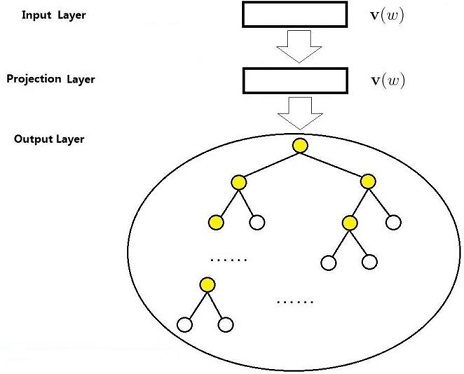
Huffman树的构造
解析:给定n个权值作为n个叶子节点,构造一棵二叉树,若它的带权路径长度达到最小,则称这样的二叉树为最优二叉树,也称Huffman树。数的带权路径长度规定为所有叶子节点的带权路径长度之和。Huffman树构造,如下所示:
(1)将{w1,w2,...,w3} 看成是有n颗树的森林;
(2)在森林中选出两个根节点的权值最小的树合并,作为一棵新树的左、右子树,且新树的根节点权值为其左、右子树根节点权值之和;
(3)从森林中删除选取的两颗树,并将新树加入森林;
(4)重复(2)(3)步,直到森林中只剩一棵树为止,该树即为所求的Huffman树。
说明:利用Huffman树设计的二进制前缀编码,称为Huffman编码,它既能满足前缀编码条件,又能保证报文编码总长最短。基于Hierarchical Softmax的模型(CBOW模型)
解析:

其中参数的物理意义,如下所示:
(1)Xw=∑i=12cv(Context(w)i)∈Rm
(2)dwj 表示路径pw 中第j 结点对应的编码(根结点不对应编码)
(3)θwj 表示路径pw 中第j 非叶子结点对应的向量
(4)pw 表示从根结点出发到达w 对应叶子结点的路径。
(5)lw 表示路径pw 中包含结点的个数。
Hierarchical Softmax基本思想,如下所示:
p(w|Context(w))=∏j=2lwp(dwj|xw,θwj−1)
p(dwj|xw,θwj−1)=[σ(xTwθwj−1)]1−dwj⋅[1−σ(xTwθwj−1)]dwj
对于word2vec中基于Hierarchical Softmax的CBOW模型,优化的目标函数,如下所示:
L=∑w∈Clogp(w|Context(w))
这样得到对数似然函数,如下所示:
L=∑w∈Clog∏j=2lw{[σ(xTwθwj−1)]1−dwj⋅[1−σ(xTwθwj−1)]dwj}=∑w∈C∑j=2lw{(1−dwj)⋅log[σ(xTwθwj−1)]+dwj⋅log[1−σ(xTwθwj−1)]}
将花括号中的内容简记为L(w,j) ,如下所示:
L(w,j)=(1−dwj)⋅log[σ(xTwθwj−1)]+dwj⋅log[1−σ(xTwθwj−1)]
使用随机梯度上升法对θwj−1 求偏导,如下所示:
∂L(w,j)∂θwj−1=∂∂θwj−1{(1−dwj)⋅log[σ(xTwθwj−1)]+dwj⋅log[1−σ(xTwθwj−1)]}=(1−dwj)⋅[1−σ(xTwθwj−1)]xw−dwj⋅σ(xTwθwj−1)xw={(1−dwj)⋅[1−σ(xTwθwj−1)]−dwj⋅σ(xTwθwj−1)}xw=[1−dwj−σ(xTwθwj−1)]xw
θwj−1 的更新方程,如下所示:
θwj−1:=θwj−1+η[1−dwj−σ(xTwθwj−1)]xw
使用随机梯度上升法对xw 求偏导,如下所示:
∂L(w,j)∂xw=[1−dwj−σ(xTwθwj−1)]θwj−1
对于词典中每个词的词向量v(w~) 更新方程,如下所示:
v(w~):=v(w~)+η∑j=2lw∂L(w,j)∂xw,w~∈Context(w) 基于Hierarchical Softmax的模型(Skip-Gram模型)
解析:
其中,v(w)∈Rm 表示当前样本的中心词w 的词向量。
对于word2vec中基于Hierarchical Softmax的Skip-Gram模型,优化的目标函数,如下所示:
L=∑w∈Clogp(Context(w)|w)
Skip-Gram模型中条件概率函数p(Context(w)|w) ,如下所示:
p(Context(w)|w)=∏u∈Context(w)p(u|w)
p(u|w)=∏j=2lup(duj|v(w),θuj−1)
p(duj|v(w),θuj−1)=[σ(v(w)Tθuj−1)]1−duj⋅[1−σ(v(w)Tθuj−1)]duj
这样得到对数似然函数,如下所示:
L=∑w∈Clog∏u∈Context(w)∏j=2lu{[σ(v(w)Tθuj−1)]1−duj⋅[1−σ(v(w)Tθuj−1)]duj}=∑w∈C∑u∈Context(w)∑i=2lu{(1−duj)⋅log[σ(v(w)Tθuj−1)]+duj⋅log[1−σ(v(w)Tθuj−1)]}
将花括号中的内容简记为L(w,u,j) ,如下所示:
L(w,u,j)=(1−duj)⋅log[σ(v(w)Tθuj−1)]+duj⋅log[1−σ(v(w)Tθuj−1)] 基于Negative Sampling的模型(CBOW模型)
Negative Sampling不再使用Huffman树,而是使用随机负采样,能大幅度提高性能。假定已经选好w 的负样本子集NEG(w)≠∅ ,定义词w~ 的标签(正样本为1,负样本为0),如下所示:
Lw(w~)={1,w~=w0,w~≠w
对于给定的正样本(Context(w),w) ,最大化g(w) ,如下所示:
g(w)=∏u∈{w}∪NEG(w)p(u|Context(w))
p(u|Context(w))=[σ(xTwθu)]Lw(u)⋅[1−σ(xTwθu)][1−Lw(u)]
其中,xw 表示Context(w) 中各词的词向量之和,θu∈Rm 表示词u 对应的一个辅助向量,为待训练的参数。简化g(w) 方程,如下所示:
g(w)=σ(xTwθw)∏u∈NEG(w)[1−σ(xTwθu)]
其中,σ(xTwθw) 表示当上下文为Context(w) 时,预测中心词为w 的概率,同样σ(xTwθu),u∈NEG(w) 表示当上下文为Context(w) 时,预测中心词为u 的概率。
对于给定的语料库C ,目标函数如下所示:
L=logG=log∏w∈Cg(w)=∑w∈Clogg(w)=∑w∈Clog∏u∈{w}∪NEG(w){[σ(xTwθu)]Lw(u)⋅[1−σ(xTwθu)]1−Lw(u)}=∑w∈C∑u∈{w}∪NEG(w){Lw(u)⋅log[σ(xTwθu)]+[1−Lw(u)]⋅log[1−σ(xTwθu)]}=∑w∈C⎧⎩⎨log[σ(xTwθw)]+∑u∈NEG(w)log[1−σ(xTwθu)]⎫⎭⎬=∑w∈C⎧⎩⎨log[σ(xTwθw)]+∑u∈NEG(w)log[σ(−xTwθu)]⎫⎭⎬
记L(w,u)=Lw(u)⋅log[σ(xTwθu)]+[1−Lw(u)]⋅log[1−σ(xTwθu)] ,使用随机梯度上升法对θu 求偏导,如下所示:
∂L(w,u)∂θu=∂∂θu{Lw(u)⋅log[σ(xTwθu)]+[1−Lw(u)]⋅log[1−σ(xTwθu)]}=Lw(u)[1−σ(xTwθu)]xw−[1−Lw(u)]σ(xTwθu)xw={Lw(u)[1−σ(xTwθu)]−[1−Lw(u)]σ(xTwθu)}xw=[Lw(u)−σ(xTwθu)]xw
参数θu 的更新方程,如下所示:
θu:=θu+η[Lw(u)−σ(xTwθu)]xw
使用随机梯度上升法对xw 求偏导,如下所示:
∂L(w,u)∂xw=[Lw(u)−σ(xTwθu)]θu
参数v(w~),w~∈Context(w) 的更新方程,如下所示:
v(w~):=v(w~)+η∑u∈{w}∪NEG(w)∂L(w,u)∂xw,w~∈Context(w) 基于Negative Sampling的模型(Skip-Gram模型)
对于给定的语料库C ,目标函数如下所示:
G=∏w∈C∏u∈Context(w)g(u)
g(u)=∏z∈{u}∪NEG{u}p(z|w)
p(z|w)=[σ(v(w)Tθz)]Lu(z)⋅[1−σ(v(w)Tθz)]1−Lu(z)
L=logG=log∏w∈C∏u∈Context(w)g(u)=∑w∈C∑u∈Context(w)logg(u)=∑w∈C∑u∈Context(w)log∏z∈{u}∪NEG{u}p(z|w)=∑w∈C∑u∈Context(w)∑z∈{u}∪NEG{u}log{[σ(v(w)Tθz)]Lu(z)⋅[1−σ(v(w)Tθz)]1−Lu(z)}=∑w∈C∑u∈Context(w)∑z∈{u}∪NEG{u}{Lu(z)⋅log[σ(v(w)Tθz)]+[1−Lu(z)]⋅log[1−σ(v(w)Tθz)]}
对每一个样本(w,Context(w)) ,需要针对Context(w) 中的每一个词进行负采样,但是word2vec源码中只是针对w 进行了|Context(w)| 次负采样。它本质上用的还是CBOW模型,只是将原来通过求和累加做整体用的上下文Context(w) 拆成一个一个来考虑。对于给定的语料库C ,目标函数如下所示:
g(w)=∏w~∈Context(w)∏u∈{w}∪NEGw~(w)p(u|w~)
p(u|w~)=[σ(v(w~)Tθu)]Lw(u)⋅[1−σ(v(w~)Tθu)]1−Lw(u)
L=logG=log∏w∈Cg(w)=∑w∈Clogg(w)=∑w∈Clog∏w~∈Context(w)∏u∈{w}∪NEGw~(w){[σ(v(w~)Tθu)]Lw(u)⋅[1−σ(v(w~)Tθu)]1−Lw(u)}=∑w∈Clog∑w~∈Context(w)∑u∈{w}∪NEGw~(w){Lw(u)⋅log[σ(v(w~)Tθu)]+[1−Lw(u)]⋅log[1−σ(v(w~)Tθu)]}
记L(w,w~,u)=Lw(u)⋅log[σ(v(w~)Tθu)]+[1−Lw(u)]⋅log[1−σ(v(w~)Tθu)] 。使用随机梯度上升法,对θu 求偏导,如下所示:
∂L(w,w~,u)∂θu=∂L∂θu{Lw(u)⋅log[σ(v(w~)Tθu)]+[1−Lw(u)]⋅log[1−σ(v(w~)Tθu)]}=Lw(u)[1−σ(v(w~)Tθu)]v(w~)−[1−Lw(u)]σ(v(w~)Tθu)v(w~)={Lw(u)[1−σ(v(w~)Tθu)]−[1−Lw(u)]σ(v(w~)Tθu)}v(w~)=[Lw(u)−σ(v(w~)Tθu)]v(w~)
θu 的更新方程,如下所示:
θu:=θu+η[Lw(u)−σ(v(w~)Tθu)]v(w~)
使用随机梯度上升法,对v(w~) 求偏导,如下所示:
∂L(w,w~,u)∂v(w~)=[Lw(u)−σ(v(w~)Tθu)]θu
参数v(w~) 的更新,如下所示:
v(w~):=v(w~)+η∑u∈{w}∪NEGw~(w)∂L(w,w~,u)∂v(w~)
其中,NEGw~(w) 表示处理词w~ 时生成的负样本子集。- Negative Sampling算法
(1)带权采样原理
设词典D 中的每一个词w 对应一个线段l(w) ,长度如下所示:
len(w)=counter(w)∑u∈Dcounter(u)
这里counter(⋅) 表示一个词在语料C 中出现的次数。现在将这些线段首尾相连地拼接在一起,形成一个长度为1的单位线段。如果随机地往这个单位线段上打点,那么其中长度越长的线段(对应高频词)被打中的概率就越大。
(2)word2vec负采样
记l0=0 ,lk=∑j=1klen(wj),k=1,2,⋯,N ,这里wj 表示词典D 中第j 个词,则以{lj}Nj=0 为剖分结点可得到区间[0,1] 上的一个非等距剖分,Ii=(li−1,li],i=1,2,⋯,N 为其N 个剖分区间。进一步引入区间[0,1] 上的一个等距离剖分,剖分结点为{mj}Mj=0 ,其中M≫N ,具体示意图如下所示:

将内部剖分结点{mj}M−1j=1 投影到非等距剖分上,则可建立{mj}M−1j=1 与区间{Ij}Nj=1 (或{wj}Nj=1 )的映射关系,如下所示:
Table(i)=wk,mi∈Ik,i=1,2,⋯,M−1
根据映射每次生成一个[1,M−1] 间的随机整数r ,Table(r) 就是一个样本。当对wi 进行负采样时,如果采样为wi ,那么就跳过去。
参考文献:
[1] word2vec中的数学原理详解