分类
什么是分类?举个例子,银行贷款员需要分析数据,以便搞清楚哪些是贷款申请者是值得信赖的。通信公司也希望能分清楚哪些客户容易接受某一套餐,从而定向营销。数据分类一般又包括学习阶段(构建分类器)和分类阶段(使用模型预测给定数据的类标号)。
决策树分类器
决策树分类算法是数据挖掘、机器学习中最常使用的一种分类算法。决策树(decision tree)是一种类似于流程图的树结构,其中,每个内部节点的分支代表了数据的某一特定属性取不同值的情况,而每个叶节点存放一个类标号。一个例子如下,其表示了不同情况下是否出去玩:
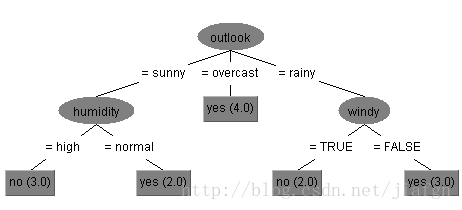
可以看出决策树非常直观,容易被人理解。决策树的学习和分类也比较简单快速。那么如何构建决策树呢?J.Ross Quinlan 提出了迭代的分裂器(Iterative Dichotomiser,ID3)。ID3采用贪心方法,自顶向下递归分治构造分类器。它的核心是分裂准则(splitting criterion)即怎样的属性比较适合做分裂节点。然后自定向下,从根节点开始,一步一步找最好的分裂属性。
ID3的分裂准则就是信息增益,它基于的香农的信息论。
熵 :
其中
如果现在我们用属性A将它分为几个分区,
它的熵:
而分类之后的信息增益:
所以每一次我们只要找到信息增益最大的属性作为分裂结点即可。
可是ID3采用的信息增益有以缺陷,它会倾向于选择属性值较多的属性。举个例子,如果要分类电话用户,而用他们的电话号码做属性,它的信息增益无疑是最大的,可是却没有用处。基于此,又有人提出了C4.5算法,它的分裂准则是增益率。
它使用分裂信息(split information)值将信息增益规范化。分裂信息定义如下:
然后最终的增益率:
下面我将给出Java实现的算法,由于代码量较多,我将上传资源,点击下载