欢迎加入学习交流QQ群:657341423
自然语言处理是人工智能的类别之一。自然语言处理主要有那些功能?我们以百度AI为例
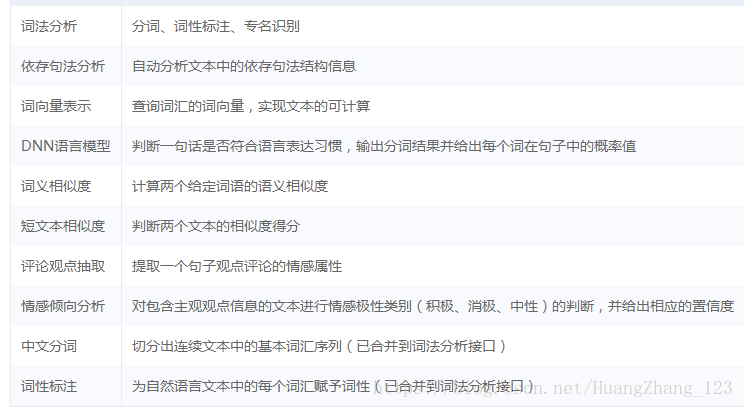
从上述的例子可以看到,自然语言处理最基本的功能是词法分析,词法分析的功能主要有:
- 分词分句
- 词语标注
- 词法时态(适用于英文词语)
- 关键词提前(词干提取)
由于英文和中文在文化上存在巨大的差异,因此Python处理英文和中文需要使用不同的模块,中文处理推荐使用jieba模块,英文处理推荐使用nltk模块。模块安装方法可自行搜索相关资料。
英文处理
import nltk
f = open('aa.txt','r',encoding='utf-8')
text = f.read()
f.close()
----------
# sent_tokenize 文本分句处理,text是一个英文句子或文章
value = nltk.sent_tokenize(text)
print(value)
# word_tokenize 分词处理,分词不支持中文
for i in value:
words = nltk.word_tokenize(text=i)
print(words)
----------
# pos_tag 词性标注,pos_tag以一组词为单位,words是列表组成的词语列表
words = ['My','name','is','Lucy']
tags = nltk.pos_tag(words)
print(tags)
----------
# 时态,过去词,进行时等
# 词语列表的时态复原,如果单词是全变形的无法识别
from nltk.stem import PorterStemmer
data = nltk.word_tokenize(text="worked presumably goes play,playing,played",language="english")
ps = PorterStemmer()
for w in data:
print(w,":",ps.stem(word=w))
# 单个词语的时态复原,如果单词是全变形的无法识别
from nltk.stem import SnowballStemmer
snowball_stemmer = SnowballStemmer('english')
a = snowball_stemmer.stem('plays')
print(a)
# 复数复原,如果单词是全变形的无法识别
from nltk.stem import WordNetLemmatizer
wordnet_lemmatizer = WordNetLemmatizer()
a = wordnet_lemmatizer.lemmatize('leaves')
print(a)
----------
# 词干提取,提前每个单词的关键词,然后可进行统计,得出词频
from nltk.stem.porter import PorterStemmer
porter = PorterStemmer()
a = porter.stem('pets insurance')
print(a)
----------
from nltk.corpus import wordnet
word = "good"
# 返回一个单词的同义词和反义词列表
def Word_synonyms_and_antonyms(word):
synonyms = []
antonyms = []
list_good = wordnet.synsets(word)
for syn in list_good:
# 获取同义词
for l in syn.lemmas():
synonyms.append(l.name())
# 获取反义词
if l.antonyms():
antonyms.append(l.antonyms()[0].name())
return (set(synonyms), set(antonyms))
# 返回一个单词的同义词列表
def Word_synonyms(word):
list_synonyms_and_antonyms = Word_synonyms_and_antonyms(word)
return list_synonyms_and_antonyms[0]
# 返回一个单词的反义词列表
def Word_antonyms(word):
list_synonyms_and_antonyms = Word_synonyms_and_antonyms(word)
return list_synonyms_and_antonyms[1]
print(Word_synonyms(word))
print(Word_antonyms(word))
----------
# 造句
print(wordnet.synset('name.n.01').examples())
# 词义解释
print(wordnet.synset('name.n.01').definition())
----------
from nltk.corpus import wordnet
# 词义相似度.'go.v.01'的go为词语,v为动词
# w1 = wordnet.synset('fulfil.v.01')
# w2 = wordnet.synset('finish.v.01')
# 'hello.n.01'的n为名词
w1 = wordnet.synset('hello.n.01')
w2 = wordnet.synset('hi.n.01')
# 基于路径的方法
print(w1.wup_similarity(w2))# Wu-Palmer 提出的最短路径
print(w1.path_similarity(w2))# 词在词典层次结构中的最短路径
print(w1.lch_similarity(w2))# Leacock Chodorow 最短路径加上类别信息
# 基于互信息的方法
from nltk.corpus import genesis
# 从语料库加载信息内容
# brown_ic = wordnet_ic.ic('ic-brown.dat')
# nltk自带的语料库创建信息内容词典
genesis_ic = wordnet.ic(genesis,False,0.0)
print(w1.res_similarity(w2,genesis_ic))
print(w1.jcn_similarity(w2,genesis_ic))
print(w1.lin_similarity(w2,genesis_ic))由于上述的方法是建立在语料库中,有时候一些不被记录的单词可能无法识别或标注。这时候需要自定义词性标注器,词性标注器的类型有几种,具体教程可以看——>自定义词性标注器
中文处理
import jieba
import jieba.analyse
f = open('aa.txt','r',encoding='utf-8')
text = f.read()
f.close()
----------
# 分词
seg_list = jieba.cut(text, cut_all=True)
print("Full Mode: " + "/ ".join(seg_list)) # 全模式
seg_list = jieba.cut(text, cut_all=False)
print("Default Mode: " + "/ ".join(seg_list)) # 精确模式
seg_list = jieba.cut_for_search(text) # 搜索引擎模式
print(", ".join(seg_list))
----------
# 关键字提取
# 基于TF-IDF算法的关键词抽取
# sentence 为待提取的文本
# topK 为返回几个 TF/IDF 权重最大的关键词,默认值为 20
# withWeight 为是否一并返回关键词权重值,默认值为 False
# allowPOS 仅包括指定词性的词,默认值为空,即不筛选
keywords = jieba.analyse.extract_tags(sentence=text, topK=20, withWeight=True, allowPOS=('n','nr','ns'))
# 基于TextRank算法的关键词抽取
# keywords = jieba.analyse.textrank(text, topK=20, withWeight=True, allowPOS=('n','nr','ns'))
for item in keywords:
print(item[0],item[1])
----------
# 词语标注
import jieba.posseg
# 新建自定义分词器,tokenizer 参数可指定内部使用的 jieba.Tokenizer 分词器。jieba.posseg.dt 为默认词性标注分词器。
posseg = jieba.posseg.POSTokenizer(tokenizer=None)
words = posseg.cut(text)
for word, flag in words:
print('%s %s' % (word, flag))jieba分词也是基于语料库,我们可以对原有的语料库添加词语,或者导入自定义的语料文件,如下所示:
# 对原有的语料库添加词语
jieba.add_word(word, freq=None, tag=None)
# 导入语料文件
jieba.load_userdict('disney.txt')语料文件格式如下:每行分三个部分(用空格隔开),词语 词频(可省) 词性(可省)。ns是词语标记,词语和标注之间用空格隔开,txt文件格式为uft-8

jieba更多教程——>jieba教程