凤凰网热点新闻数据
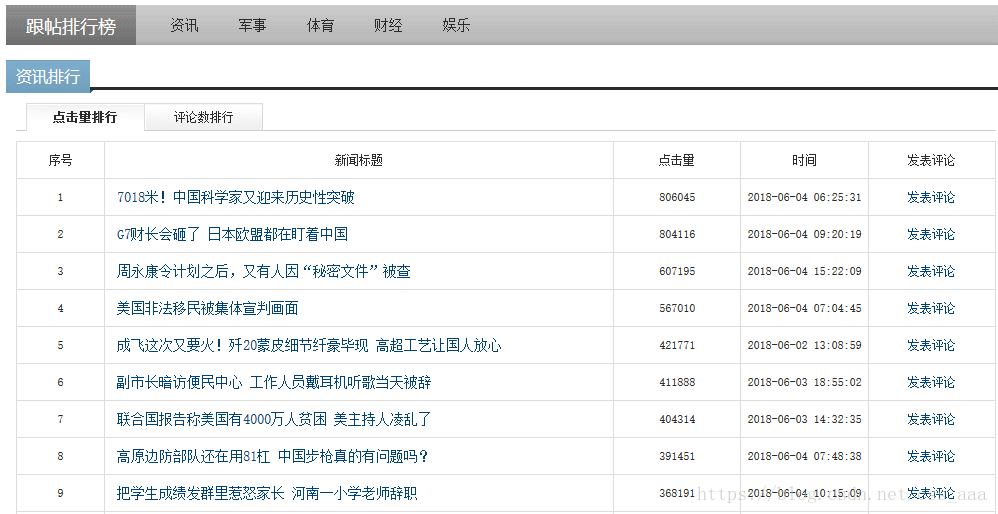
查看网页源代码,发现每个排行的数据在标签<div class="boxTab clearfix">中,共五个div标签
import requests
from bs4 import BeautifulSoup
url = 'http://news.ifeng.com/hotnews/'
req = requests.get(url)
html = req.content.decode('utf-8')#这里用utf-8解析
div_bf = BeautifulSoup(html,'html.parser')#html.parser解析器
new = div_bf.find_all('div',class_='boxTab clearfix')#筛选所有div标print(new)
[<div class="boxTab clearfix"><a name="news"></a>
<div class="tit"><span class="c_01">资讯排行</span></div>
<ul class="label_01"><li class="current" id="m01">点击量排行</li><li id="m02">评论数排行</li></ul>
<div class="conTab">
<div class="tab_01" id="c01">
<table border="1" bordercolor="#cfcfcf" cellpadding="0" cellspacing="0" style="border-color:#ddd;" width="100%">
<tr>
<td width="9%">序号</td>
<td width="52%">新闻标题</td>
<td width="13%">点击量</td>
<td width="13%">时间</td>
<td width="13%">发表评论</td>
</tr>
<tr>
<td nowrap="">1</td>
<td nowrap=""><h3><a href="http://news.ifeng.com/a/20180604/58565046_0.shtml" target="_blank">7018米!中国科学家又迎来历史性突破</a></h3></td>
<td nowrap="">806045</td>
<td nowrap="">2018-06-04 06:25:31</td>
<td nowrap=""><a href="http://comment.ifeng.com/view.php?docName=7018米!中国科学家又迎来历史性突破&docUrl=http://news.ifeng.com/a/20180604/58565046_0.shtml" target="_blank">发表评论</a></td>
</tr>以上代码为输出的部分new数据,type(new)为列表,输出的数据中所需要的数据都在<tr>和<td>标签中,进一步用BeautifulSoup解析(解析时需要用str())并筛选
first = BeautifulSoup(str(new[0]),'html.parser')
first_new = first.find_all('tr')
print(first_new)
[<tr>
<td width="9%">序号</td>
<td width="52%">新闻标题</td>
<td width="13%">点击量</td>
<td width="13%">时间</td>
<td width="13%">发表评论</td>
</tr>, <tr>
<td nowrap="">1</td>
<td nowrap=""><h3><a href="http://news.ifeng.com/a/20180604/58565046_0.shtml" target="_blank">7018米!中国科学家又迎来历史性突破</a></h3></td>
<td nowrap="">806045</td>
<td nowrap="">2018-06-04 06:25:31</td>
<td nowrap=""><a href="http://comment.ifeng.com/view.php?docName=7018米!中国科学家又迎来历史性突破&docUrl=http://news.ifeng.com/a/20180604/58565046_0.shtml" target="_blank">发表评论</a></td>
</tr>, <tr>>>> print(first_new[0])
<tr>
<td width="9%">序号</td>
<td width="52%">新闻标题</td>
<td width="13%">点击量</td>
<td width="13%">时间</td>
<td width="13%">发表评论</td>
</tr>first_new_td = BeautifulSoup(str(first_new[0]),'html.parser')
first_new_item = first_new_td.find_all('td')
print(first_new_item[1].text,first_new_item[0].text,first_new_item[2].text,first_new_item[3].text)
新闻标题 序号 点击量 时间#coding:utf-8
from bs4 import BeautifulSoup
import requests
def spider_Information():
global new
from tool.models import Information
first = BeautifulSoup(str(new[0]),'html.parser')#new[0]代表只爬取资讯新闻,其中len(new)为5,即五个div标签
first_new = first.find_all('tr')
for i in range(20):#20代表资讯的20条新闻信息
first_new_td = BeautifulSoup(str(first_new[i+1]),'html.parser')
first_new_item = first_new_td.find_all('td')
print(first_new_item[1].text,first_new_item[0].text,first_new_item[2].text,first_new_item[3].text)
if __name__ == "__main__":
url = 'http://news.ifeng.com/hotnews/'
req = requests.get(url)
html = req.content.decode('utf-8')
div_bf = BeautifulSoup(html,'html.parser')
new = div_bf.find_all('div',class_='boxTab clearfix')
spider_Information()
print('Information Done!')