前导:读书笔记中涉及的实现代码地址链接
一、算法复杂度通过时间复杂度表示O(n)
大O表示法是一种特殊的表示法,指出了算法的速度有多快。
一些常见的大 O 运行时间:
- O(log n),也叫对数时间,这样的算法包括二分查找。
- O(n),也叫线性时间,这样的算法包括简单查找。
- O(n * log n),这样的算法包括快速排序——一种速度较快的排序算法。
- O(n2),这样的算法包括选择排序——一种速度较慢的排序算法。
- O(n!),这样的算法包括接旅行商问题的解决方案——一种非常慢的算法
- 算法的速度指的并非时间,而是操作数的增速。
- 谈论算法的速度时,我们说的是随着输入的增加,其运行时间将以什么样的速度增加。
- 算法的运行时间用大O表示法表示。
- O(log n)比O(n)快,当需要搜索的元素越多时,前者比后者快得越多。
二、选择排序
内存模型:堆和栈的区别
- 链表的每个元素都存储了下一个元素的地址,从而使一系列随机的内存地址串在一起。
- 数组的元素带编号,编号从0而不是1开始。在同一个数组中,所有元素的类型都必须相同(都为int、 double等)
- Python中数组的创建方式如下:
from array import array
# typecode (must be b, B, u, h, H, i, I, l, L, q, Q, f or d) # 类型取得这个里面的一个
array('l')
array('l', [1, 2, 3, 4, 5])
print(array('l', [1, 2, 3, 4, 5]))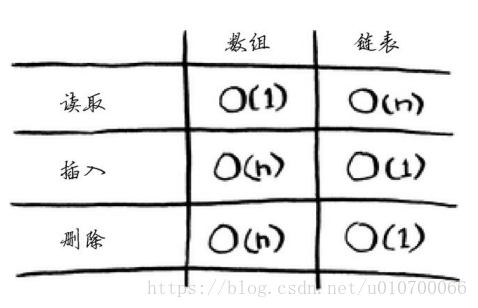
1.选择排序
def findSmallest(arr):
smallest = arr[0]
smallest_index = 0
for i in range(1, len(arr)):
if arr[i] < smallest:
smallest = arr[i] # 存储最小的值
smallest_index = i #存储最小的值
return smallest_index
# 选择排序
def selectionSort(arr):
newArr = []
for i in range(len(arr)):
smallest = findSmallest(arr)
newArr.append(arr.pop(smallest))
return newArr
print selectionSort([5, 3, 6, 2, 10])三、递归
1.递归两点
递归和迭代的区别:
- 简单地说,递归是重复调用函数自身实现循环。迭代是函数内某段代码实现循环,而迭代与普通循环的区别是:循环代码中参与运算的变量同时是保存结果的变量,当前保存的结果作为下一次循环计算的初始值。
需要了解的算法实现:
- 斐波那契
- 杨辉三角
- 约瑟夫环
- 蛇形矩阵
- 汉诺塔程序
递归需要掌握的两点内容:将问题分成基线条件和递归条件这样就容易写出递归函数。
注意点:使用循环,程序的性能可能更高;如果使用递归,程序可能更容易理解。
每个递归函数都有两部分:基线条件( base case)和递归条件( recursive case) 。递归条件指的是函数调用自己,而基线条件则指的是函数不再调用自己,从而避免形成无限循环。
def countdown(i):
print i
if i <= 0: # 基线条件
return
else: # 基线条件
countdown(i-1)2.递归调用栈
递归函数调用栈举例:
def fact(x):
if x == 1:
return 1
else:
return x * fact(x-1)
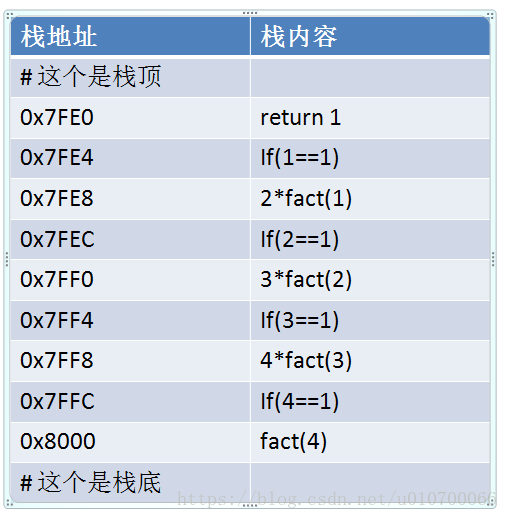
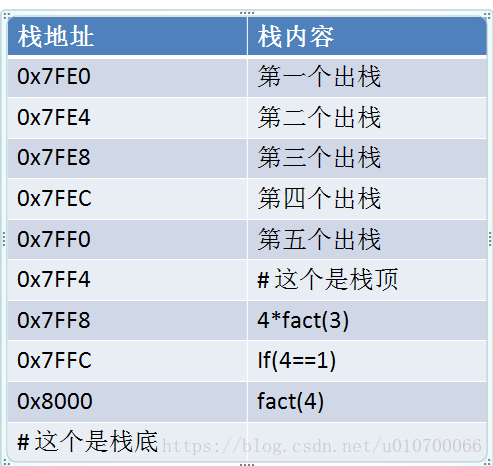
fact(4) - 执行调用栈如下图:参考链接
如下图,每次调用到fact()函数时候就会把相应的函数内容压入进栈。一直递归调用到栈的结束条件return 后没有调用;
当出现return后再依次执行出战操作;
完成入栈调用后,依次执行命令并进行出栈操作,示意图如下:
四、快速排序:分而治之
要知道经典排序算法:原理复杂度实现代码:
十大经典排序算法(动图演示) ——– 简洁易懂还有图例
(1) 找出基线条件,这种条件必须尽可能简单。
(2) 不断将问题分解(或者说缩小规模),直到符合基线条件。
对排序算法来说,最简单的数组就是根本不需要排序的数组。可以通过这个确定基线条件:
因此, 基线条件为数组为空或只包含一个元素。
代码表示如下:
def quicksort(array):
if len(array) < 2:
return array然后确定快速排序的递归条件就是不断的划分数据进行二分法分类:
def quicksort(array):
if len(array) < 2:
return array
else: #
pivot = array[0] # 递归条件,这个是每次选取数组的第一个值进行分组
less = [i for i in array[1:] if i <= pivot] # 通过函数式编程划分出比第一个小的
greater = [i for i in array[1:] if i > pivot] # 通过函数式编程划分出比第一个大的
return quicksort(less) + [pivot] + quicksort(greater) # 递归调用分组
print(quicksort([10, 5, 2, 3]))算法复杂度比较
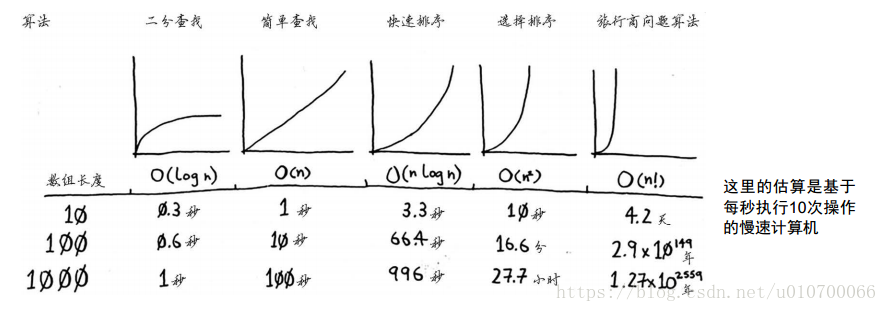
| 算法 | 算法复杂度(平均) | 举例数组长度(10,100,1000) |
|---|---|---|
| 二分查找 | O(log(N)) | 对应时间:(0.3s,0.6s,1s) |
| 简单查找(基于线性表的查找) | O(N) | 1s,10s,100s |
| 快速排序 | O(N*log(N)) | 3.3s, 66.4s, 996s |
| 选择排序 | O(N*N) | 10s,16.6min,27.7h |
| 旅行商问题算法 | O(N!) | 4.2d,2.9*10**149year,xxx年 |
五、散列表
了解散列表的两点内容:
- 最有用的基本数据结构之一。
- 散列表的内部机制:实现、冲突和散列函数。
- 散列表可能是最有用的,也被称为散列映射、映射、字典和关联数组。
1.散列函数
散列函数“将输入映射到数字”。其查找复杂度为O(1)
- 它必须是一致的。例如,假设你输入apple时得到的是4,那么每次输入apple时,得到的都
必须为4。如果不是这样,散列表将毫无用处。 - 它应将不同的输入映射到不同的数字。 例如, 如果一个散列函数不管输入是什么都返回1,
它就不是好的散列函数。最理想的情况是,将不同的输入映射到不同的数字。
散列函数准确地指出了价格的存储位置,遵循以下原则:
- 散列函数总是将同样的输入映射到相同的索引。
- 散列函数将不同的输入映射到不同的索引。
- 散列函数知道数组有多大,只返回有效的索引。
hash表实现原理介绍参考:
散列表的基本原理与实现 —对hash实现的全实现展示
从头到尾解析Hash表算法 —包含部分代码实现
深入理解数据结构之散列表、散列、散列函数 —hash实现在Java中的概览
应用:
- python中的字典,
- 缓存是一种常用的加速方式,所有大型网站都使用缓存,而缓存的数据则存储在散列表中!
2.散列冲突
给两个不同的键分配的位置相同。
最简单的办法如下:如果两个键映射到了同一个位置,就在这个位置存储一个链表。
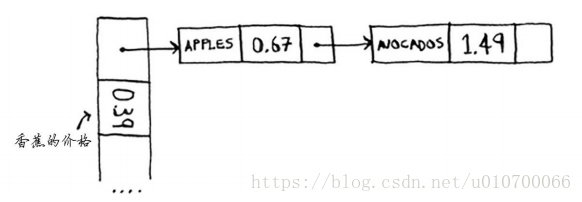
问题:如果都是以A开头那散列表就会变成了一个链表了,只在第一个存储值:
除第一个位置外,整个散列表都是空的,而第一个位置包含一个很长的列表!
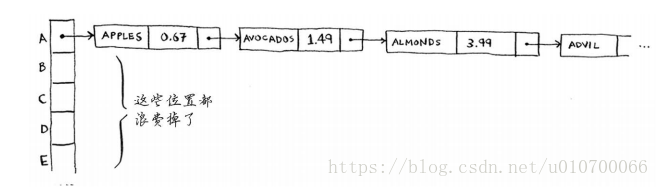
所以:散列函数很重要,好的散列函数很少导致冲突。
3.散列性能
| 操作 | 散列表(平均) | 散列表(最差) | 数组 | 链表 |
|---|---|---|---|---|
| 查找 | O(1) | O(n) | O(1) | O(n) |
| 插入 | O(1) | O(n) | O(n) | O(1) |
| 删除 | O(1) | O(n) | O(n) | O(1) |
1.在平均情况下,散列表的查找(获取给定索引处的值)速度与数组一样快,而插入和删除速度与链表一样快,因此它兼具两者的优点!但在最糟情况下,散列表的各种操作的速度都很慢。
2.在使用散列表时,避开最糟情况至关重要。
所以,散列表的良好状况有下面连点要求:SHA函数
较低的填装因子;
良好的散列函数。
一个不错的经验规则是:一旦填装因子大于0.7,就调整散列表的长度。
六、广度优先搜索
图算法——广度优先搜索(breadth-first search, BFS)
广度优先搜索应用:
- 编写国际跳棋AI,计算最少走多少步就可获胜;
- 编写拼写检查器,计算最少编辑多少个地方就可将错拼的单词改成正确的单词,如将READED改为READER需要编辑一个地方;
- 根据你的人际关系网络找到关系最近的医生
- 最短路径:
1.图简介
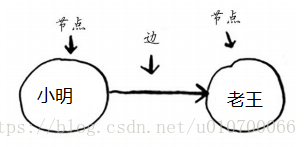
图由节点和边组成,图模拟一组连接。例如,假设你与朋友玩牌,并要模拟谁欠谁钱,可像下面这样指出小明欠老王钱。
2.队列
关系查找问题:只有按添加顺序查找时,才能实现这样的目的。有一个可实现这种目的的数据结构,那就是队列(queue)
队列的工作原理:队列是一种先进先出(First In First Out, FIFO)的数据结构,而栈是一种后进先出(Last In First Out, LIFO)的数据结构。
如果你将两个元素加入队列,先加入的元素将在后加入的元素之前出队。因此,你可使用队列来表示查找名单!
3.有向图查找的具体实现
#通过散列和列表来实现有向图结构
graph = {}
graph["you"] = ["alice", "bob", "claire"] # 相当于 you-->alice,bob,claire这三个路径
graph["bob"] = ["anuj", "peggy"]
graph["alice"] = ["peggy"]
graph["claire"] = ["thom", "jonny"]
graph["anuj"] = []
graph["peggy"] = []
graph["thom"] = []
graph["jonny"] = []Anuj、 Peggy、 Thom和Jonny都没有邻居,这是因为虽然有指向他们的箭头,但没有从他们出发指向其他人的箭头。这被称为有向图(directed graph) ,其中的关系是单向的。因此, Anuj是Bob的邻居,但Bob不是Anuj的邻居。 无向图(undirected graph)没有箭头,直接相连的节点互为邻居。
小提示:
python队列Queue —简单易懂的介绍队列
python3 deque(双向队列) —-简单介绍双向队列操作
队列(queue)原理 —简单队列原理
from collections import deque # 使用函数deque来创建一个双端队列。
search_queue = deque() # 创建一个队列
search_queue += graph["you"] # 将你的邻居都加入到这个搜索队列中
# 判断一个人是不是芒果销售商
def person_is_seller(name):
return name[-1] == 'm'
# 实现有向图查找算法
while search_queue:
person = search_queue.popleft()
if person_is_seller(person):
print person + " is a mango seller!"
return True
else:
search_queue += graph[person]
return False这个算法将不断执行,直到满足以下条件之一:
- 找到一位芒果销售商;
- 队列变成空的,这意味着你的人际关系网中没有芒果销售商。
问题: Peggy既是Alice的朋友又是Bob的朋友,因此她将被加入队列两次:一次是在添加Alice的朋友时,另一次是在添加Bob的朋友时;这也可能 导致图的无限循环进行;
因此需要对已经查询过的图对象点进行标记;检查完一个人后,应将其标记为已检查,且不再检查他。
# 优化后的代码
#!usr/bin/env python
# -*- coding:utf-8 -*-
"""
@note: # 广度优先算法
"""
from collections import deque # 使用函数deque来创建一个双端队列。
# 1。通过散列和列表来实现有向图结构
graph = {}
graph["you"] = ["alice", "bob", "claire"] # 相当于 you-->alice,bob,claire这三个路径
graph["bob"] = ["anuj", "peggy"] # 相当于 bob-->anuj,peggy这三个路径的有向图
graph["alice"] = ["peggy"]
graph["claire"] = ["thom", "jonny"]
graph["anuj"] = []
graph["peggy"] = []
graph["thom"] = []
graph["jonny"] = []
# 判断一个人是不是芒果销售商
def person_is_seller(name):
return name[-1] == 'm'
# 实现有向图查找算法
def search(name):
search_queue = deque() # 创建一个队列
search_queue += graph[name] # 通过给定name开始进行有向图深度搜索
searched = [] # 这个列表用于记录检查过的人
while search_queue: # 只要队列不为空
person = search_queue.popleft() # 就取出其中的第一个人
if not person in searched: # 仅当这个人没检查过 才进行检查
if person_is_seller(person): # 检查这个人是否是芒果销售商
print(person + " is a mango seller!")
return True
else:
search_queue += graph[person] # 不是芒果销售商。将这个人的朋友都加入搜索队列
searched.append(person) # 将这个人标记为检查过
return False # 如果到达了这里,就说明队列中没人是芒果销售商
search("you")通过执行debug模式可以看到队列中不停的加入:
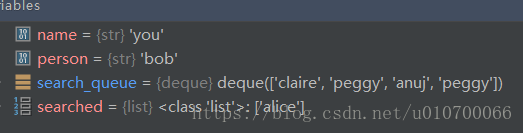
将一个人添加到队列需要的时间是固定的,即为O(1),因此对每个人都这样做需要的总时间为O(人数)。所以,广度优先搜索的运行时间为O(人数 + 边数),这通常写作O(V + E),其中V为顶点(vertice)数, E为边数。
注意点:
如果任务A依赖于任务B,在列表中任务A就必须在任务B后面。这被称为拓扑排序,使用它可根据图创建一个有序列表。
你需要按加入顺序检查搜索列表中的人,否则找到的就不是最短路径,因此搜索列表必须是队列。
对于检查过的人,务必不要再去检查,否则可能导致无限循环。
七、狄克斯特拉算法-加权图
Dijkstra’s algorithm
找出加权图中前往X的最短路径。只能求得从一个单个起始点,到单个结束点的最短路径;
参考链接:Dijkstra’s Algorithm - Computerphile – B站上讲解清晰的视频,一共两个视频,各有优点
1.狄克斯特拉算法4个步骤:
(1) 找出“最便宜”的节点,即可在最短时间内到达的节点。
(2) 更新该节点的邻居的开销,其含义将稍后介绍。
(3) 重复这个过程,直到对图中的每个节点都这样做了。
(4) 计算最终路径。
注意点: 不能将狄克斯特拉算法用于包含负权边的图。
对于负权边使用贝尔曼·福德算法( Bellman-Fordalgorithm)
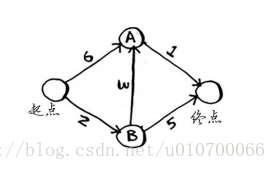
权重距离:达到这个节点的权重值
父节点:通过哪个上一节点达到这个节点的
1.第一次从S(start,起点)开始
| 路径点 | S(start) | A | B | E(end) |
|---|---|---|---|---|
| 权重距离 | 0 | 6 | 2 | ∞ |
| 父节点 | s | s | s | - |
1.第二次从B节点开始:因为从第一次选择可以看到,B权重距离最小。所以选择B作为第二次起始点。对于已经完成的不进行从新划分。
| 路径点 | S(start) | A | B | E(end) |
|---|---|---|---|---|
| 权重距离 | 0 | 5 | 2 | 5 |
| 父节点 | s | B | s | B |
就这样依次查找更新。最终实现完成;
2.代码实现
#! user/bin/env python
# -*- encoding:utf-8 -*-
"""
@time: 2018/07/03 23:01
@note:狄克斯特拉算法实现
"""
graph = {} # 一个散列表,将所有邻居都存储在散列表中
graph["start"] = {} # 使用另一个散列表,表示这些边的权重
graph["start"]["a"] = 6
graph["start"]["b"] = 2
graph["a"] = {} # 添加其他节点及其邻居
graph["a"]["fin"] = 1
graph["b"] = {}
graph["b"]["a"] = 3
graph["b"]["fin"] = 5 # 终点没有任何邻居
# 用一个散列表来存储每个节点的开销
infinity = float("inf")
costs = {}
costs["a"] = 6
costs["b"] = 2
costs["fin"] = infinity
# 一个存储父节点的散列表
parents = {}
parents["a"] = "start"
parents["b"] = "start"
parents["fin"] = None
processed = [] # 用于记录处理过的节点,因为对于同一个节点,不能处理多次
def find_lowest_cost_node(costs):
lowest_cost = float("inf")
lowest_cost_node = None
for node in costs: # 遍历所有的节点
cost = costs[node]
# 如果当前节点的开销更低且未处理过,就将其视为开销最低的节点
if cost < lowest_cost and node not in processed:
lowest_cost = cost
lowest_cost_node = node
return lowest_cost_node
# 在未处理的节点中找出开销最小的节点
node = find_lowest_cost_node(costs)
while node is not None: # 这个while循环在所有节点都被处理过后结束
cost = costs[node]
neighbors = graph[node] # 这个地方需要判断如node为 fin 时结束
for n in neighbors.keys(): # 遍历当前节点的所有邻居
new_cost = cost + neighbors[n]
if costs[n] > new_cost:
# 如果经当前节点前往该邻居更近,就更新该邻居的开销
costs[n] = new_cost
# 将该邻居的父节点设置为当前节点
parents[n] = node
processed.append(node) # # 将当前节点标记为处理过
node = find_lowest_cost_node(costs) # 找出接下来要处理的节点,并循环小总结:
广度优先搜索用于在非加权图中查找最短路径。
狄克斯特拉算法用于在加权图中查找最短路径。
仅当权重为正时狄克斯特拉算法才管用。
如果图中包含负权边,请使用贝尔曼·福德算法
最短路径指的并不一定是物理距离,也可能是让某种度量指标最小。
扩展知识:距离的定义建议看:距离定理:距离满足三角不等式
可以参考:《Generalized inverses: theory and computations》Guorong Wang, Yimin Wei.的27页找到
知乎:为什么距离(度量)要满足三角不等式?
根据欧式空间的性质以及(Cauchy—Schwarz不等式)证明
八、贪婪算法
1.实现原理:贪婪算法很简单:每步都采取最优的做法
- 应用:处理不可能完成的任务:没有快速算法的问题(NP完全问题)
- 识别NP完全问题,以免浪费时间去寻找解决它们的快速算法
- 近似算法,使用它们可快速找到NP完全问题的近似解
- 贪婪策略——一种非常简单的问题解决策略
- NP问题,NP难问题,NP全问题
2.具体实现
例子:假设你办了个广播节目,要让全美50个州的听众都收听得到。为此,你需要决定在哪些广播台播出。在每个广播台播出都需要支付费用,因此你力图在尽可能少的广播台播出。现有广播台名单如下:
| 广播合 | 覆盖州 |
|---|---|
| KONE | ID,NV,UT |
| KTWO | WA,ID,MT |
| KTHREE | PR.MV.CA |
| KFOUR | NV,UT |
| KFIVE | CA,AZ |
最好使用如下算法:
近似算法
贪婪算法可化解危机!使用下面的贪婪算法可得到非常接近的解。
(1) 选出这样一个广播台,即它覆盖了最多的未覆盖州。即便这个广播台覆盖了一些已覆盖
的州,也没有关系。
(2) 重复第一步,直到覆盖了所有的州。
这是一种近似算法(approximation algorithm) 。在获得精确解需要的时间太长时,可使用近
似算法。判断近似算法优劣的标准如下:
- 速度有多快;
- 得到的近似解与最优解的接近程度。
- 贪婪算法是不错的选择,它们不仅简单,而且通常运行速度很快。
- 在这个例子中,贪婪算法的运行时间为O(n2),其中n为广播台数量。
代码实现
#!usr/bin/env python
# -*- coding:utf-8 -*-
"""
@time: 2018/07/04 12:35
@software:diagramalgorithm
@note: 贪婪算法实现
"""
states_needed = set(["mt", "wa", "or", "id", "nv", "ut","ca", "az"]) # 你传入一个数组,它被转换为集合
# 可供选择的广播台清单,使用散列表来表示
stations = {}
stations["kone"] = set(["id", "nv", "ut"])
stations["ktwo"] = set(["wa", "id", "mt"])
stations["kthree"] = set(["or", "nv", "ca"])
stations["kfour"] = set(["nv", "ut"])
stations["kfive"] = set(["ca", "az"])
# 存储最终选择的广播台
final_stations = set()
best_station = None
states_covered = set()
while states_needed:
for station, states_for_station in stations.items():
covered = states_needed & states_for_station
if len(covered) > len(states_covered): # 计算交集
best_station = station
states_covered = covered
final_stations.add(best_station)
states_needed -= states_covered
print(final_stations)
3.如何识别 NP 完全问题
- 元素较少时算法的运行速度非常快,但随着元素数量的增加,速度会变得非常慢。
- 涉及“所有组合”的问题通常是NP完全问题。
- 不能将问题分成小问题,必须考虑各种可能的情况。这可能是NP完全问题。
- 如果问题涉及序列(如旅行商问题中的城市序列)且难以解决,它可能就是NP完全问题。
- 如果问题涉及集合(如广播台集合)且难以解决,它可能就是NP完全问题。
- 如果问题可转换为集合覆盖问题或旅行商问题,那它肯定是NP完全问题。
九、动态规划
1.实现原理
动态规划,这是一种解决棘手问题的方法,它将问题分成小问题,并先着手解决这些小问题。
例子:背包问题
对于背包问题,你先解决小背包(子背包)问题,再逐步解决原来的问题。
其实将背包的单位更小化,并把物品计量单位化;这样转化为一个计数问题。
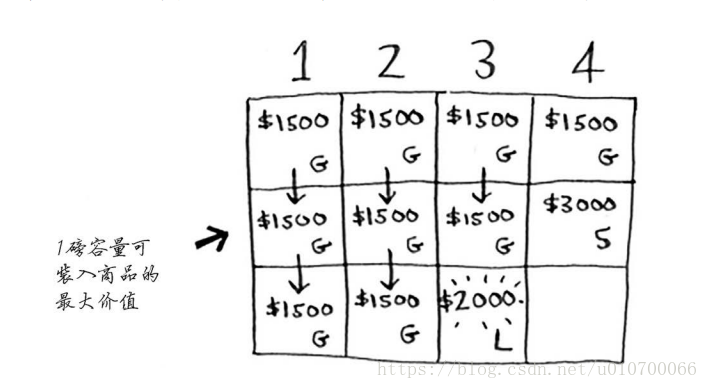
实现上述算法的原理:使用这个公式来计算每个单元格的价值,最终的网格将与前一个网格相同。
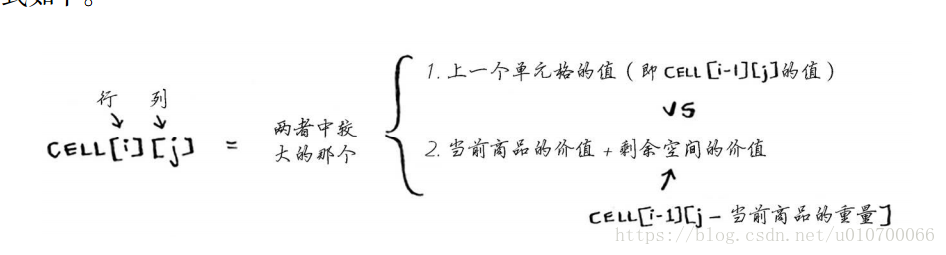
2.对于部分商品获取问题
假设你在杂货店行窃,可偷成袋的扁豆和大米,但如果整袋装不下,可打开包装,再将背包倒满。在这种情况下,不再是要么偷要么不偷,而是可偷商品的一部分。如何使用动态规划来处理这种情形呢?
&&&答案是没法处理。
- 使用动态规划时,要么考虑拿走整件商品,要么考虑不拿,而没法判断该不该拿走商品的一部分。
- 使用贪婪算法可轻松地处理这种情况!首先,尽可能多地拿价值最高的商品;如果拿光了,再尽可能多地拿价值次高的商品,以此类推。
小提示:动态规划功能强大,它能够解决子问题并使用这些答案来解决大问题。 但仅当每个子问题都是离散的,即不依赖于其他子问题时,动态规划才管用。
3.最长公共子串
- 动态规划可帮助你在给定约束条件下找到最优解。 动态规划可帮助你在给定约束条件下找到最优解。
- 在问题可分解为彼此独立且离散的子问题时,就可使用动态规划来解决。
- 每种动态规划解决方案都涉及网格。
- 单元格中的值通常就是你要优化的值。在前面的背包问题中,单元格的值为商品的价值
**每个单元格都是一个子问题,因此你应考虑如何将问题分成子问题,这有助于你找出网
格的坐标轴。**- 生物学家根据最长公共序列来确定DNA链的相似性,进而判断度两种动物或疾病有多相
似。最长公共序列还被用来寻找多发性硬化症治疗方案。 - 你使用过诸如git diff等命令吗?它们指出两个文件的差异,也是使用动态规划实现的。
- 前面讨论了字符串的相似程度。 编辑距离(levenshtein distance)指出了两个字符串的相
似程度,也是使用动态规划计算得到的。编辑距离算法的用途很多,从拼写检查到判断
用户上传的资料是否是盗版,都在其中。 - 你使用过诸如Microsoft Word等具有断字功能的应用程序吗?它们如何确定在什么地方断
字以确保行长一致呢?使用动态规划!
- 生物学家根据最长公共序列来确定DNA链的相似性,进而判断度两种动物或疾病有多相
最后的小碎片
1.第10章 KNN算法单独写
2.11章内容关注点在这小碎片一下
1.树:
- 二叉查找树中查找节点时,平均运行时间为O(log n),但在最糟的情况下所需时间为O(n);而在有序数组中查找时,即便是在最糟情况下所需的时间也只有O(log n),因此你可能认为有序数组比二叉查找树更佳。然而,二叉查找树的插入和删除操作的速度要快得多。
- 二叉查找树也存在一些缺点,例如,不能随机访
- B树是一种特殊的二叉树,数据库常用它来存储数据。还有的数据结构: B树,红黑树,堆,伸展树
2.反向索引
- 正常情况:散列表的键为页面地址,值为包含的单词内容。
- 反向索引(inverted index)散列表的键为单词,值为包含指定单词的页面。
- 一个散列表,将单词映射到包含它的页面。这种数据结构被称为反向索引(inverted index),常用于创建搜索引擎。
3.傅里叶变换
- 一个绝佳的比喻:给它一杯冰沙,它能告诉你其中包含哪些成分;
- 给定一首歌曲,傅里叶变换能够将其中的各种频率分离出来;
4.MapReduce
- 分布式算法非常适合用于在短时间内完成海量工作,其中的MapReduce基于两个简单的理念:映射(map)函数和归并(reduce)函数。
- 映射函数:如果有100台计算机,而map能够自动将工作分配给这些计算机去完成
- 归并函数:归并函数可能令人迷惑,其理念是将很多项归并为一项。映射是将一个数组转换为另一个数组。而归并是将一个数组转换为一个元素
5.SHA 算法secure hash algorithm, SHA
- SHA还让你能在不知道原始字符串的情况下对其进行比较。
- SHA实际上是一系列算法: SHA-0、 SHA-1、 SHA-2和SHA-3
- 当前,最安全的密码散列函数是bcrypt
- 局部敏感的散列算法:Simhash
- Diffie-Hellman密钥交换:Diffie-Hellman使用两个密钥:公钥和私钥。
- Diffie-Hellman算法及其替代者RSA依然被广泛使用。如果你对加密感兴趣,先着手研究Diffie-Hellman算法是不错的选择:它既优雅又不难理解。
6.线性规划
- 线性规划用于在给定约束条件下最大限度地改善指定的指标。
- 线性规划使用Simplex算法
- 如果你对最优化感兴趣,就研究研究线性规划