本笔记根据学习徐培成老师大数据课程整理。
三、配置Hadoop
1.三种模式共存
配置hadoop,使用符号链接的方式,可以让三种配置形态共存。
(1)创建三个配置目录,内容等同于hadoop目录:
Hadoop的配置都在${Hadoop_home}/etc/hadoop下:
$cp -r ${Hadoop_home}/etc/Hadoop local //独立模式配置
$cp -r ${Hadoop_home}/etc/Hadoop pesudo //伪分布模式配置
$cp -r ${Hadoop_home}/etc/Hadoop full //完全模式配置
(2)建立符号链接,切换模式:
先把原先的hadoop文件夹删除后创建符号链接指向需要的模式
$rm -rf hadoop
$ ln -s pseudo hadoop
每种模式的具体配置:
2.standalone(local)
什么都不用配置就是本地模式
HDFS在本地模式下就是本地文件夹,不需要启用单独的进程(daemons),使用的就是本地文件系统,运行在单独的JVM上,适合在开发阶段运行Mapreduce程序,方便开发和测试。
$cd ~/soft/hadoop-2.7.3/bin/
$hdfs
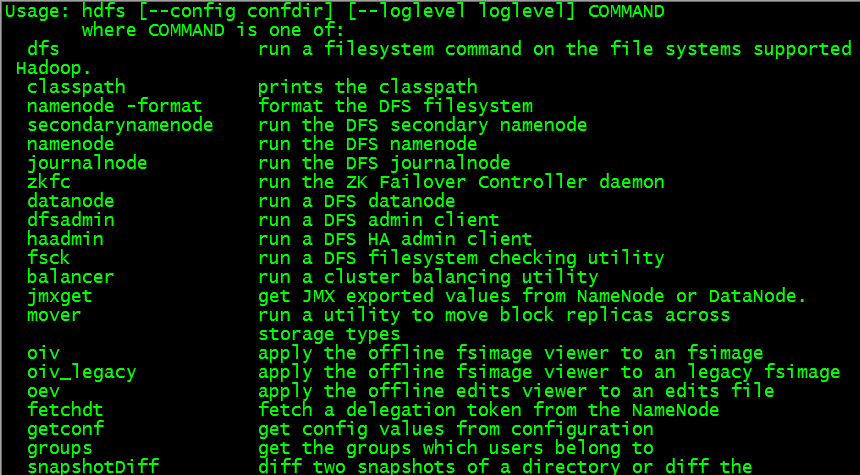
$ hdfs dfs –ls/

3.Pseudodistributed Mode(伪分布模式)
Hadoop守护进程运行在本地机器上,以小规模方式模拟一个集群,实际只有一个节点。
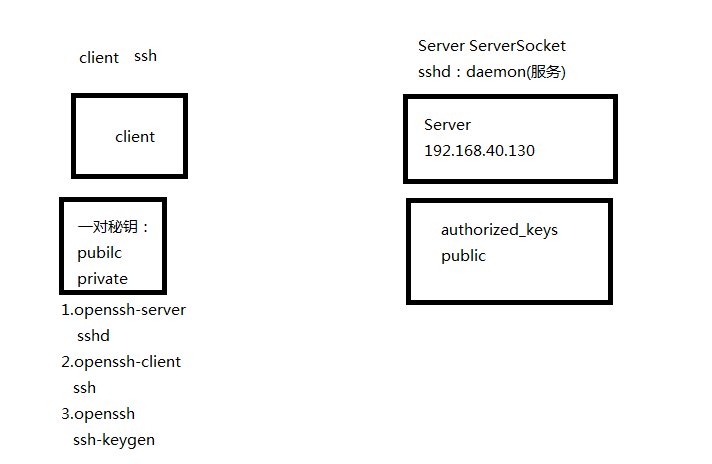
【配置摘要】
SSH (Socket)
Public+private
Server:sshd ps -Af|grep sshd
Client:ssh
ssh-kengen:生成公私秘钥
authorized_keys centos需要644
免密登录测试
需要配置的文件
core-site.xml // fs.defaultFS=hdfs://localhost:8020/
hdfs-site.xml // dfs.replication=1 伪分布只有一个节点
mapred-site.xml
yarn-site.xml
【详细配置】
进入${HADOOP_HOME}/etc/hadoop目录
$cd /home/ctr/soft/hadoop-2.7.3/etc/Hadoop
配置内容抄录自《Hadoop权威指南》
a) 编辑core-site.xml
<?xml version="1.0"?>
<!-- core-site.xml -->
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost/</value>
</property>
</configuration>
b) 编辑hdfs-site.xml
<?xml version="1.0"?>
<!-- hdfs-site.xml -->
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
c) 编辑mapred-site.xml
$ cp mapred-site.xml.template mapred-site.xml
<?xml version="1.0"?>
<!-- mapred-site.xml -->
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
d) 编辑yarn-site.xml
<?xml version="1.0"?>
<!-- yarn-site.xml -->
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>localhost</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
e) 配置SSH免秘登录
伪分布模式和完全分布模式工作方式一致,使用SSH远程登录主机时需要输入密码,如果不设置免密登录,管理节点登录从节点比较麻烦。
SSH基于C/S模式:
(1) 检查sshd是否已经启动
$ps –Af | grep sshd
如果没有先安装:
(2) 检查是否安装了相关软件包(openssh-server+openssh-clients+openssh)
$dpkg -l |grep xxx
(3) 在client端测试生成空的SSH秘钥对
先看有没有ssh-kengen
$which ssh-kengen
$ ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa

4)生成~/.ssh/文件夹,里面有id_rsa+id_rsa.pub(公钥)
可以进入.ssh目录看到公私秘钥文件夹:

5)将公钥加入到~/.ssh/authorized_keys的文件中
$cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
6)修改authorized_keys的权限为644(Ubuntu不需要,Centos需要)
默认Ubuntu和centos下改文件均为664,由于Centos特别要求。
$chmod 644 authorized_keys
7)测试是否可以免秘钥登录
$ssh localhost
f)格式化HDFS
HDFS格式化就是创建HDFS文件目录和文件系统结构的过程。
$ hadoop namenode –format
f) 启动hadoop所有进程
$start-all.sh //在hadoop的sbin目录下,已经加入环境变量
虽然JAVA_HOME已经设置但提示:
localhost:Error: JAVA_HOME is not set and could not be found
解决:修改hadoop配置文件,手动指定JAVA_HOME环境变量。
${Hadoop_HOME}/etc/hadoop/hadoop-env.sh

g) 启动完成后会出现以下进程
$ jps
10434 ResourceManager
9956 NameNode
10101 DataNode
10553 NodeManager
10281 SecondaryNameNode
h) 尝试在HDFS上新建目录并显示
$ hdfs dfs -mkdir -p /user/ubuntu/Hadoop
$ hdfs dfs -ls /
$ hdfs dfs -ls -R/

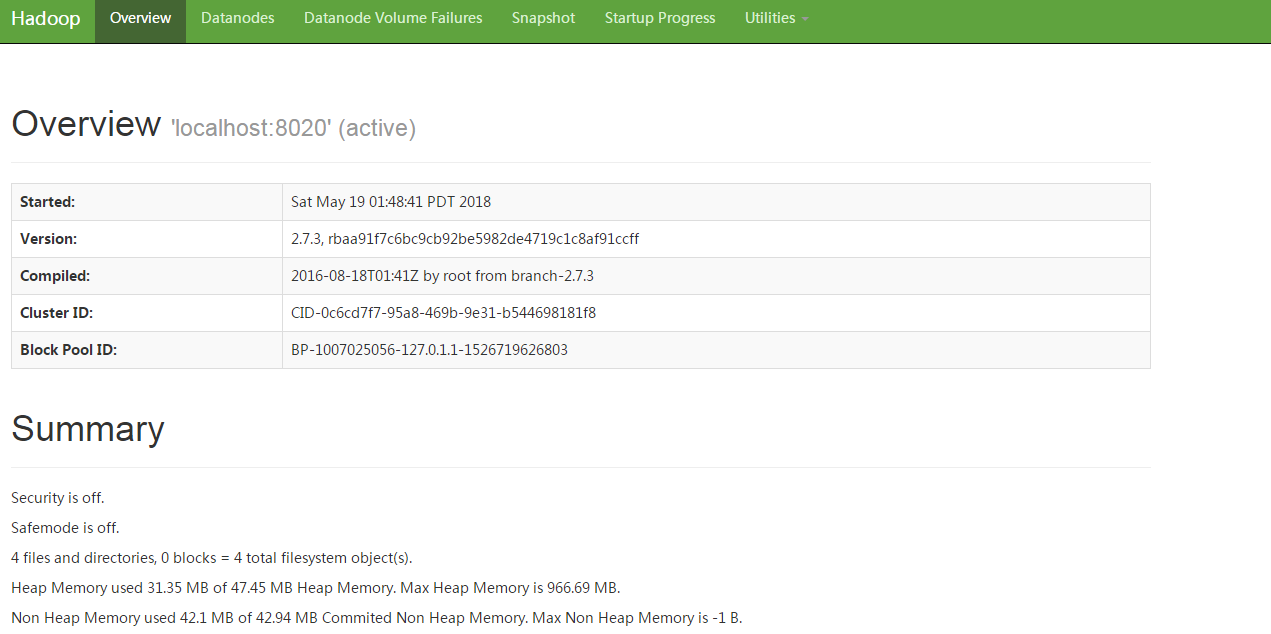
I)通过webui查看hadoop的文件系统
先查看50070端口是否已经启用监听:

可以看到0.0.0.0通配所有IP,可以在浏览器中进行访问:
【小结】
(a) 启动的进程
10434 ResourceManager
9956 NameNode
10101 DataNode
10553 NodeManager
10281 SecondaryNameNode
(b)Hadoop的端口
50070 //namenode http port
50075 //datanode http port
50090 //2nd namenode http port
8020 //namenode rpc port
50010 //datanode rpc port
(c)Hadoop四大模块
Common
Hdfs //namenode+datanode+secondarynamenode
Mapred
Yarn //resourcemanager+ nodemanager
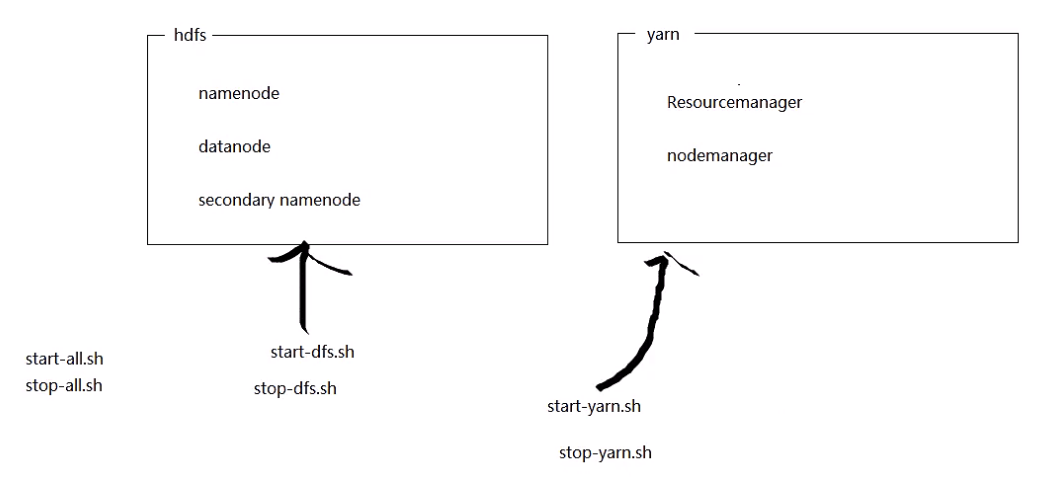
(d)启动脚本
(1)start-all.sh //启动所有进程,已经不推荐使用
(2)stop-all.sh //停止所有进程,已经不推荐使用
(3)start-dfs.sh //启动namenode(NN),datanode(DN),2nd namenode(2NN)
(4)start-yarn.sh //启动ResourceManager (RM)和NodeManager (NM)
4.Full(完全分布式)
【模拟拓扑】
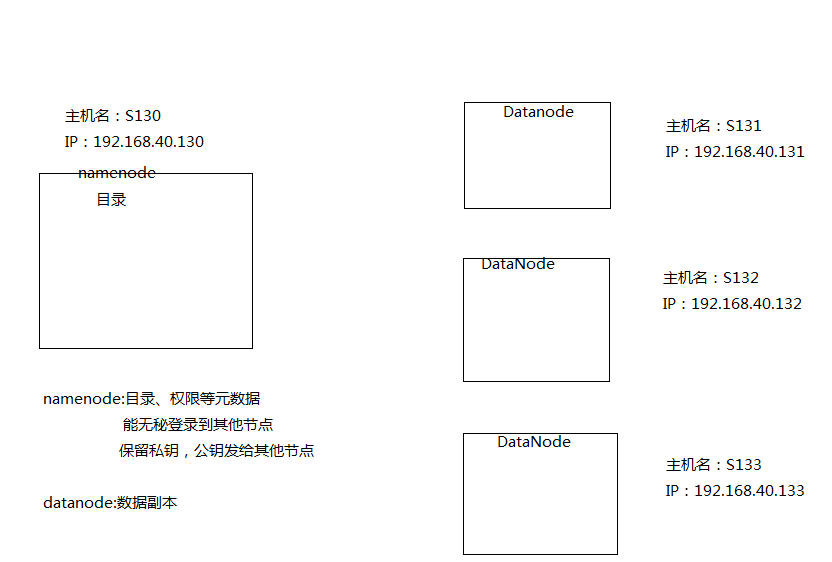
【修改主机名】
(1)/etc/hostname
$sudo nano /etc/hostname
修改为s130
(2)/etc/hosts
$sudo nano /etc/hosts
加入所有节点的解析
127.0.0.1 localhost
192.168.40.130 s130
192.168.40.131 s131
192.168.40.132 s132
192.168.40.133 s133
【主机克隆配置步骤】
(1) 克隆3台客户机(ubuntu)
虚拟机关闭后,右键选择”管理”->”克隆”->“完整克隆”。
对虚拟机进行编辑,开启共享文件夹。
(2) 启动客户机
(3) 修改hostname和ip地址文件
以S131为例子
$sudo nano /etc/network/interfaces
添加网卡配置
autoens33
ifaceens33 inet static
address192.168.40.131
netmask255.255.255.0
$sudo nano /etc/hostname
S131
(4)重启虚拟机(真实主机可以重启服务即可sudo /etc/init.d/networking restart)
$sudo reboot
在各台客户端上进行ping测试:
$ping s132
$ping s133
(5)修改/etc/resolve.conf文件
nameserver 192.168.231.2
(6)在其他客户机上重复(3)~(5)
【完全分布式主机的SSH配置】
(1) 删除所有主机上的/home/ctr/.ssh/*
(2) 在S130(NameNode)上重新生成秘钥对
$ ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
(3) 将S130的公钥文件id_rsa.pub远程复制到S131~S133主机上。并放置到各个客户机的/home/ctr/.ssh/authorized_keys
$cat id_rsa.pub >> authorized_keys
$scp id_rsa.pub ctr@s131:/home/ctr/.ssh/authorized_keys
$scp id_rsa.pub ctr@s132:/home/ctr/.ssh/authorized_keys
$scp id_rsa.pub ctr@s133:/home/ctr/.ssh/authorized_keys
测试从S130上是否可以无秘钥登录到各个DataNode
后面可以使用ssh s131 hostname等直接在S130上执行对其他主机的命令。
【配置完全分布式】
参照《Hadoop权威指南》,以下配置文件均在${HADOOP_HOME}/etc/下
[core-site.xml]
<?xml version="1.0"?>
<!-- core-site.xml -->
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://s130/</value>
</property>
</configuration>
[hdfs-site.xml]
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>
[mapred-site.xml]
不变
[yarn-site.xml]
<configuration>
<!-- Sitespecific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>s130</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
[slaves] //datanode
s131
s132
s133
[hadoop-env.sh] //Java路径
exportJAVA_HOME=/home/ctr/soft/jdk1.8.0_171
【分发配置到客户机】
在S130上将完全分布模式的配置文件夹Full远程复制到各个客户机,full文件夹是原始配置/home/ctr/soft/hadoop-2.7.3/etc/hadoop文件夹复制出来按照上一步修改配置文件后的文件。
$ scp -r full ctr@s131:/home/ctr/soft/hadoop-2.7.3/etc/
$ scp -r full ctr@s132:/home/ctr/soft/hadoop-2.7.3/etc/
$ scp -r full ctr@s133:/home/ctr/soft/hadoop-2.7.3/etc/
【将hadoop链接更新为full(完全分布式配置)】
以下操作在namenode(192.168.40.130)上完成
$cd /home/ctr/soft/hadoop-2.7.3/etc/
$rm -rf hadoop
$ln -s full Hadoop
$ ssh s131 rm -rf /home/ctr/soft/hadoop-2.7.3/etc/Hadoop
$ ssh s132 rm -rf /home/ctr/soft/hadoop-2.7.3/etc/Hadoop
$ ssh s133 rm -rf /home/ctr/soft/hadoop-2.7.3/etc/Hadoop
$ssh s131 ln -s /home/ctr/soft/hadoop-2.7.3/etc/full /home/ctr/soft/hadoop-2.7.3/etc/Hadoop
$ssh s132 ln -s /home/ctr/soft/hadoop-2.7.3/etc/full /home/ctr/soft/hadoop-2.7.3/etc/Hadoop
$ssh s133 ln -s /home/ctr/soft/hadoop-2.7.3/etc/full /home/ctr/soft/hadoop-2.7.3/etc/Hadoop
【删除临时目录文件】
以下操作在namenode(192.168.40.130)上完成
$cd /tmp
$rm -rf hadoop*
$ssh s131 rm -rf hadoop*
$ssh s132 rm -rf hadoop*
$ssh s133 rm -rf hadoop*
【删除日志文件】
以下操作在namenode(192.168.40.130)上完成
$cd /home/ctr/soft/hadoop-2.7.3/logs
$rm -rf *
$ ssh s131 rm -rf /home/ctr/soft/hadoop-2.7.3/logs/*
$ ssh s132 rm -rf /home/ctr/soft/hadoop-2.7.3/logs/*
$ ssh s133 rm -rf /home/ctr/soft/hadoop-2.7.3/logs/*
【格式化文件系统】
以下操作在namenode(192.168.40.130)上完成
$stop-all.sh
$hadoop namenode -format
【启动hadoop集群】
$start-all.sh

$jps

在Windows浏览器上登录网址http://192.168.40.130:50070/
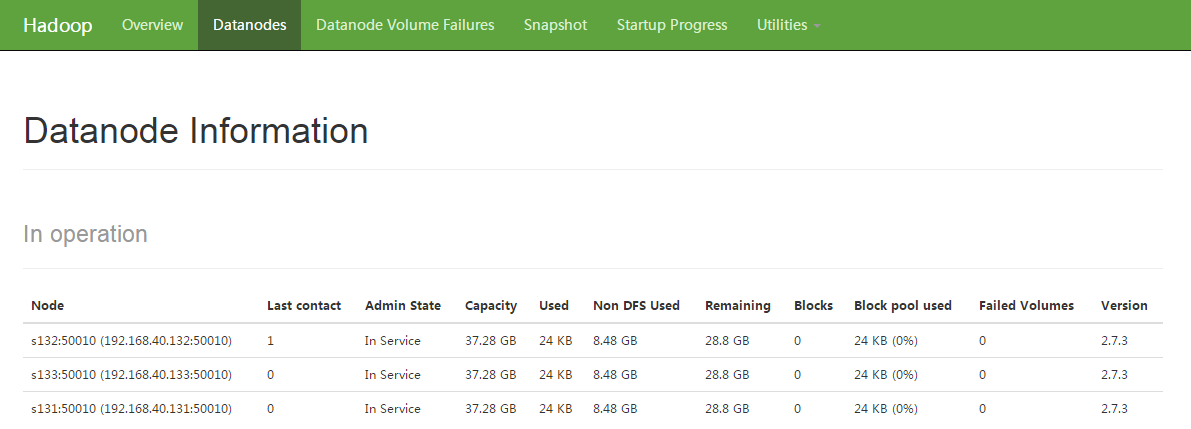
可以看到DataNode都已经启动