(一)基本概念
查找表 用于查找的数据集合称
(二)顺序查找
无序表 平均查找长度ASL=(n+1)/2
有序表 如果查到某个值大于待查找值, 则后面可以不用找了 比一般顺序查找的算法要好一些
(三)分块查找
又称为索引顺序查找: 首先把查找表分块, 然后建立一个索引表包含每一块的第一个元素
(四)折半查找
只适用于有序的顺序表
设查找表升序排列, 首先将中间的元素与待查找元素比较, 如果相等查找结束, 否则利用中间位置的记录将表分为左右两个, 如果待查找元素比中间元素小, 就进一步查找左边子表 否则查找右边子表
(五)B树及其基本操作 B树动画视频 参考博客 (先看动画再看博客中的插入和删除的步骤)
B树出现的原因:解决二叉平衡树孩子太少、查找一个数字层次太深,频繁读取硬盘的问题。把二叉改成多叉了。
又称为多路平衡查找树
(到最后也没研究明白B树和B+树的具体操作 只能详见参考博客了)
B+树的与B树的主要差异:(1)如果一个结点有n个关键字,那么B树有n+1个子树,而B+树有n个子树
(2)B+树的叶节点不包含信息,仅起到索引作用 // 个人看法: 感觉B+树类似于内存管理的多级页表
B+树的查找过程:通常在B+树中有两个头指针,一个指向根节点,一个指向最小值。因此可以对B+树进行两种查找运算,一种从最小关键字开始顺序查找,另一种,从根节点开始进行多路查找。
(六)散列表
哈希函数:一个把关键字映射成该关键字对应地址的函数
散列表:根据关键字进行访问的数据结构。散列建立了关键字和地址之间的直接映射关系
散列函数的构造方法
①直接定址法 H(key)=a*key+b 特点:空位较多, 适用于连续情况
②除留取余法 H(key)=key%p 关键是选好p,减少冲突
③数字分析法 比如十进制数 0-9在各位出现的频率不一定相同 应该选取数码分布较为均匀的若干位作为散列地址
④平方取中法 将关键字取平方然后取中间几位作为散列地址. 这样得到的散列地址关键字与每一位都有关系, 散列分布比较均匀
⑤折叠法 关键字位数很多, 则可以将位数分成相同的几部分, 然后将这几部分叠加起来
处理冲突的方法
①开放定址法(允许空闲地址向非同义词开放) 线性探测法 平方探测法 再散列法 伪随机序列法
②拉链法
(七)字符串模式匹配
针对模式串, 预先定义一个数组, 存放从1开始串和从某元素开始的串的最长相等长度(注: 这是我瞎编的, 其实应该找每个位置找到的最长公共前缀).
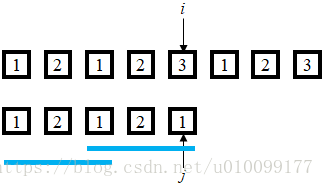

比如现在的状态i和j所指的数字不一致了, 就把下面那个串右移. 从第2个数开始测试 发现从2开始的子串与从1开始的相同子串太短了无法满足需求.
(八)查找算法的分析与应用