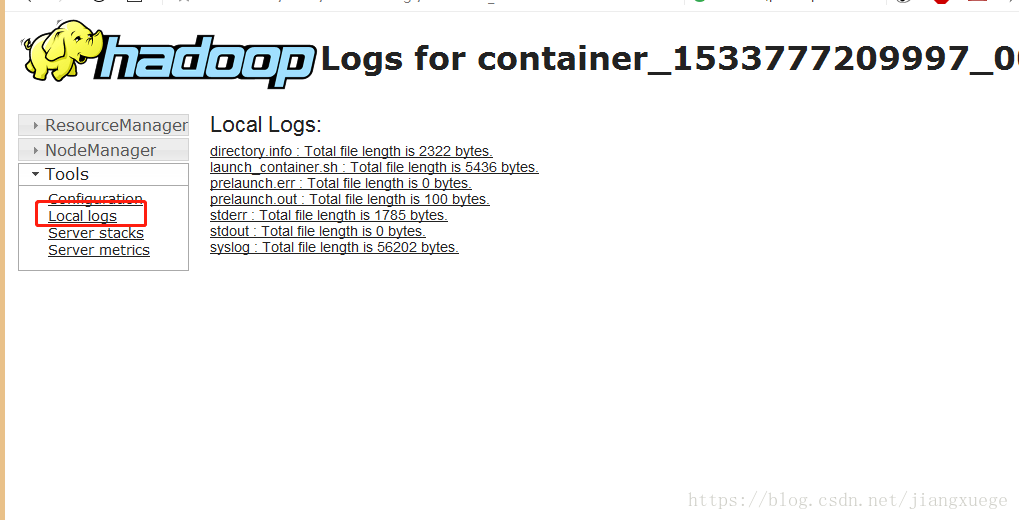
然后选择最下面的userlogs,点击自己的应用,层层目录下最终找到profile.out文件,文件很长,最后一段是统计了每个方法调用比例