一说到爬虫,大家第一时间想到的便是Python,但是实际上,R也能实现爬虫的功能,并且在某些特定的结构中,R的效率非常高,下面就来介绍一个关于R语言实现BeautifulSoup的功能的例子。
同样的,我们以天天基金网的QDII 基金净值为例子(详情可以见我上一篇文章点击打开链接),为了爬取其中symbol以及净值数据,R可以通过短短几行代码实现:
install.packages('XML') #安装包
library(XML) #读取包
url<- 'http://fund.eastmoney.com/QDII_jzzzl.html#os_0;isall_0;ft_;pt_6' #网址
tables<- readHTMLTable(url,which=3) #读取table,which=3意思是读取网页结构里面第三个table
fund<-tables[,c(4,8)] #获取需要的数据,第三列为symbol,第八列为净值
colnames(fund)<-c('symbol','NAV') #命名最后结果为:
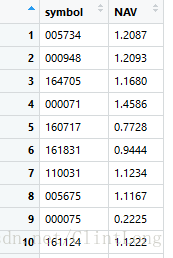
可以发现R爬取网页非常简洁,且能达到与python一样的效果,难点在于1.which=3需要自己取网页代码源里去找(你不找其实也无所谓,就是会把所有table结构都抓下来);2.这个function只能抓table结构的数据,同理有一个readHTMLList function,具体功能就不介绍了
在功能的完整性上,PYTHON绝对优于R,毕竟R基本上只服务于统计与数据分析,这篇文章提供一个思路,为只使用R的人来实现数据获取提供可能性。