运行平台:windows
Python版本: Python3.x
备注:Xpath练习
一、依赖库的安装
在进行本章之前,请确保您已经安装了xpath库。
pip3 install xpath
或者
conda install xpath
二、抓取分析
目标站点:(300篇精选中日文对照阅读)
这是一个静态网页,内容完全存放在html文件中,同时基本没有反爬虫策略,容易爬取。
适合我们进行Xpath工具的练习使用。
(一)首先观察网址url。


网页的分页映射在list_?这里。
(二)爬取目的:获取每篇文章的标题、发布时间、与超链接地址。
打开开发者工具,定位每个模块的信息。
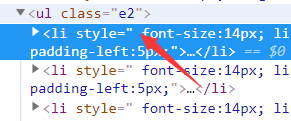
每条文章帖子都是一个li标签,而它们的父节点是class="e2"的ul标签。
在页面源代码中搜索class="e2"的标签。

可以发现这里只有这样一个class="e2"的标签,这很利于我们进行定位。
当我们找到这个ul标签后,便可以遍历它下面的子节点li,然后通过Xpath匹配我们需要的内容。
三、代码讲解
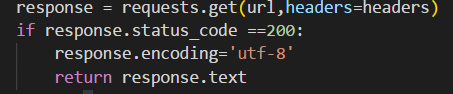
当响应码返回值为200时,代表连接成功,然后返回页面的源代码。
这里我们需要给页面文本编码为utf-8,不然其返回的源代码中一些语言文字是乱码。
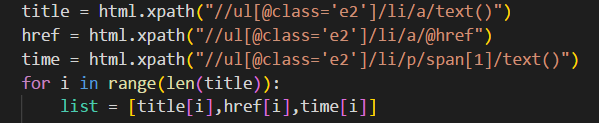
这些便是Xpath的匹配规则。
html.xpath("//ul[@class='e2']/li/a/text()")
返回class='e2’的ul节点下li标签下a标签里的文本内容。【这里的class属性必须唯一】
html.xpath("//ul[@class='e2']/li/a/@href")
返回class='e2’的ul节点下li标签下a标签里的超链接内容。
html.xpath("//ul[@class='e2']/li/p/span[1]/text()")
返回class='e2’的ul节点下li标签下p标签下的第一个span标签里的文本内容。【下标从1开始计数】

内容解析完成存储在列表后,然后写入csv文档。
四、关于csv文件
当爬取成功后,打开csv文件,如下图所示

我们需要对其更改一下格式,方便使用或者观看。
新建一个csv文件或者xlsx文件。
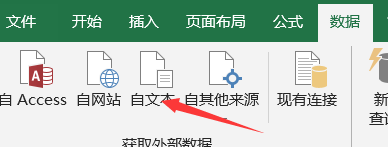
选择我们刚才程序生成的csv文档。

选择逗号分隔符。
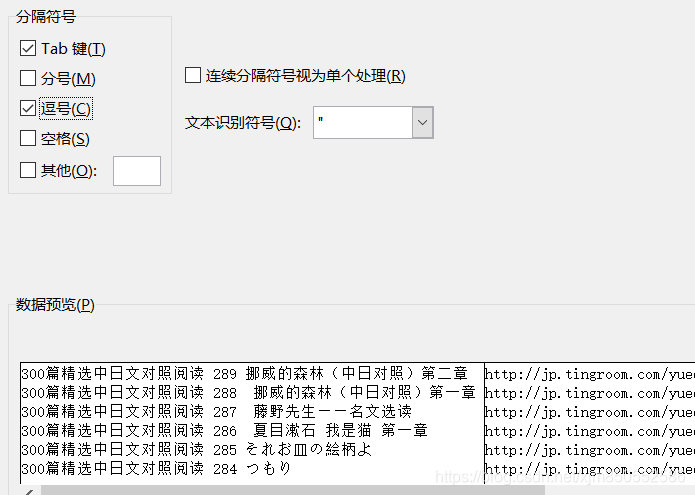
完成后如下图所示。

四、完整源码
#coding:utf-8
#author:Ericam_
#description:(练习xpath使用)
import requests
from lxml import etree
from requests.exceptions import RequestException
import csv
values=[]
def get_page(url):
try:
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.62 Safari/537.36'}
response = requests.get(url,headers=headers)
if response.status_code ==200:
response.encoding='utf-8'
return response.text
return 0
except RequestException:
return 0
def spider(offset):
url = "http://jp.tingroom.com/yuedu/yd300p/list_"+str(offset)+".html"
text = get_page(url)
parse_one_page(text)
write_to_files()
def parse_one_page(text):
global values
html = etree.HTML(text)
title = html.xpath("//ul[@class='e2']/li/a/text()")
href = html.xpath("//ul[@class='e2']/li/a/@href")
time = html.xpath("//ul[@class='e2']/li/p/span[1]/text()")
for i in range(len(title)):
list = [title[i],href[i],time[i]]
values.append(list)
def write_to_files():
with open("JReading.csv","a+",newline='',encoding='utf8')as csvfile:
writer = csv.writer(csvfile)
writer.writerows(values)
if __name__=='__main__':
for i in range(1,15):
spider(i)
print("第"+str(i)+"页爬取结束")