版权声明:未经允许,禁止转载 https://blog.csdn.net/weixin_43216017/article/details/87880586
在前一篇文章中,我们介绍了bagging算法,本文我们将着重介绍其R语言的实现。
使用adabag包中的bagging函数
数据简介
本文数据选择了红酒质量分类数据集,这是一个很经典的数据集,原数据集中“质量”这一变量取值有{3,4,5,6,7,8}。为了实现二分类问题,我们添加一个变量“等级”,并将“质量”为{3,4,5}的观测划分在等级0中,“质量”为{6,7,8}的观测划分在等级1中。
因变量:等级
自变量:非挥发性酸性、挥发性酸性、柠檬酸、剩余糖分、氯化物、游离二氧化硫、二氧化硫总量、浓度、pH、硫酸盐、酒精
####数据集的引入及划分
library(openxlsx)
wine = read.xlsx("C:/Users/Mr.Reliable/Desktop/classification/winequality-red.xlsx")
#将数据集分为训练集和测试集,比例为7:3
train_sub = sample(nrow(wine),7/10*nrow(wine))
train_data = wine[train_sub,]
test_data = wine[-train_sub,]
bagging算法实现
R包下载
install.packages("adabag")
这个包需要依赖很多其他的包,下载的时间相对较长
实现bagging算法
bagging(formula, data, mfinal = 100, control, par=FALSE,…)
| 参数 | 意义 |
|---|---|
| formula | ~ ,确定自变量和因变量 |
| data | 所使用的数据集 |
| mfinal | 表示迭代的次数,默认100 |
| par | 如果是True,在跑模型的同时会进行交叉验证;如果是False(默认),则不会进行 |
library(adabag)
#数据预处理
train_data$等级 = factor(train_data$等级)
test_data$等级 = factor(test_data$等级)
#bagging算法
wine_bagging <- bagging(等级 ~ 非挥发性酸性 + 挥发性酸性 + 柠檬酸 +
剩余糖分 + 氯化物 + 游离二氧化硫+二氧化硫总量+
浓度+pH+硫酸盐+酒精,
data = train_data,mfinal=100 )
这样我们就实现了bagging算法
ROC曲线和AUC值
#测试集
pre_decisiontree_bag <- as.numeric(predict(wine_bagging,newdata = test_data)$class)
#将测试集计算所得概率与观测本身取值整合到一起
obs_p_decision_bag= data.frame(prob=pre_decisiontree_bag,obs=test_data$等级)
#输出混淆矩阵
table(test_data$等级,pre_decisiontree_bag,dnn=c("真实值","预测值"))
#绘制ROC曲线
decisiontree_roc_bag <- roc(test_data$等级,pre_decisiontree_bag)
plot(decisiontree_roc_bag, print.auc=TRUE, auc.polygon=TRUE, grid=c(0.1, 0.2),grid.col=c("green", "red"), max.auc.polygon=TRUE,auc.polygon.col="skyblue", print.thres=TRUE,main='Bagging算法ROC曲线')
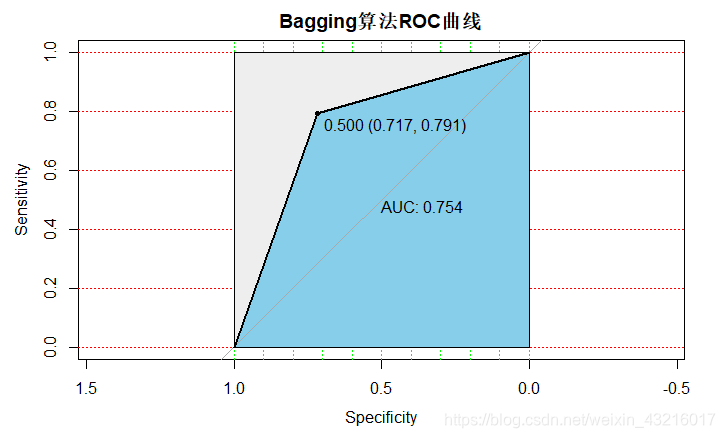
如果迭代次数为100:AUC值为0.754
更改mfinal
如果迭代次数设置为500:AUC值为0.761
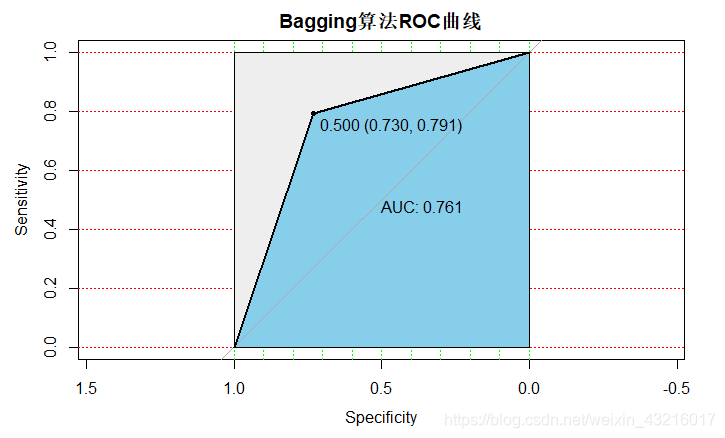
从AUC值来看,迭代次数越多,效果越好;但是另一方面,迭代次数越多,速度越慢。