一、nltk库
nltk是一个python工具包, 用来处理与自然语言相关的东西. 包括分词(tokenize), 词性标注(POS), 文本分类等,是较为好用的现成工具。但是目前该工具包的分词模块,只支持英文分词,而不支持中文分词。
1.安装nltk库
在命令行输入:
conda install nltk #anaconda环境
pip install nltk #纯python环境进入对应的环境中,输入如下:
import nltk
nltk.download()运行后,弹出NLTK Downloader窗口,自定义安装内容 (博主选择all ,即全部安装,大概3.2G左右) ,安装成功如下图所示:
2.nltk库的使用方法
(1)学习资料
【参考文章】
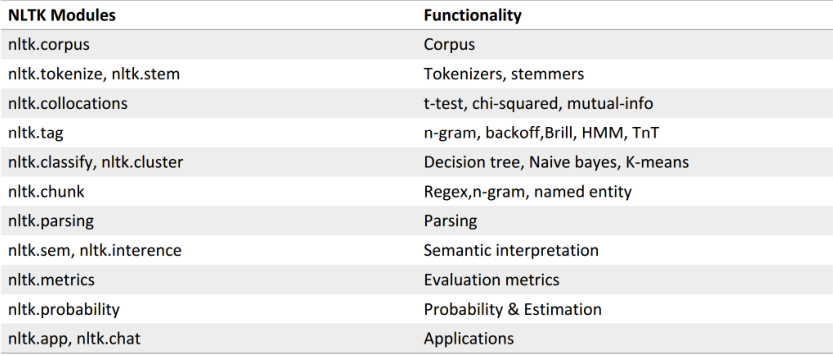
【nltk功能模块】如下图
(2)nltk载入本地中文语料库的两种方法+TF_IDF计算
【nltk载入语料库】
【注】txt文件为使用如jieba等中文分词包分词后
comment4.txt内容如下:
从 下单 到手 只用 了 3 个 多 小时 , 真快 啊 , 赞 一下 京东 的 配送 速度 , 机子 收到 是 原封 的 , 深圳 产 , 没有 阴阳 屏 和 跑马灯 , 还 不错 , 三星 的 U , 但 不 纠结 , 也 没有 感觉 有 多 费电 , 激活 后 买 了 ac + , 可以 随意 裸机 体验 了 , 整体 来说 很 满意comment5.txt内容如下:
使用 了 一周 多才 来 评价 优化 过后 开机 10 秒左右 运行 不卡顿 屏幕 清晰 无 漏光 巧克力 键盘 触感 非常 不错 音质 也 很 好 外观 漂亮 质量 轻巧 尤其 值得称赞 的 是 其 散热 系统 我 玩 LOL 三四个 小时 完全 没有 发烫 暂时 没有 发现 什么 缺点 如果 有 光驱 就 更好 了 值得 入手 值得 入手 值得 入手 ~ 不 枉费 我 浪费 了 12 期 免息 券加 首单 减免 * 的 优惠 最后 换 了 这台 适合 办公 的 之前 是 买 的 惠普 的 暗夜精灵 玩游戏 超棒 的①【推荐】法一:PlaintextCorpusReader【适合文本文件】
from nltk.corpus import PlaintextCorpusReader
#corpus_root = 'D://Data//nltk_data//CorpusData' #//不会产生转义 【语料库路径】
corpus_root = r"D:\Data\nltk_data\CorpusData" #r""防止转义 【语料库路径】
file_pattern=['comment4.txt','comment5.txt'] #【txt文件名】
pcrText = PlaintextCorpusReader(corpus_root,file_pattern) #nltk的本地语料库加载方法
pcrText.fileids() #输出目录下所有文件名
pcrText.words('comment4.txt')结果如下:
②法二:BracketParseCorpusReader【适合已解析过的语料库】
from nltk.corpus import BracketParseCorpusReader
#corpus_root = 'D://Data//nltk_data//CorpusData' #//不会产生转义 【语料库路径】
corpus_root = r"D:\Data\nltk_data\CorpusData" #r""防止转义 【语料库路径】
file_pattern =r"comment.*txt" #匹配corpus_root目录下的所有txt文件
bcrText = BracketParseCorpusReader(corpus_root, file_pattern) #初始化读取器:语料库目录和要加载文件的格式,默认utf8格式的编码
bcrText.fileids() #输出目录下所有文件名
bcrText.raw('comment4.txt')
结果如下:

【注】建议编码:txt预存为utf8编码(输入) ——> unicode(处理) ——> utf8(输出)
Python3.x默认为unicode编码,Python2.x则需decode解码为unicode
【TF_IDF计算】
对于上述txt文本存放的用户评论,文本中某个词对文本的重要性越高,它的TF-IDF值就越大。同理,评论的某个词TF_IDF值越高,则该词对于这条评论的重要性越大。
from nltk.text import TextCollection
#sinica_text = nltk.Text(pcrText.words()) #pcrText.words()返回所加载文档的所有词汇
sinica_text = nltk.Text(pcrText.words('comment4.txt')) #pcrText.words()返回comment4.txt的所有词汇
mytexts = TextCollection(pcrText) #TextCollection()用于返回一个文档集合
len(mytexts._texts) #表示文档集合里面包含的文档个数
len(mytexts) #表示文档集合里面包含的词汇个数
the_set = set(sinica_text) #去除文档中重复的词汇,从而形成词汇表。
len(the_set)
for tmp in the_set:
print(tmp, "【tf】", mytexts.tf(tmp, pcrText.raw(['comment4.txt'])), "【idf】", mytexts.idf(tmp),"【tf_idf】", mytexts.tf_idf(tmp, pcrText.raw(['comment4.txt'])))
#pcrText.raw(['comment4.txt'])用于返回对应文章的所有内容,以便计算tf和tf_idf值。
#通过tf,idf,tf_idf这三个函数来计算每个词汇在语料库以及对应文章中的值comment4.txt文本

comment4.txt 部分TF_IDF计算结果如下:

(3)常用方法介绍
常用方法包括:
①similar:用来识别文章中和搜索词相似的词语,可以用在搜索引擎中的相关度识别功能中。
②common_contexts:用来识别2个关键词相似的词语。
③generate:用来自动生成文章
④len:可以用于判断重复词密度
⑤count:可以用于判断关键词密度。