写在开头
自然语言处理(NLP)是计算机科学领域中备受关注的分支,旨在使计算机能够理解、解释、生成人类语言,实现更自然的人机交互。本篇博客将深入介绍NLP的基础知识,并结合Python中常用的库进行实际操作,帮助读者更好地理解和应用NLP。
1. 介绍自然语言处理的基本概念
自然语言处理(NLP)是一门计算机科学领域的交叉学科,致力于使计算机能够理解、解释、生成人类语言。在这一领域,计算机被赋予了处理和分析文本数据的能力,从而能够执行各种语言相关的任务。
1.1 NLP的核心目标
NLP的核心目标是使计算机能够处理和理解人类语言,实现对语言数据的深层次理解。这涉及到对语法、语义、上下文等多个层面的处理,使计算机能够像人类一样有效地使用语言进行沟通和理解。
1.2 常见的NLP任务
在实现核心目标的过程中,NLP涵盖了多个任务和应用领域,其中一些常见的任务包括:
-
文本分类:
- 文本分类是将文本数据划分为不同的类别或标签的任务。常见的应用包括垃圾邮件过滤、新闻分类、情感分析等。例如,判断一封电子邮件是垃圾邮件还是正常邮件。
-
情感分析:
- 情感分析旨在确定文本中的情感倾向,通常分为正面、负面和中性。这在社交媒体监测、产品评论分析等领域中得到广泛应用。例如,分析用户在社交媒体上的评论对某个产品的情感态度。
-
命名实体识别(NER):
- 命名实体识别是从文本中识别出具体实体的任务,如人名、地名、组织机构等。在信息提取和知识图谱构建中有重要应用。例如,从一篇新闻文章中提取出人物、地点和组织的信息。
-
机器翻译:
- 机器翻译旨在将一种语言的文本翻译成另一种语言,促进跨语言交流。这在国际交流、跨文化合作中起到关键作用。例如,将英语文本翻译成中文或反之。
-
语音识别:
- 语音识别将口头语言转换为文本,使得计算机能够理解并处理语音输入。这在语音助手、语音搜索等方面得到广泛应用。例如,智能手机上的语音助手能够理解用户的语音指令。
-
文本生成:
- 文本生成涉及生成具有一定语法和语义的文本。这在自动摘要、文章创作、对话系统中都有应用。例如,自动生成新闻摘要或创建对话中的回复。
1.3 应用场景详细介绍
1.3.1 医疗保健
数据收集:
- 医学文献: 收集大量的医学文献和研究论文,包括疾病诊断、治疗方法等。
- 患者病历: 包括患者的病史、症状、诊断结果等详细信息。
- 生物医学数据: 如基因组数据、影像数据等。
应用:
- 利用NLP技术解析医学文献,提取新的医疗知识。
- 通过分析患者病历,辅助医生进行诊断和制定治疗方案。
- 结合生物医学数据,进行个性化医疗的研究和实践。
1.3.2 金融领域
数据收集:
- 财经新闻: 收集涉及金融市场、公司业绩等方面的新闻报道。
- 市场数据: 股票价格、交易量等相关市场数据。
- 社交媒体数据: 分析投资者情绪和市场热度。
应用:
- 通过NLP技术分析财经新闻,预测市场趋势和公司业绩。
- 结合市场数据,进行风险评估和投资决策。
- 利用社交媒体数据,监测市场情绪,辅助制定投资策略。
1.3.3 教育领域
数据收集:
- 学生学习数据: 包括学习进度、答题情况等学生学习行为数据。
- 教材和课程内容: 收集教材和课程相关的文本数据。
- 学生反馈: 收集学生对教学的评价和建议。
应用:
- 利用学生学习数据,进行个性化教学,提供定制化的学习计划。
- 分析教材和课程内容,优化教学资源和方法。
- 结合学生反馈,改进教学质量,提高学生满意度。
1.3.4 社交媒体分析
数据收集:
- 用户评论和帖子: 收集社交媒体上用户发布的评论和帖子。
- 用户信息: 用户的基本信息和社交关系。
- 趋势和热门话题: 收集社交媒体上的热门话题和用户关注的趋势。
应用:
- 通过分析用户评论和帖子,了解用户对产品或事件的反馈和情感倾向。
- 利用用户信息,进行个性化推荐和定向营销。
- 分析趋势和热门话题,指导品牌监测和社交媒体营销策略。
这些只是NLP领域众多任务和应用的冰山一角,随着技术的不断发展,NLP在更多领域将发挥更为深远的作用。
2. Python中常用的自然语言处理库简介
在Python中,有多个强大的NLP库可供选择,每个都具有不同的特点和优势。以下是常用的库:
2.1 NLTK (Natural Language Toolkit)
简介:
NLTK是一个强大的自然语言处理工具包,具有丰富的文本处理和分析功能。它包含了大量的语料库、预训练模型和处理工具,适用于教学、研究和实际应用。
特点:
- 提供了多种文本处理工具,如分词、词性标注、命名实体识别等。
- 包含丰富的语料库,可用于模型训练和实验。
- 支持文本分类、情感分析等高级任务。
安装:
pip install nltk
官方网站: NLTK
2.2 Spacy
简介:
Spacy是一个专注于性能和易用性的NLP库。它以处理速度快、内存占用低为特点,适用于大规模文本处理。Spacy提供了强大的实体识别、词性标注等功能。
特点:
- 高度优化的实体识别和词性标注功能。
- 内置了多语言模型,支持多语言文本处理。
- 适用于大规模文本数据的高性能处理。
安装:
pip install spacy
官方网站: Spacy
2.3 Transformers
简介:
Transformers(Hugging Face Transformers)是一个提供预训练模型和自然语言处理工具的库。它汇集了各种先进的NLP模型,如BERT、GPT等。
特点:
- 提供了大量预训练的NLP模型,可直接应用于各种任务。
- 灵活的API,方便用户使用和定制。
- 面向未来发展,支持多语言和多任务学习。
安装:
pip install transformers
官方网站: Transformers
2.4 TextBlob
简介:
TextBlob是一个简单易用的自然语言处理库,基于NLTK和其他工具构建。它提供了一系列简单而强大的API,使得文本处理变得更加容易。
特点:
- 简单的API,适合初学者和快速原型开发。
- 支持常见的NLP任务,如分词、词性标注、情感分析等。
- 内置词汇数据库和语料库。
安装:
pip install textblob
官方网站: TextBlob
2.5 Gensim
简介:
Gensim是一个用于主题建模和文档相似度分析的库,也可以用于词向量表示。它提供了高效的文本处理算法,特别适用于大规模语料库。
特点:
- 支持词向量表示和相似度计算。
- 提供了用于主题建模的工具,如Latent Semantic Analysis(LSA)和Latent Dirichlet Allocation(LDA)。
- 适用于大规模文本数据的处理。
安装:
pip install gensim
官方网站: Gensim
2.6 Textacy
简介:
Textacy是建立在spaCy之上的高级文本处理库,专注于提供方便、一致且可扩展的API,用于处理大规模文本数据。
特点:
- 提供了一系列用于文本处理和分析的高级功能。
- 集成了spaCy的强大的词性标注、命名实体识别等功能。
- 支持关键短语提取、主题建模等高级任务。
安装:
pip install textacy
官方网站: Textacy
2.7 HanLP
简介:
HanLP是面向中文的自然语言处理工具包,提供了丰富的中文分词、词性标注、命名实体识别等功能。
特点:
- 针对中文文本提供了全面的NLP处理功能。
- 支持多种中文分词算法,适应不同场景的需求。
- 集成了预训练模型,提供了高性能的中文NLP处理。
安装:
pip install hanlp
官方网站: HanLP
2.8 FastText
简介:
FastText是由Facebook AI Research开发的库,旨在快速学习文本表示。它支持文本分类、文本表示等任务。
特点:
- 使用N-gram和负采样等技术提高训练速度。
- 提供了预训练的词向量模型,适用于多种语言。
- 支持文本分类、文本聚类等任务。
安装:
pip install fasttext
官方网站: FastText
3. 文本分词、词性标注、命名实体识别的基础操作
在自然语言处理中,文本分词、词性标注和命名实体识别是最基础且常用的任务之一。以下将详细展开这三个基础操作的实际操作。
3.1 文本分词
文本分词是将一段文本切分成一个个有意义的词语或标记的过程。在NLP中,分词是很多任务的第一步,影响着后续任务的进行。使用NLTK库进行文本分词的实例:
import nltk
nltk.download('punkt')
from nltk.tokenize import word_tokenize
text = "Natural Language Processing is fascinating!"
tokens = word_tokenize(text)
print("NLTK Tokenization:", tokens)
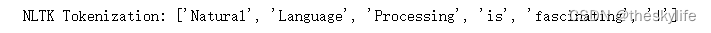
在这个例子中,我们使用NLTK的word_tokenize函数对给定的文本进行了分词。分词的结果是一个包含了每个词语的列表。
而对于中文分词来说,结巴分词是中文领域最常用的分词工具之一,使用jieba分词的实例:
import jieba
text = "我正在学习自然语言处理"
tokens = jieba.lcut(text)
print("中文分词结果:", tokens)
输出如下:
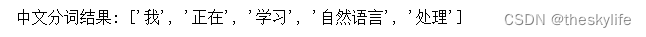
在这个例子中,我们使用jieba分词库对中文文本进行了分词操作,得到了每个词语的列表。
3.2 词性标注
词性标注是为分词结果中的每个词语赋予其对应的词性,例如名词、动词、形容词等。词性标注对于理解文本的语法结构和语义信息非常重要。以下是使用Spacy库进行词性标注的示例:
import spacy
# 下载Spacy的英语模型
!python -m spacy download en_core_web_sm
nlp = spacy.load('en_core_web_sm')
doc = nlp("Natural Language Processing is fascinating!")
print("Spacy POS Tagging:")
for token in doc:
print(token.text, token.pos_)
运行上述代码后,截图如下:

在这个例子中,我们使用Spacy加载了英语模型,并对给定的文本进行了词性标注。结果包括了每个词语及其对应的词性。
同样,我们也可以对中文进行标注,此处分别选用spacy和jieba进行标注,以供参考:
import spacy
# 下载中文包
# !python -m spacy download en_core_web_sm
nlp = spacy.load('zh_core_web_sm')
doc = nlp("我正在学习自然语言处理")
print("使用spacy中文词性标注:")
for token in doc:
print(token.text, token.pos_)
# jieba分词
import jieba.posseg as pseg
text = "我正在学习自然语言处理"
words = pseg.cut(text)
print("\n使用jieba中文词性标注:")
for word, pos in words:
print(word, pos)
运行上述代码后,得到下面的输出:

从上述例子中,我们可以看到进行中文分词的结果不太一致,这是因为每个包对于词性的标注情况不同造成的,在实际应用时,可以根据自己选择来使用。
3.3 命名实体识别
命名实体识别(NER)是识别文本中具有特定意义的命名实体,如人名、地名、组织机构等。NER对于从文本中提取关键信息非常有帮助。以下是使用Spacy进行命名实体识别的示例:
import spacy
# 下载Spacy的英语模型
# !python -m spacy download en_core_web_sm
nlp = spacy.load('en_core_web_sm')
doc = nlp("T am from America!")
print("Spacy Named Entity Recognition:")
for ent in doc.ents:
print(ent.text, ent.label_)
运行上述代码后,结果如下:

在这个例子中,我们使用Spacy对给定的文本进行了命名实体识别。结果包含了识别出的命名实体及其对应的类别。中文的实现方法极为类似,这里就不做详细的介绍。
写在最后
通过本篇博客,我们深入了解了NLP的基本概念,并介绍了在Python中常用的NLP库。在未来的学习中,我们将深入更高级的主题,如情感分析、文本分类等,为深度挖掘文本数据提供坚实的基础。让我们继续探索自然语言处理的更多奥秘,助力数据分析和挖掘的深入应用。