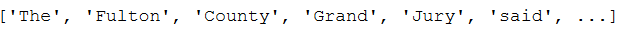大家好,今天跟大家介绍一下自然语言处理的基础的一些操作。
- Tokenize
- 词性标注
- 命名实体识别
- nltk频率统计
- 下载语料库
一、Tokenize
把句子分成有意义的小部件
import nltk
sentence = 'The imperial Palace is located in Bei Jing!'
tokens = nltk.word_tokenize(sentence)
print(tokens)
#运行结果如下:
#['The', 'imperial', 'Palace', 'is', 'located', 'in', 'Bei', 'Jing', '!']
二、词型归一化
1、词干提取
Stemming 词⼲提取:⼀般来说,就是把不影响词性的inflection的⼩尾巴砍掉如下例:
jumping 去ing = jump
maxium去ium=max
#词干提取
from nltk.stem.porter import PorterStemmer
porter_stemmer = PorterStemmer()
print(porter_stemmer.stem('running'))
print(porter_stemmer.stem('jumping'))
print(porter_stemmer.stem('walked'))
print(porter_stemmer.stem('reputation'))
print(porter_stemmer.stem('maxium'))
##运行结果:
#run
#jump
#walk
#reput
#maxium
2、词形归⼀
Lemmatization 词形归⼀:把各种类型的词的变形,都归为⼀个形式,如下例:
from nltk.stem import WordNetLemmatizer
wordnet_lemmatizer = WordNetLemmatizer()
print(wordnet_lemmatizer.lemmatize('dogs'))
print(wordnet_lemmatizer.lemmatize('churches'))
print(wordnet_lemmatizer.lemmatize('aardwolves'))
print(wordnet_lemmatizer.lemmatize('abaci'))
print(wordnet_lemmatizer.lemmatize('hardrock'))
#运行结果:
#dog
#church
#aardwolf
#abacus
#hardrock
没有pos tag,,默认是nn(名词)
3、词性标注
如下例:
import nltk
sentence = 'The imperial Palace is located in Bei Jing!'
tokens = nltk.word_tokenize(sentence)
print(tokens)
#词性标注
tagged = nltk.pos_tag(tokens)
print(tagged)
#运行结果:
#[('The', 'DT'), ('imperial', 'JJ'), ('Palace', 'NNP'), ('is', 'VBZ'), ('located', 'VBN'), ('in', 'IN'), ('Bei', 'NNP'), ('Jing', 'NNP'), ('!', '.')]
词性关系表如下:

也可以手动,如下:
print(wordnet_lemmatizer.lemmatize('is', pos='v'))
print(wordnet_lemmatizer.lemmatize('are', pos='v'))
#运行结果
#be
#be
三、命名实体的识别
命名实体识别是定位文档中的专有名词或命名实体的过程,而且这些不同的命名实体被分成了不同的类别,如:人名,地名,机构名等。
2008年定义的命名实体标签集有12个,描述如下:

NER的关键是信息提取,通过存储元组(实体,关系,实体)来实现信息提取,就可以抽取到实体。
可以使用斯坦福标注器来实现NER。
如果命名实体存在,就用NE标记来标注。
#下载nltk.download('maxent_ne_chunker'),如果之前已经有这个类就不用了,倘若报错需要下载就下载。
import nltk
sentence = 'The imperial Palace is located in BeiJing!'
#命名实体识别
entities = nltk.chunk.ne_chunk(tagged)
print(entities)
结果如下:

四、nltk频率统计
import nltk
from nltk import FreqDist
# 首先自己先写个词库
corpus = 'The Imperial Palace is located in BeiJing' \
'The Imperial Palace is very famous in BeiJing ' \
'The Imperial Palace become a symbol of BeiJing '
# tokenize⼀下
tokens = nltk.word_tokenize(corpus)
print(tokens)
结果:

# 其次借⽤NLTK的FreqDist统计⼀下⽂字出现的频率
fdist = FreqDist(tokens)
# 它就类似于⼀个Dict
# 带上某个单词, 可以看到它在整个⽂章中出现的次数
print(fdist.most_common(50))
for k,v in fdist.items():
print(k,v)
结果:

# 好, 此刻, 我们可以把最常⽤的50个单词拿出来
standard_freq_vector = fdist.most_common(50)
size = len(standard_freq_vector)
print(standard_freq_vector)
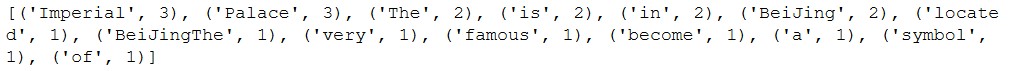
def position_lookup(v):
res = {}
counter = 0
for word in v:
res[word[0]] = counter
counter += 1
return res
# 把标准的单词位置记录下来
standard_position_dict = position_lookup(standard_freq_vector)
print(standard_position_dict)
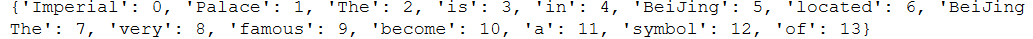
sentence = 'The Imperial Palace is so beautiful '
# 先新建⼀个跟我们的标准vector同样⼤⼩的向量
freq_vector = [0] * size
# 简单的Preprocessing
tokens = nltk.word_tokenize(sentence)
# 对于这个新句⼦⾥的每⼀个单词
for word in tokens:
try:
# 如果在我们的词库⾥出现过
# 那么就在"标准位置"上+1
freq_vector[standard_position_dict[word]] += 1
except KeyError:
# 如果是个新词
# 就pass掉
continue
print(freq_vector)
结果:
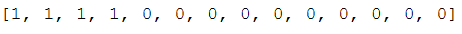
五、下载语料库:
import nltk
nltk.download('brown')
from nltk.corpus import brown
brown.words()