环境配置
Python 3.6
scikit-image 0.17.2
numpy 1.19.0
opencv-python 3.4.2.16
opencv-contrib-python 3.4.2.16
程序进程
读取训练数据
train_datagen = ImageDataGenerator(rescale=1./255,
rotation_range = 45,
width_shift_range = 0.2,
height_shift_range = 0.2,
shear_range = 0.2,
zoom_range = 0.2,
horizontal_flip=True)
train_gen = train_datagen.flow_from_directory("data/train",
target_size = (240, 240),
batch_size = 8,
class_mode="categorical")
ImageDataGenerator
可以进行数据增强;
参考链接:Keras ImageDataGenerator
- rescale : 将 0 ~ 255 的数值归一化到 0 ~ 1 之间;
- rotation_range : 整数,图片随机旋转角度,取值为 [0, 180],我认为一般默认是逆时针;
- width_shift_range : 浮点数,某个比例,图片随机水平平移的幅度,取值 [0, 1];
- height_shift_range : 浮点数,某个比例,图片随机竖直平移的幅度,取值 [0, 1];
- shear_range : 浮点数,表示(逆时针)剪切变换的程度;
- zoom_range : 浮点数,表示随即缩放的程度,或者为形如 [lower, upper]的列表;
- horizontal_flip : 布尔值,随机水平翻转;
自动根据文件夹来分类图片:
flow_from_directory
可以按照文件夹来编号,自动分类;

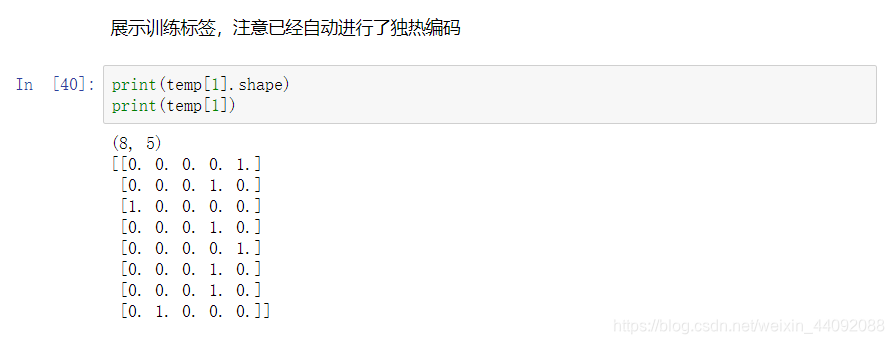
查看一个 batch 中的训练数据,一个 batch 里有 8 张图片,temp[0] 是图片,temp[1] 是标签;


数据范围是 0 ~ 1:
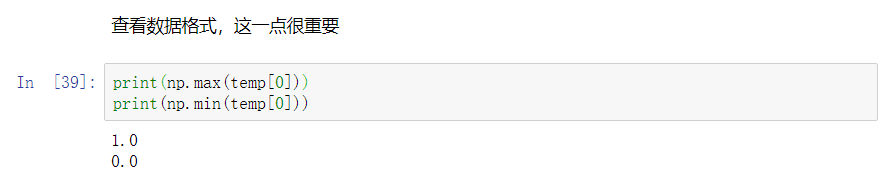
独热编码已完成:

载入网上预先训练好了的模型
VGG = keras.applications.vgg16.VGG16(weights="imagenet", include_top=False, input_shape=[240, 240, 3])

或者载入本地存取的文件:
from keras.models import load_model
VGG = load_model("model/VGG_Pretrained.h5")
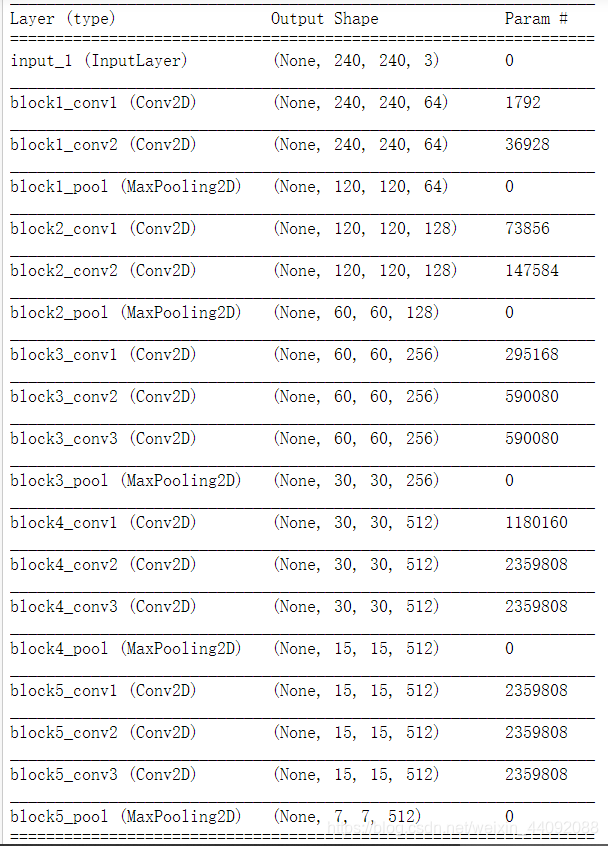
查看模型信息:

在模型末尾加入分类器
from keras.layers import Dense, Flatten
x = VGG.layers[-1].output
x = Flatten()(x)
x = Dense(64, activation="sigmoid")(x)
predictions=Dense(5, activation="softmax")(x)
model = keras.Model(inputs=VGG.inputs, outputs=predictions)
在模型后面加入分类器,注意输出层神经元个数要和标签一致,一定要加入Flatten,不然dense layer无法接受矩阵输入;
简单来说,就添加了两层神经元,比较麻烦的是和原来的模型连接起来;
for layer in model.layers[:-2]:
layer.trainable=False
只训练最后两层;

定义优化器
adam = Adam(lr=0.001, beta_1=0.9, beta_2=0.999, epsilon=1e-8)
model.compile(loss="categorical_crossentropy", optimizer=adam, metrics=["accuracy"])
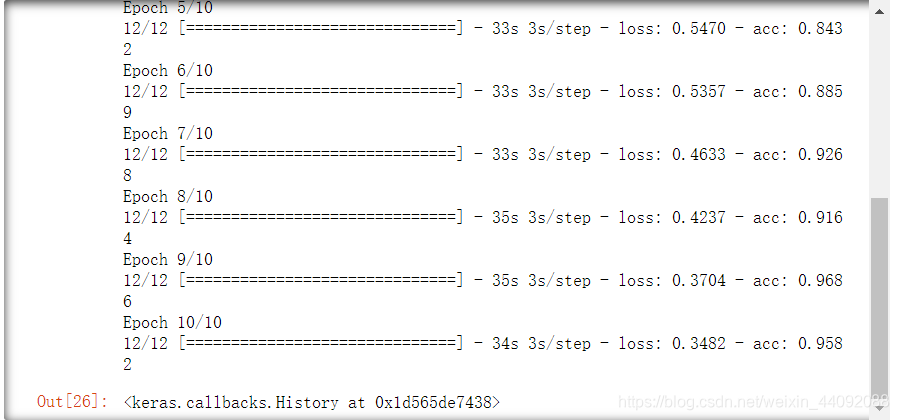
训练模型
model.fit_generator(train_gen, steps_per_epoch=12, epochs=10)
把训练好的模型存起来:

载入测试数据
import skimage.io as io
import skimage.transform as transform
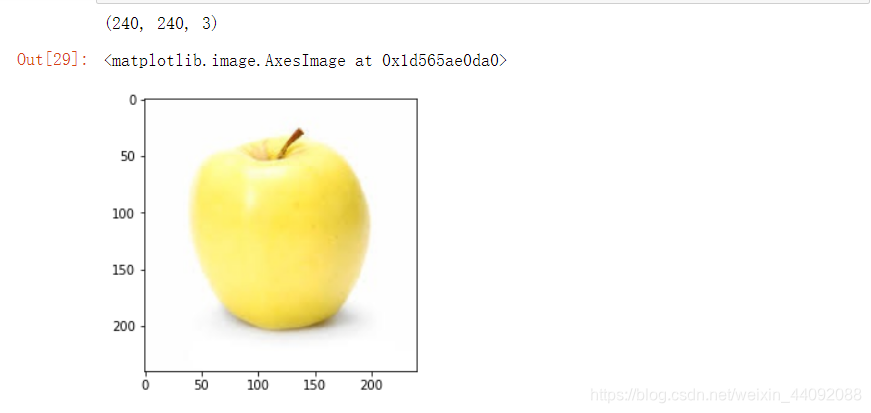
img = io.imread("data/test/3.jpg")
img = img/255
img = transform.resize(img, output_shape=[240, 240])
print(img.shape)
plt.imshow(img)
开始测试:
indices = {'紫葡萄': 0, '红苹果': 1, '绿葡萄': 2, '黄苹果': 3, '黄香蕉': 4}
output = model.predict(img.reshape([1, 240, 240, 3]))
print(output)
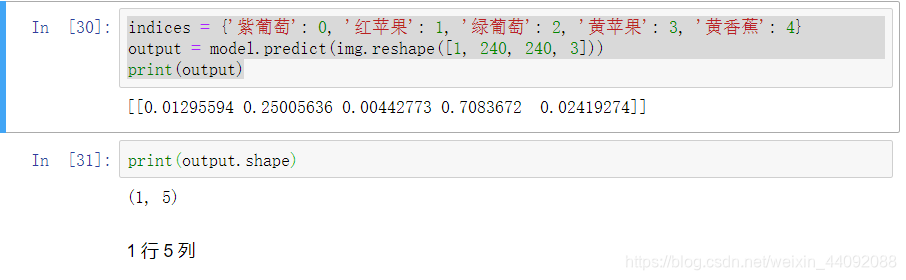
输出结果
output_r 有两个数字,分别表示预测结果是多少行和多少列:

完整源代码
无多余输出信息
# 完整版
import numpy as np
import keras
import matplotlib.pyplot as plt
from keras.models import Sequential
from keras.optimizers import Adam
from keras.utils.np_utils import to_categorical
from keras.preprocessing.image import ImageDataGenerator
train_datagen = ImageDataGenerator(rescale=1./255,
rotation_range = 45,
width_shift_range = 0.2,
height_shift_range = 0.2,
shear_range = 0.2,
zoom_range = 0.2,
horizontal_flip=True)
train_gen = train_datagen.flow_from_directory("data/train",
target_size = (240, 240),
batch_size = 8,
class_mode="categorical")
# 从网上下载预先存取好的模型
VGG = keras.applications.vgg16.VGG16(weights="imagenet", include_top=False, input_shape=[240, 240, 3])
# 或者直接从本地导入
# from keras.models import load_model
# VGG = load_model("model/VGG_Pretrained.h5")
# 在原模型末尾加入分类器
from keras.layers import Dense, Flatten
x = VGG.layers[-1].output
x = Flatten()(x)
x = Dense(64, activation="sigmoid")(x)
predictions=Dense(5, activation="softmax")(x)
model = keras.Model(inputs=VGG.inputs, outputs=predictions)
# 设置为只需要训练最后新加入的两层神经元
for layer in model.layers[:-2]:
layer.trainable=False
# 定义优化器
adam = Adam(lr=0.001, beta_1=0.9, beta_2=0.999, epsilon=1e-8)
model.compile(loss="categorical_crossentropy", optimizer=adam, metrics=["accuracy"])
# 训练模型
model.fit_generator(train_gen, steps_per_epoch=12, epochs=10)
# 载入测试数据
import skimage.io as io
import skimage.transform as transform
img = io.imread("data/test/3.jpg")
img = img/255
img = transform.resize(img, output_shape=[240, 240])
# print(img.shape) # 查看图片信息
# plt.imshow(img)
# 结果展示
indices = {'紫葡萄': 0, '红苹果': 1, '绿葡萄': 2, '黄苹果': 3, '黄香蕉': 4}
output = model.predict(img.reshape([1, 240, 240, 3]))
# print(output)
# 使得结果更加清晰
output_r = np.where(output==np.max(output))
print(np.max(output_r[1])) # 表示预测结果的列编号