一、前述
Python上著名的⾃然语⾔处理库⾃带语料库,词性分类库⾃带分类,分词,等等功能强⼤的社区⽀持,还有N多的简单版wrapper。
二、文本预处理
1、安装nltk
pip install -U nltk
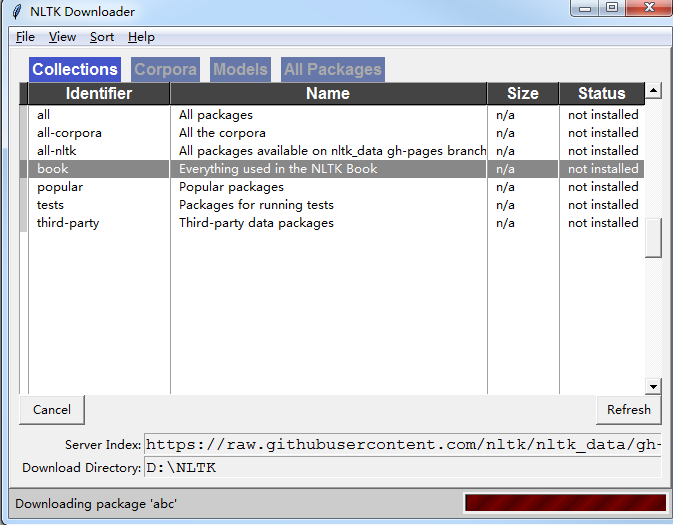
安装语料库 (一堆对话,一对模型)
import nltk nltk.download()
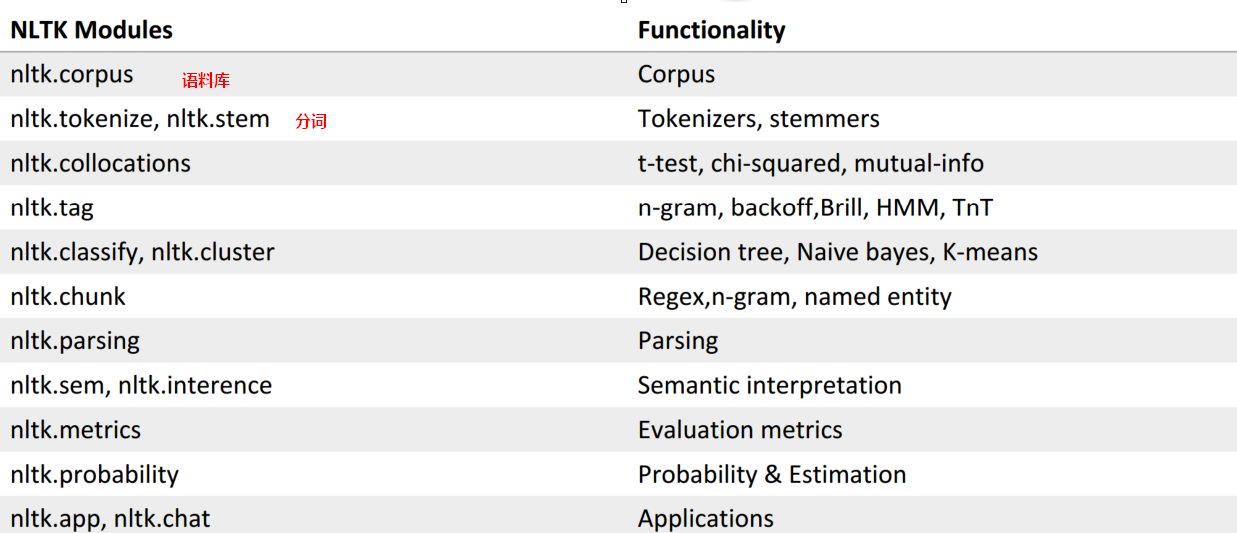
2、功能一览表:
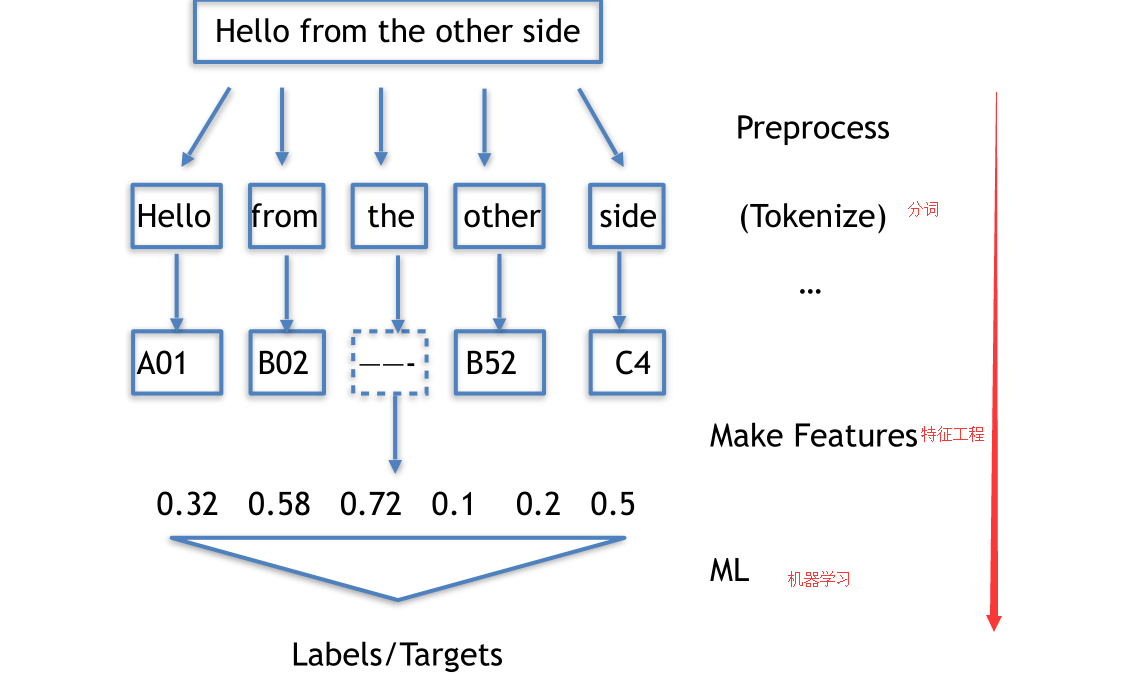
3、文本处理流程
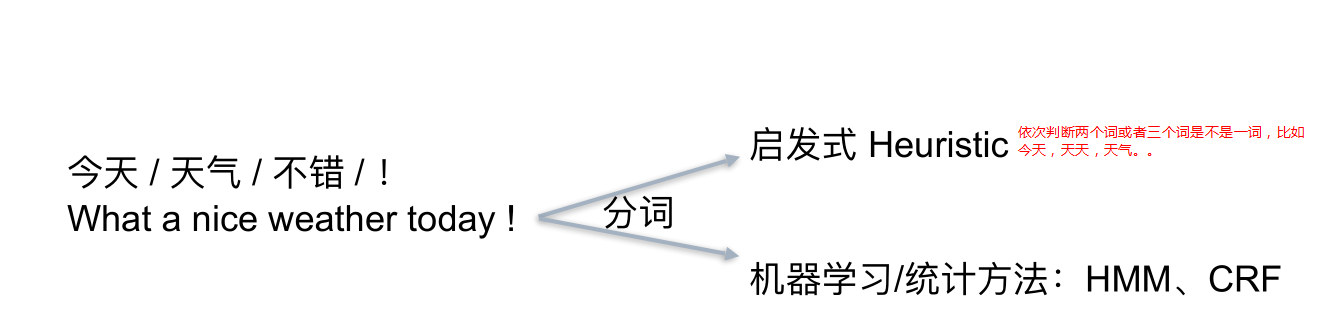
4、Tokenize 把长句⼦拆成有“意义”的⼩部件
import jieba seg_list = jieba.cut("我来到北北京清华⼤大学", cut_all=True) print "Full Mode:", "/ ".join(seg_list) # 全模式 seg_list = jieba.cut("我来到北北京清华⼤大学", cut_all=False) print "Default Mode:", "/ ".join(seg_list) # 精确模式 seg_list = jieba.cut("他来到了了⽹网易易杭研⼤大厦") # 默认是精确模式 print ", ".join(seg_list) seg_list = jieba.cut_for_search("⼩小明硕⼠士毕业于中国科学院计算所,后在⽇日本京都⼤大学深造") # 搜索引擎模式 print ", ".join(seg_list)
结果:
【全模式】: 我/ 来到/ 北北京/ 清华/ 清华⼤大学/ 华⼤大/ ⼤大学 【精确模式】: 我/ 来到/ 北北京/ 清华⼤大学 【新词识别】:他, 来到, 了了, ⽹网易易, 杭研, ⼤大厦 (此处,“杭研”并没有在词典中,但是也被Viterbi算法识别出来了了) 【搜索引擎模式】: ⼩小明, 硕⼠士, 毕业, 于, 中国, 科学, 学院, 科学院, 中国科学院, 计算, 计算所, 后, 在, ⽇日本, 京都, ⼤大学, ⽇日本京都⼤大学, 深造
社交⽹络语⾔的tokenize:
import re emoticons_str = r""" (?: [:=;] # 眼睛 [oO\-]? # ⿐鼻⼦子 [D\)\]\(\]/\\OpP] # 嘴 )""" regex_str = [ emoticons_str, r'<[^>]+>', # HTML tags r'(?:@[\w_]+)', # @某⼈人 r"(?:\#+[\w_]+[\w\'_\-]*[\w_]+)", # 话题标签 r'http[s]?://(?:[a-z]|[0-9]|[$-_@.&+]|[!*\(\),]|(?:%[0-9a-f][0-9a-f]))+', # URLs r'(?:(?:\d+,?)+(?:\.?\d+)?)', # 数字 r"(?:[a-z][a-z'\-_]+[a-z])", # 含有 - 和 ‘ 的单词 r'(?:[\w_]+)', # 其他 r'(?:\S)' # 其他 ]
正则表达式对照表
http://www.regexlab.com/zh/regref.htm
这样能处理社交语言中的表情等符号:
tokens_re = re.compile(r'('+'|'.join(regex_str)+')', re.VERBOSE | re.IGNORECASE) emoticon_re = re.compile(r'^'+emoticons_str+'$', re.VERBOSE | re.IGNORECASE) def tokenize(s): return tokens_re.findall(s) def preprocess(s, lowercase=False): tokens = tokenize(s) if lowercase: tokens = [token if emoticon_re.search(token) else token.lower() for token in tokens] return tokens tweet = 'RT @angelababy: love you baby! :D http://ah.love #168cm' print(preprocess(tweet)) # ['RT', '@angelababy', ':', 'love', 'you', 'baby', # ’!', ':D', 'http://ah.love', '#168cm']
5、词形归⼀化
Stemming 词⼲提取:⼀般来说,就是把不影响词性的inflection的⼩尾巴砍掉
walking 砍ing = walk
walked 砍ed = walk
Lemmatization 词形归⼀:把各种类型的词的变形,都归为⼀个形式
went 归⼀ = go
are 归⼀ = be
>>> from nltk.stem.porter import PorterStemmer >>> porter_stemmer = PorterStemmer() >>> porter_stemmer.stem(‘maximum’) u’maximum’ >>> porter_stemmer.stem(‘presumably’) u’presum’ >>> porter_stemmer.stem(‘multiply’) u’multipli’ >>> porter_stemmer.stem(‘provision’) u’provis’ >>> from nltk.stem import SnowballStemmer >>> snowball_stemmer = SnowballStemmer(“english”) >>> snowball_stemmer.stem(‘maximum’) u’maximum’ >>> snowball_stemmer.stem(‘presumably’) u’presum’ >>> from nltk.stem.lancaster import LancasterStemmer >>> lancaster_stemmer = LancasterStemmer() >>> lancaster_stemmer.stem(‘maximum’) ‘maxim’ >>> lancaster_stemmer.stem(‘presumably’) ‘presum’ >>> lancaster_stemmer.stem(‘presumably’) ‘presum’ >>> from nltk.stem.porter import PorterStemmer >>> p = PorterStemmer() >>> p.stem('went') 'went' >>> p.stem('wenting') 'went'
6、词性Part-Of-Speech
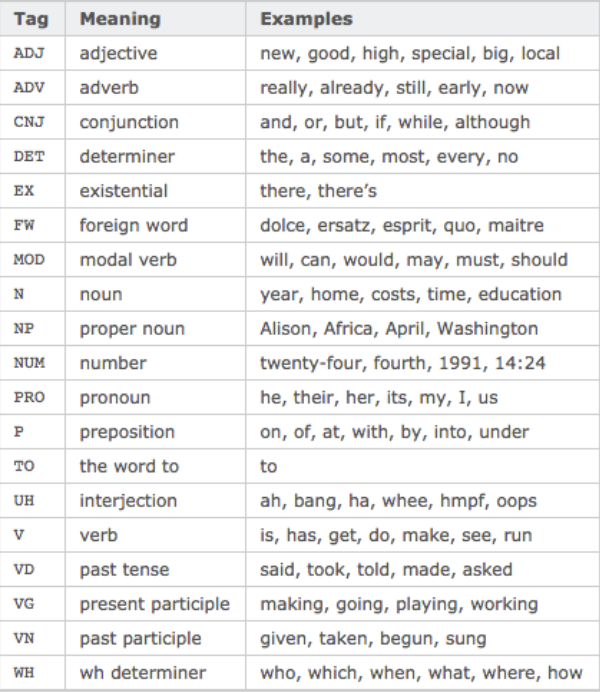
>>> import nltk >>> text = nltk.word_tokenize('what does the fox say') >>> text ['what', 'does', 'the', 'fox', 'say'] >>> nltk.pos_tag(text) [('what', 'WDT'), ('does', 'VBZ'), ('the', 'DT'), ('fox', 'NNS'), ('say', 'VBP')]
7、Stopwords
⾸先记得在console⾥⾯下载⼀下词库
或者 nltk.download(‘stopwords’)
from nltk.corpus import stopwords # 先token⼀一把,得到⼀一个word_list # ... # 然后filter⼀一把 filtered_words = [word for word in word_list if word not in stopwords.words('english')]
8、⼀条⽂本预处理流⽔线
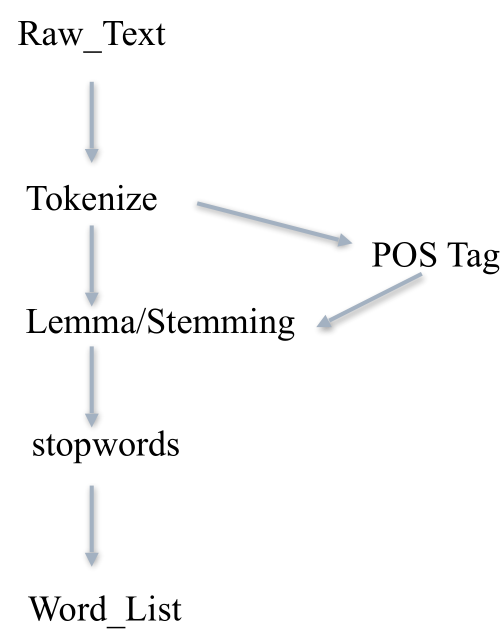
三、自然语言处理应用。
实际上预处理就是将文本转换为Word_List,自然语言处理再转变成计算机能识别的语言。
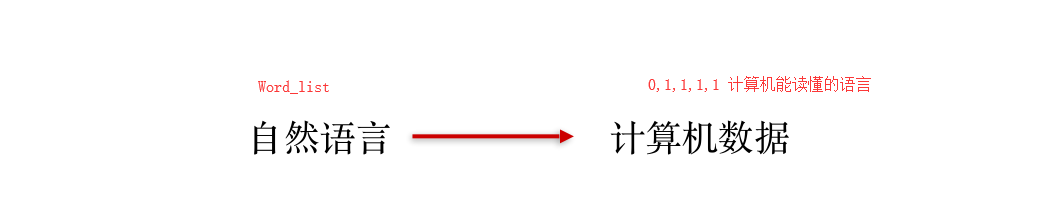
自然语言处理有以下几个应用:情感分析,⽂本相似度, ⽂本分类